
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have discussed GitLab's Production Architecture to understand how a large company like GitLab which supports millions of developers handle and scale their infrastructure.
The Production Architecture will be similar for GitHub.
Table of Contents
- Prodcution Architecture
- Cluster Configuration
- Monitoring and Logging
- Cluster Upgrades
- Application Upgrades
- Database Architecture
- Network Architecture
Let us get started with Scaling large systems: GitLab Production Architecture.
Production Architecture
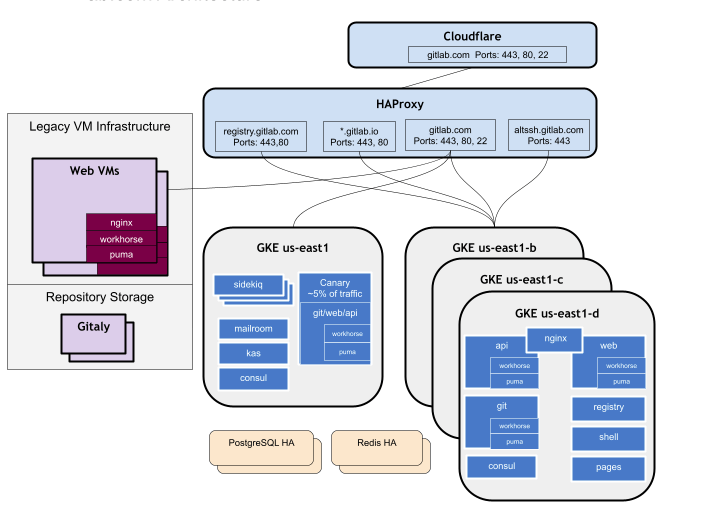
Gitlab makes use of Kubernetes , the components and services of gitlab are neing migrated to kubernetes. Gitlab makes use of google cloud engine to run their infrastructure , the kubernetes clusters are provisoned in GCP kubernetes engine.
Initally gitlab made use of virtual machines to run their workloads however there were a couple of issues with virtual machines
Disadvantages of Virtual Machines
- Serving customers was not fast enough as the infrastructure is static and as workloads increase the VMs become slower. Traditonal Vms were unable to keep up with the demand.
- Infrastruture costs were high even if the demand was low because the infrastructure size was same in both cases which led to increased operation expenses.
- Deployment speed was slow as entire VMs had to be upgraded to spin up new version of the application. This resulted in some Vms downtime in gitlab.
These issues led the gilab team to migrate to kubernetes.
Advantages of using Kubernetes by GitLab
- Reduced Operational Costs
- Increase in efficiency of day to day operations
- Decreased number of nodes to manage the workloads
- Better release speed and deployment
- Official Helm charts improved
Currently all new services of Gitlab are deployed and managed by kubernetes.
How does Kubernetes work
Kubernetes is a container orchestration platform.It is a open source project which provides a lot of flexibilty in managing and scaling containerized applications in clusters.
As containers became more popular there was requirement for a framework or technology which would ease the process of managing these containers and kubernetes fit that requirement. It was introduced by google to adderess this specific problem.
To work with kubernetes a cluster of nodes is required under which our applications are deployed either manually or through pipelines.
Master Node
Kubernetes runs in a cluster and this cluster is formed using a group of instances. Some of these instances are assigned the role of master node which governs over the other nodes and ensures that they are properly running. The contain the most important parts of kubernetes.
Worker Nodes
These are nodes which hold the containerised applications. They frequently communicate with the master nodes receiving instructions , providing them with their demands etc. If a worker node goes down a new worker node is setup to replace it.
Pods
These are the most atomic units of kubernetes in which our applications run. They can be defined in a yaml file and deployed in a cluster.
Deployments
Deployments provide updates to pods . Generally we define deployments which in turn is responsible for managing the pods. Using deployments we can scale up or scale down pods , perform rolling updates , delete them etc.
Service
Services allow us to expose the applications running in the pods.
Namespace
Namespaces can be considered similar to different virtual environments to seperate the applications running in the cluster.
Kubernetes provides an easy way to deploy applications , perform updates , scaling of applications and rolling them back when needed.
Cluster Configuration
There are two environments within the organisation staging and production. Gitlab makes use of four kubernetes clusters for production and similarly configured clusters for staging. The clusters belong to the three GCP availability zones and one in regional zone.
The reason for having multiple zones is because
- Workloads are isolated
- Maintainence and upgrades to cluster does not depend or affect other clusters. Each cluster is independent from each other.
- Ensures that network traffic is not sent across zones due to high bandwidth.
Cloudflare is used to receive all inbound web,git ,http and ssh requests utilising HaProxy as an origin. Haproxy routes the requests between the new clusters and traditional VMs.
Monitoring and Logging
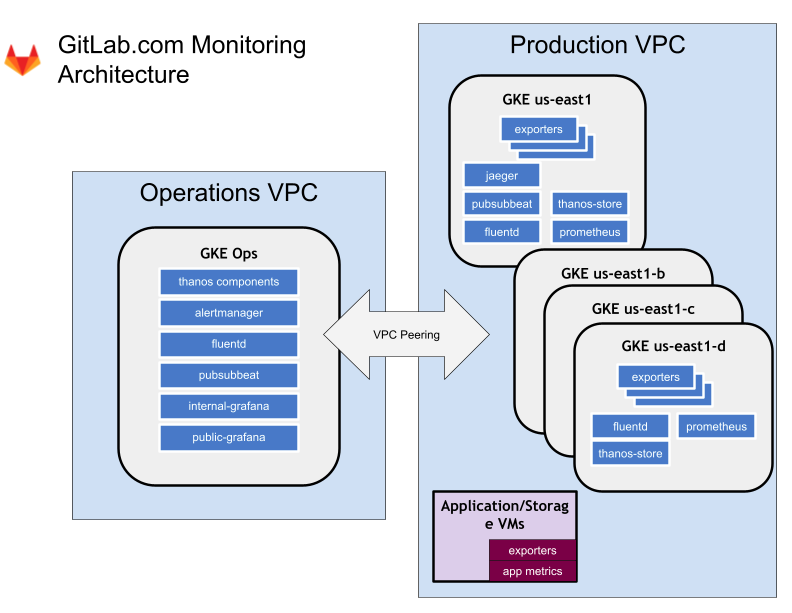
Monitoring of the application is done by running the monitoring application in the same cluster as the application. The monitroing metrics are aggregated using Thanos.
Gitlab also uses Prometheus , every cluster has prometheus deployed in the monitoring namespace.
For logging fluentd is used which forwards all logs to elasticsearch index. The namespace used for this is logging.
Cluster Upgrades
Gitlab uses helm charts to perform upgrades in the cluster. Changes are made to the charts yaml configuration files and once the changes are approved the pipeline that applies the required changes run first on the staging environment to ensure it is appropriate.
Application Upgrades
Upadates to the application are applied in both cluster and VMs to ensure that the same version is present in both cases. A CI pipeline deploys the updates to virtual machines which also triggers a pipeline for the kubernetes cluster which updates the image in the cluster. All this occurs in the staging environment in the first.
Gitlab uses its own self maintained container image registry to store the application container images. This is done to ensure that if neecessary the applications can be rolled back by using any previous images.
DataBase Architecture
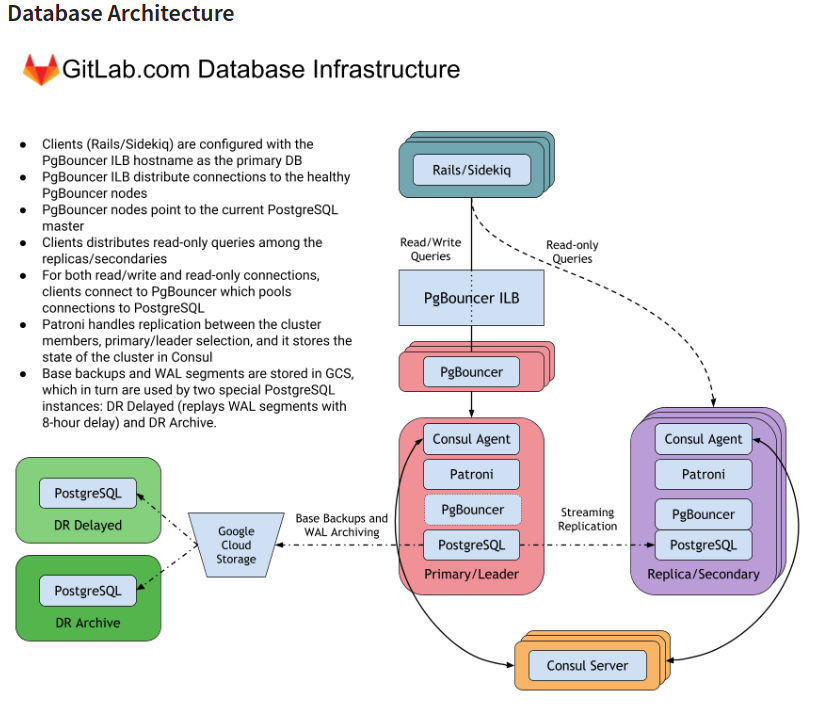
The various components of the database architecture and the usecases are explained below. GitLab mainly uses postgresql to store the data.
PgBouncer
For databases Gitlab uses postgresql , for read and write operations the clients connnects to PgBouncer which pools and forwards the requests to postgresql.
Patroni
Patroni handles replication of data between the cluster members and stores the state of the cluster in consul.
Consul
Consul is a Hashicorp based tool used for discovering and configuring different services the infrastructure. Consul can be used to maintain the services present in the distributed systems.
Google Cloud Storage
Special PostGresQl instances are used in google cloud storage to store base backups and WAL segments.
NetWork Architecture
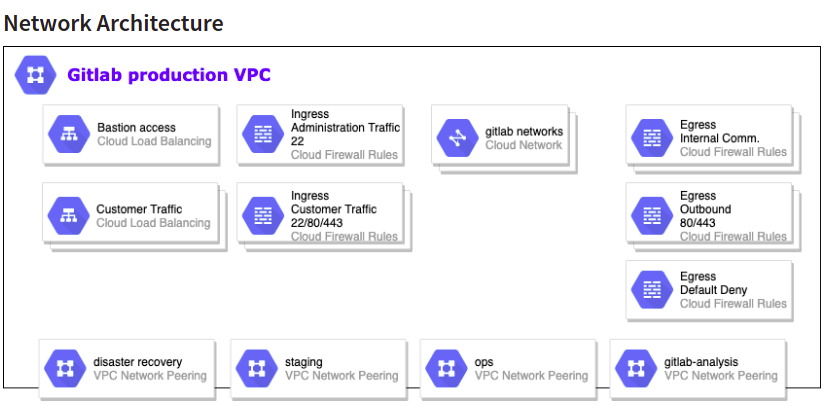
The network architecture of gilab contains network class for each architecture of network class.
The clusters have ingress configured within them which routes external traffic to required services within the cluster. The monitoring service is within this network in which InfluxDB and Prometheus data is allowed to flow to populate the metrics systems.
The DNS system used by gitlab is CloudFlare and route53. Required ACLs and rules are setup to ensure only those required have authorization to access the parts of the network.
With this article at OpenGenus, you must have a good idea of how large applications like GitLab scales itself.