
In this article, we have explained the System Design of Spotify, a leading audio streaming platform in depth.
Contents
- Introduction
- Spotify Requirements
- Software Architectures
- System Design of Spotify
- Conclusion
1. Introduction
This article covers how apps like Spotify are designed to scale to large userbases.
Section 2 defines the requirements Spotify would need to fulfill for its userbase.
Section 3 discusses modern day architectures to implement large scale applications. We discuss two common architectures, monolithic and microservices.
Section 4 will provide an overview of the implementation of Spotify using its current techstack, building off concepts introduced in sections 2 and 3.
2. Spotify Requirements
Spotify is a large application, but it's core functionality is to be an MP3 player that has access to one of the largest curated libraries of music and podcasts. This means it must be highly available in an international setting for millions of users.
Spotify needs to fulfill the following user requirements:
- Account creation and AuthN/Z (Authentication and Authorization)
- Audio processing
- Recommendations
- Fast searching
- Low latency Streaming
For system requirements, Spotify must expect to handle:
- Billions of API requests internationally
- Store several hundred terrabytes of +100 million audio tracks.
- Store several petabytes of metadata from +500 million users.
For data alone, Spotify needs to store both user data and data related to business, and this can be an infinitely increasing amount, with current data estimates around 5 petabytes.
3. Software Architectures
A software architecture refers to the blueprint/approach used to build software. Different architectures rely on different standards for building, integrating, and deploying components. There are two common architectures, Monolithic Architectures and Microservices Architectures, with microservices being the most recent architecture.
Monolithic
This is the industry standard of software development, where software is designed to be a single executable unit. This architecture is ideal for applications where requirements are fixed.
In a monolithic architecture, we divide an application into layers, with each layer providing specific functionality:
- Presentation Layer: This layer implements the application UI elements and client-side API requests. It is what the client sees and interacts with.
- Controller Layer: All software integrations through HTTP or other communication methods happen here.
- Service Layer: The business logic of the application is present in this layer.
- Database Access Layer: All the database accesses, including both SQL and NoSQL, of the applications, happens in this layer.
We often group layers together, with the Presentation Layer being called the frontend and Controller, Service, and Data Access Layer being grouped into the backend*. This simplifies software as communication between two parties. Any application can be described as a frontend (client) talking to a backend (server).
Dividing applications into these layers led to design patterns like MVC, MVVC, MVP, as well as frameworks that implement them like Spring for Java, .NET for C#, Qt for C++, Django for Python, and Node.js for JavaScript.
Microservices
Microservices builds off monolithic architectures. Instead of defining software as a single executable unit, it divides software into multiple executable units that interop with one another. Rather than having one complex client and one complex server communicating with one another, microservices split clients and servers into smaller units, with many simple clients communicating with many simple servers.
In even simpler terms, microservices splits a large application into many small applications.
The tradeoff between the two is summarized below:
- Monolithic Architecture: Complex Services, Simple Relationships. Better for apps with Fixed Requirements (like a Calculator)
- Microservices Architectures: Simple Services, Complex Relationships. Better for apps with Variable/Scaling Requirements (like a Social Media application)
Microservices borrows the exact same design patterns and layer methodology as Monolithic architectures, it only implements them with different tools.
Microservices works by integrating the following units:
- Frontend
- Backend
- Content Delivery Network
- Elastic Load Balancer
- API Gateway
- Circuit Breaker
- Cache
- Service Client
- Streaming Pipeline
- Services
- Databases
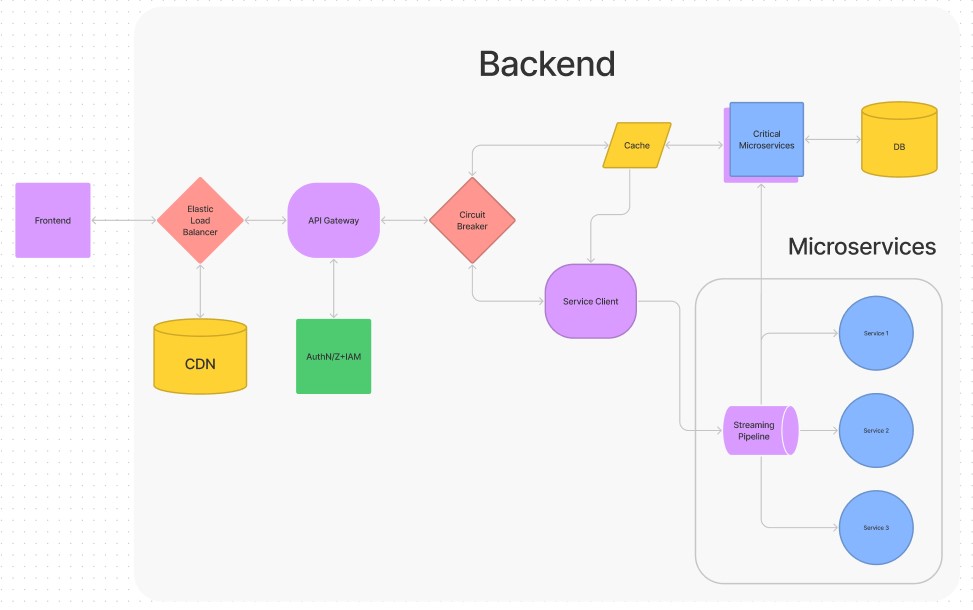
Frontend
The frontend is the graphical UI of an application or site that the client interacts with. Webpage frontends have the option being prerendered on a server and sent to a browser (server-side rendering aka SSR) or rendered directly in a brower (client-side rendering aka CSR). Application frontends are usually downloaded (as seen with Desktop and Mobile applications). CSR is more commonplace as UI components can be dynamically rendered and updated with lower latencies. Many frontend UI frameworks exist with many being in JS, but CSR can also be done through other langauges like C#, C++, Java, and more using Web Assembly.
Backend
This is the main application, which handles integrations and APIs with a Controller Layer, business logic with a Service Layer, and data storage and access with a Data Access Layer.
Third party applications/libraries are often used to implement the components in each layer.
Content Delivery Networks (Service Layer)
A CDN or Content Delivery Network is used to solve latency issues when a client loads requested content on a device. A CDN stores static files to be quickly delivered to clients. It is placed on the network edge for services that prioritize delivering content to users.
Load Balancers (Controller Layer)
A load balancer is a specialized server optimized for routing that quickly distributes incoming requests across multiple targets. It is meant to evenly distribute requests across a network's nodes to reduce performance issues. Load balancers can process millions of requests and usually redirects requests to one of many secure API gateways.
API Gateways (Controller Layer)
An API gateway is a server combined with several dynamic route filters that can filter and send batch requests to a specific microservice or service client. It reduces the number of round trips for data to make between services and can also handle functionality such as user authentication and SSL termination (where secure HTTPS connections are downgraded to HTTP connections for faster communication). An API gateway can also handle the same role as a load balancer, but API gateways handle fewer requests at a time versus a dedicated load balancer. For example, load balancers can route up to a million requests per second, while API gateways can only handle up to 10,000 requests per second. Large applications will have multiple API gateways that a load balancer can route to, and API gateways can be used to organize requests, such as requests from mobile devices, desktop devices, and browsers.
Circuit Breakers (Controller Layer)
A circuit breaker is a design pattern where the problems caused by latency from interservice communication can be avoided by switching to backup services in case a primary service fails. Hysterix is a Java library that adds fault and latency tolerance to microservices, acting as a circuit breaker. This is especially useful when using 3rd party microservices, as Hysterix can isolate endpoints and open ports to fallback services.
Service Clients (Controller Layer)
After data is sent from the API gateway and passes through a circuit breaker, it is received by a service client. A service client is a reverse-proxy HTTP server used as a microservice that allows other microservices to communicate with the API gateway.
Caches (Service Layer/Data Access Layer)
A cache is used to speed up responses when querying databases and warehouses, as the service client will first search the cache for the result of a recent response before posting an event on a streaming pipeline. The cache can be implemented with Memcached or Redis.
Streaming Pipeline (Service Layer)
A streaming pipeline is a piece of software that allows services to communicate with one another and process items in transit.
Services are usually hosted with their own IP addresses and endpoints. Using a REST API can enable services to communicate with one another, but it becomes too coupled as every service must have the address to every other service it wants to talk to. Pipelines are a design pattern that allow services to talk to one another without storing information about the sender like an address. Instead a pipeline is a public inbox, where all services can check and see if a message or task exists for them. The pipeline itself is referred to as a message broker.
Streaming pipelines can define the behavior of the message broker as either message- driven architecture or event-driven architecture. Message-driven architectures address a task for a select service to respond too, but any service can view it. Event-driven architectures simply post a task with no address and lets every service that views it decide whether to respond or not. Pipelines function off a publisher-subscriber model, where a service publishes messages or events to the pipeline, and other services can subscribe to the pipeline to see incoming messages and events.
Both Apache Kafka and RabbitMQ are streaming pipelines, but since Spotify relies on a lot of real-time processing and a high amount throughput for its search and recommendation engine, Kafka is the smarter choice to use as a streaming pipeline due to its event-based architecture.
Services (Any Layer)
Services are independent instances of an application, which can be from third parties or developed in-house. Using containerization, we can host these running applications on multiple machines, then use a streaming pipeline to allow them to talk to each other.
Pairing services and a streaming pipeline create the core part of the microservices architecture.
Databases (Data Access Layer)
A database is an application that can store and retrieve data. This software can be treated like any other service and is usually hosted on a separate server from the rest of the backend.
4. System Design of Spotify
Microservices is an architecture that is easy to scale and incrementally update over time. Because Spotify consistently faces changing user, system, and business requirements as user bases and monetization practices grow over time, microservices is the ideal architecture for it.
Spotify implements microservices using the following tech stack. Below we'll cover what each tool is used for and how they all integrate.
Spotify uses the following technologies for its core application:
Java - General Development Language
Spotify is language agnostic, but a large portion of its codebase is in Java. The reasons why this is the best option may vary, from improved tooling, better frameworks, libraries, and documentation, object-oriented nature, lower staffing requirements. Spotify can just as easily be coded in other languages as well.
NGINX - Elastic Load Balancer + API Gateway + Service Client
NGINX is an open-source webserver that can be configured to be a load balancer, API gateway, and or service client. A load balancer, API gateway, and service clients are all just servers optimized for different properties (speed, security, and load). NGINX provides these optimizations and the server itself with prebuilt versions in a NGINX Plus subscription. The open-source nature means Spotify can modify and use the server in an enterprise without worrying about usage fees in the future.
Hysterix - Java-based Circuit Breaker Library
Not explicitly stated to be used by Spotify but can be used to reduce failures and improve fault tolerance in any microservices architecture. If a different language was used, then a different library could be used.
PostgreSQL - SQL DB for storing user billing/subscription data
This is another Open-Source RDBMS, meaning the software can be custom modified to fit Spotify's needs without needing to worry about subscriptions. It might not be a better option to other open-source RDBMS like MariaDB and MySQL but was simply a choice during planning.
Bootstrap - CSS Framework for Frontend Webpage
While plain CSS can be used to style a frontend, Bootstrap provides many prestyled HTML components that can be used to build a UI with. Options like a JS Framework like React, Vue, and Angular could have also been used or a templating language like JavaFX.
Amazon S3 - Static File Storage storing licensed Spotify songs.
Spotify could purchase hundreds of hard drives to store the music it uses or outsource the hard work of setting up remote storage to Amazon and use their remote storage solution S3. S3 might be a good option due to its high availability and high fault tolerance when compared to other providers like Google Cloud and Azure.
Amazon CloudFront - CDN Provider for making S3 highly available in multiple regions (helps Spotify scale its services internationally).
If S3 can handle storage, CloudFront is a supporting tool to handle distribution of static content stored in S3 across the world. Now the Spotify app can access stored songs from any international client on its own private CDN hosted by CloudFront.
Kafka - Event-Driven Streaming Pipeline for fast microservice routing
Kafka is a very popular open-source streaming pipeline. Compared to options like REST or RabbitMQ, Kafka can handle millions of requests per second (compared to 10000 with Rabbit MQ) and has a Java SDK.
Cassandra - Fast Distributed NoSQL DB for storing user data
Apache Cassandra is an open-source distributed NoSQL DB that can be scaled on many remote servers. It allows Spotify to manage scaling datasets such as user metadata with ease. It's open-source nature also reduces costs, as options like Redis and MongoDB may not scale as easily or cost more to use in enterprise.
Hadoop - Distributed File System and Batch Computing of Historical Data
Apache Hadoop is an open-source set of tools for batch processing historical data and large-scale distributed file storage. This historical data can allow Spotify to analyze large amounts of metadata. It also has the benefits of being open source making the storage of business data less dependent on cloud providers.
Google Big Query - Cloud Based Data Warehouse for system analytics
Spotify outsources analysis of some of its data to Big Query. Big Query is a data warehouse with ML features for generating analytics and defining business requirements. Spotify might store user data here to identify trends and perform analyses that can inform business requirements in the future. Other cloud options like Amazon Redshift and Snowflake exist but may be more expensive to use.
Apache Storm - Distributed Real-Time Computation for Search and Recommendation engine results
While Hadoop handles batch processing, Apache Storm is for optimized for real-time analytics. Storm is open source as well, and extremely fast clocking in at over a million tuples processed per second per node. It can be used for real time analytics, online machine learning, continuous computation, distributed RPC, ETL and more.
Google Cloud Bigtable - Highly Available NoSQL Cloud-based DB storing song, playlist, artist, and podcast metadata
Google Big Query likely pulls data from Bigtable to form its data warehouse and make ETL easier to perform. So, the main reason for using Bigtable may be its interoperability with Google Big Query, but lower charges could be another reason as well.
During development, the Spotify team also used the following tools for Test Automation and DevOps during development:
Docker - App Containerization (Run Apps in Production-Ready Environments Remotely on any OS)
New Relic - Stack Monitoring and Security
Datadog - Stack Monitoring and Security
Percy - Automated Visual QA
Apache Cloudstack - IaaS
Testflight - Testing framework for iOS
Helios/Kubernetes - Container Orchestration (scales Docker Containers according to Load)
Note the above tools are the ones Spotify personally chose to use, either because they were cost and performance efficient, independent of third parties (open source), or met current staffing requirements.
These tools are integrated in the following dataflow diagram:
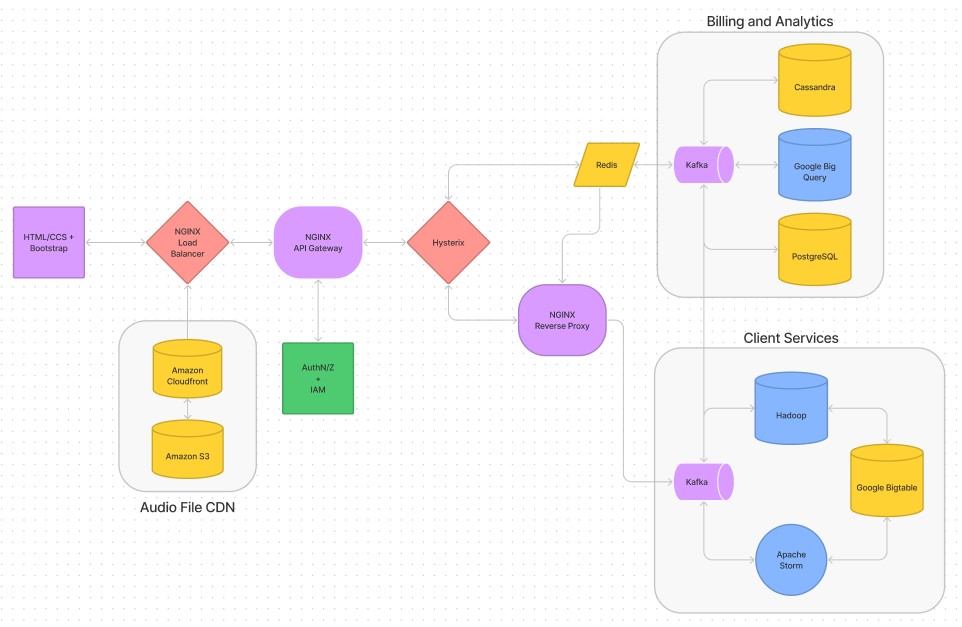
The diagram above shows that data flows from frontend to backend in the following steps.
- The client first interacts with the frontend (like searching a songs name).
- The frontend then sends this request to the NGINX load balancer which forwards the request to an NGINX API gateway that can check if the user is authenticated and decide which microservice network will handle it.
- The NGINX API gateway sends the request to an NGINX service client instance, with the Hysterix circuit breaker checking if a service client is down (redirecting to a different service client in case it is).
- The NGINX service client then either searches the Redis cache if the request stores a response to send back, if not it publishes the request to the Kafka pipeline.
- Like an inbox, every microservice subscribed to the Kafka pipeline can look at the published request.
- Microservices capable of responding back publish the response on the pipeline. This is where microservices can talk to other microservices. For example when searching, Google Bigtable might be queried by Apache Storm to generate search results to send back, with Apache Storm publishing the final search results to the pipeline.
- The service client reads the most recent responses on the pipeline, and pools together the responses to send back to the NGINX API gateway.
- The NGINX API gateway sends the response to the NGINX load balancer and eventually to the frontend, modifying it someway (in the application of searching, the front end renders the response, a set of search results.)
- At this point if the user takes another action like selecting a song, the process is repeated, with different services used. For example, playing a selected song sends a request to Spotify's CDN through a direct connection to the load balancer. This speeds up the process for a client to access audio.
Alternative Tools
Alternatives for the following tools are:
API Gateways/Load Balancers: AWS, Azure, Google Cloud, Zuul, Linkerd
Databases: Redis, MongoDB, Amazon Dynamo DB, Firestore, Couchbase
Caching: Redis, Memcached
Data Processing: Hadoop, Apache Spark, Apache Storm, Google Compute Cloud, AWS EC2
CDN Providers: Azure CDN, Cloudfare, AWS Cloudfront, BunnyCDN, CacheFly
Pipelines: AWS Kinesus, Apache Spark, Apache Storm, Kafka, RabbitMQ, RAITMQ, ActiveMQ
APIs: REST, JSON RPC, GraphQl, Web Sockets
Backend Frameworks/Tools: .NET, Spring, Node, Django, Laravel
Frontend Frameworks/Tools: ReactJS, Vue, Angular, Django, PHP, HTML/CSS, JavaFX, Blazor
7. Conclusion
Spotify is an extremely complex application, but the architecture it uses remains fundamentally the same for other content delivery applications. Microservices is an architecture that takes advantage of the benefits of modularity and loose coupling to offer the best end-user experience for millions of users.
With this article at OpenGenus, you must have the complete idea of System Design of Spotify.