
In my previous post, I wrote about data structures that could be used for text editors. And in this post, we will take a closer look at two of the data structures mentioned, in particular: two stack model and the split buffer.
To briefly reiterate the main points from the previous post, the core of a text editor relies on these essential functionalties: inserting, deleting, and viewing text. Based on the preferences you want your text editor to that will help you in which underlying data structures you would use. There is no best choice, but there are certainly better options depending on the text editor specifications.
Two Stack Model
In this data stucture, there are two stacks used hence the name two stack model. For the sake of portraying a difference, we will assume the stack will use a singly linked list as it's underlying data structure. The idea behind this data structure is to mimic editing lines rather than a huge document. The two stacks are used to represent the contents where the cursor is. One stack will represent all the contents left of the cursor while the other stack will represent all the contents right of the cursor.
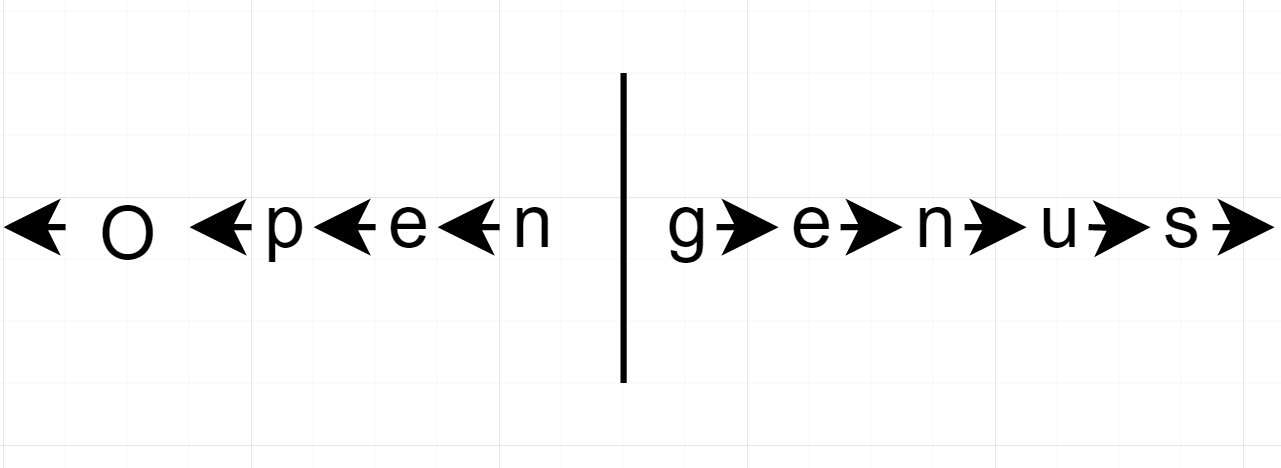
The cursor is the black verticle line while the left stack is in reverse order while the right stack in the normal order. The two stack model will mimic a cursor movement by shifting the contents over their popping the stack and pushing it onto the other.
An important thing to take note is that we create our own stack using a linked list to allow more features without losing contents in the stacks such as viewing the entire input.
Interstingly enough, inserting, deleting, and viewing a character are all O(1) time complexity but inserting, deleting, and viewing a character at another location is O(N) where N is the amount of characters the cursor has to move through. Often times people will make lots of edits near one location which plays into the favor of the two stack model but the down side is that this approach does not perform well for large amounts of text where the cursor goes from one end to the other end of the large text over and over. There is also more memory required compared to perhaps a gap buffer but still less memory intensive as the tree approaches.
Moreover, I have not seen many real world text editors use this approach but it's certainly an interesting idea that is extremely easy to implement but more practical for an assignment.
Split Buffer

After reading the article where this idea came from, it is basically a variation of the two stack model. Everything else is pretty much the same idea as the two stack model except for the fact that you are using two array lists instead of two linked lists.
Although contents have to be shifted over, array lists have an amortised time complexity bringing all the fundamental operations to the same time complexity as the two stack model.
There is a bit more memory being unused in an the split buffer approach but accessing elements is a bit quicker than accessing links due to better cache performance but strictly speaking, they are both practically the same in performance but use a different underlying data structure.
Pros and Cons
Pros
- Extremely easy to implement
- Mimics a cursor and typing actions
- If the cursor is already at the edit location then inserting/deleting/viewing a character are all instant time complexity.
Cons
- Requires a bit more memory than other approaches.
- Does not handle large text documents but would handle lines and perhaps a paragraph just fine.
- Does not handle constant cursor jumping back and forth from the front and end of the text.
Code
I have decided to add code to show you how simple the implementation is.
I've implemented the three core fundamental functionalities for a text editor.
This section of code implements the underlying singly linked list.
public class Stack<T> { //generic stack
protected static class Node<T> {
Node<T> next;
T data;
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
}
private Node<T> head;
private int size;
public void push(T item) {
head = new Node<T>(item, head);
size++;
}
public T pop() {
T item = head.data;
head = head.next;
size--;
return item;
}
public T peek() {
return head.data;
}
public String getFrontToBack() {
return getStackContent().toString();
}
//The contents are in reverse order, so need to reverse the content to get back to front
public String getBackToFront() {
return getStackContent().reverse().toString();
}
//Returning StringBuilder to make it easy to modify if we need to reverse the order of the contents
//also a fast way of creating a string
private StringBuilder getStackContent() {
StringBuilder sb = new StringBuilder(size);
//go through list and append the data
for (Node<T> curr = head; curr != null; curr = curr.next) {
sb.append(curr.data);
}
return sb;
}
public boolean isEmpty() {
return head == null;
}
public int size() {
return size;
}
}
These following sections shows the actual two stack model implemented.
public class TwoStackModel {
public static final char EMPTY_CHAR = '\0';
private Stack<Character> left;
private Stack<Character> right;
public TwoStackModel() {
left = new Stack<>();
right = new Stack<>();
}
//Methods will be discussed
public static void main(String[] args) {
TwoStackModel buffer = new TwoStackModel();
buffer.insert("OpenGenus");
buffer.moveLeft(2);
buffer.delete();
System.out.println(buffer.get() + "\t" + buffer.size());
buffer.delete();
buffer.moveLeft(3);
System.out.println(buffer.get() + "\t" + buffer.size());
System.out.println(buffer.concatenate());
}
}
Insert
Imagine the cursor is at the correct location. We are simply going to insert a character to the left of the cursor by adding it to the left stack.
The left stack is in reversed order as described on the left side of the two stack model picture. This will mimic the behavior of when you actually type a character.
public void insert(char ch) {
left.push(ch);
}
This is basically the insert method from above but we are going to insert a string as if we are pasting some text at the current cursor location.
public void insert(String input) {
for (int i = 0; i < input.length(); i++) {
left.push(input.charAt(i));
}
}
Delete
Delete will simply delete whatever character is on the left side of the cursor. If there are no characters, we are going to return a default value null char which is nonprintable.
public char delete() {
return left.isEmpty() ? EMPTY_CHAR : left.pop();
}
Moving cursor
This operation is where most of the time consuming work occurs where the cursor will pretend to move left simply by moving the contents on the left side onto the right side. There is also the case where the cursor can no longer go left, so we must ensure that left side still has contents to move otherwise stop.
//Moving the cursor position left, move left contents into the right stack
public void moveLeft(int amount) {
while (!left.isEmpty() && amount > 0) {
right.push(left.pop());
amount--;
}
}
This is the ame operation as the one above, except will move contents right to left and the cursor will pretend to move right.
//Moving the cursor position right, move right contents into the left stack
public void moveRight(int amount) {
while (!right.isEmpty() && amount > 0) {
left.push(right.pop());
amount--;
}
}
Viewing
Simply to how delete works, instead of modifying the underlying stack, we are only going to look at top of the stack. We also need to make sure to return an appropriate default value if the left side of the cursor is empty.
//Show content left of the cursor
public char get() {
return left.isEmpty() ? EMPTY_CHAR : left.peek();
}
This function will iterate throught the linked lists to concatenate both the left and right side of the buffer together in the proper order.
//Contents left and right of the cursor
public String concatenate() {
return left.getBackToFront() + right.getFrontToBack();
}
If we wanted to know how much content the cursor is dealing with, we simply add the contents on the left and right of the cursor.
//Size of contents left and right of the cursor
public int size() {
return left.size() + right.size();
}
Concatenating and moving the cursor takes O(N) time while all the operations are O(1) which is really nice in terms of such a simple implementation being able to perform quite well and mimicking a realistic text editor.