
A text editor is a program that allows the user to open, view, and edit plain text files (files containing only text). They are essential to the world today as lots of people often try to open a text file and view the content. Most of us have interacted or heard of text editors before such as Atom, Vim, Visual Studio Code, and so on. Text editors have evolved over time to become faster and provide more features than their competitors.
Text editors deal with manipulating text and provide features to enhance the experience. As mentioned before, the major functionalities of text editors are: inserting, deleting, and viewing text. Additonal features that are practically required to even compete with other text editors are:find and replace, copy/cut and paste, text formatting, sentence highlighting, and etc.
Designing a Text Editor
Text editors can be somewhat simple or rather complex depending on the design and implementation. It's important to consider your target audience (users) and what functionalities that you want your text editor to have. Perhaps you want a specialized text editor rather than a general purpose one as this will make a significant impact on designing and implementing a text editor. Take for instance you want a text editor to handle small files and fixed lengths of lines. Perhaps you want a text editor that minimizes memory usage while still performs adequately enough.
The bare backbones of a text editor heavily relies on the data structures you decide to use for your operations. There are always tradeoffs when it comes to data structures as you have to consider the difficulty of implementation for the performance and memory tradeoffs. It primarily based on what you want your text editor to be able to do.
Vert important There is no clear-cut solution as text editors will all vary in what data structures are used. Text editors in the past or that are currently being used have used these data structures listed down below.
Data Structures
Functional data structures will only be briefly included at the end
It's important to note that text editors will often use a few data structures to implement different functionalities.
Char Buffer (Array) / String data type
This is one of the more simpler and straightforward approach. String data type is mentioned as the underlying data storage is a char buffer. Insert at a specific location would simply be shifting the chars over and inserting the text at that location. Deleting would be to simply remove that character in the buffer and perhaps shift the array eventually. The additiona features would be easy to implement.
Advantages: Extremely easy to implement features and can minimize memory.
Disadvantages: Performance gets substanially worse as the file gets larger.
Gap Buffer
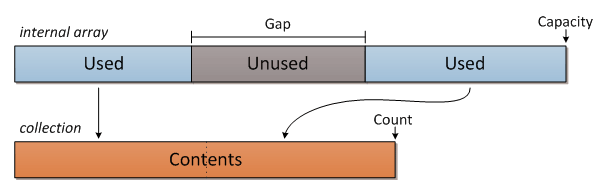
A gap buffer is essentially a snapshot of the current gap between the text based on the cursors location. This is practically an improved version of the char buffer. The gap buffer takes advantage of localization of edits to improve inserting and modifying text. For example, perhaps you are inserting and deleting text in one part of the text document, the gap buffer capitalizes on this and avoids uncessary shifts in the buffer.
It's important to take note that it still uses char buffer, but we shift our focus to the cursor location and provide a certain amount of space between text to allow edits without shifting the buffer contents unless the gap is too small.
There is also a variation called a split buffer that could be interesting to learn about. It's similar somewhat similar to the two stack idea.
Advantages: A popular approach as it is easy to implement with decent performance and low memory compared to the other approaches.
Disadvantages: If the gap is too small then the contents will still need to be shifted and obviously big files will still be an issue.
Two Stack Model
This approach is most likely only found in programming assignments rather than actual implementation, but it is good practice using stacks. The idea is to use two stacks to maintain the current cursor position. Left stack would contain the contents to the left of the cursor and the right stack would contain the contents to the right cursor. You would just push or pop the elemnts to get to where you need and either insert or delete text.
Advantages: Good assignment, fun to implement along with cursor like behavior representation.
Disadvantages: Have to shift content in order to get to the specific index for almost every operation causing it to be highly impractical but can work on small text.
Doubly Linked List
Another straight forward approach would be using a doubly linked list. The linked list nodes could represent the lines and each node could use a gap buffer or whatever appropriate data structure to represent the data held in each line.
As you can see, this would make implementing very easy as most of the functions are clear along with adding lines or deleting lines very quick.
Alternatively though impractical, you could use a doubly linked list of doubly linked list of characters. This way editing would make sense but obviously accessing the node will take the most time and memory would be extremely high.
There is also the use a doubly linked list for a variation approach of piece chains which basically contain additional information in the nodes such as an offset.
There is always the arrays of arrays approach but is inferior to the doubly linked list approach.
Advantages: One of the more straihgtforward and easy to implement approach. Will perform better with larger files than the stadard buffer approaches.
Disadvantages: Memory consumption and accessing a specific row or column is a bit more time consuming.
Rope
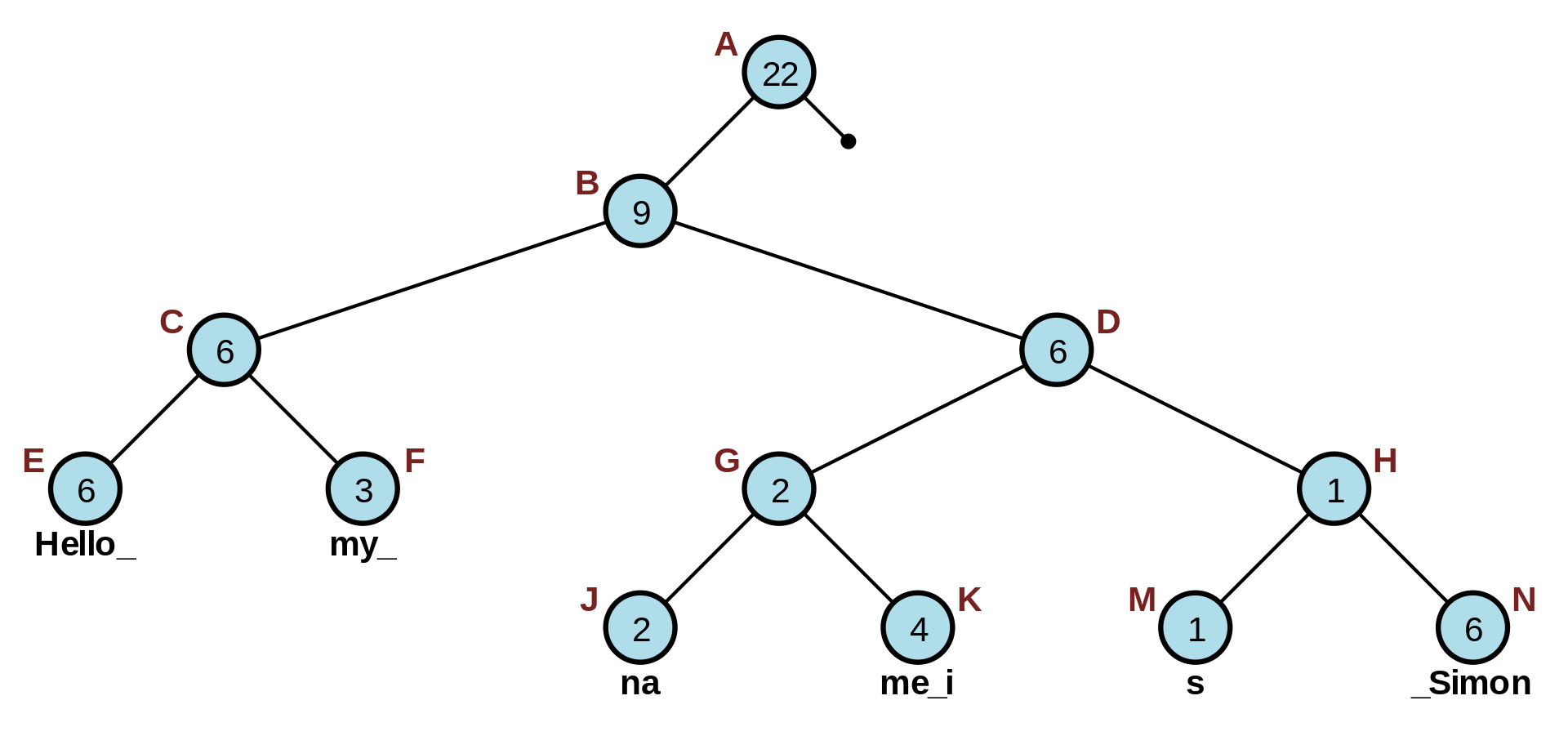
A rope is a tree-like data structure that maintains a weight and each leaf node will contain a buffer of characters. The weight for leaf nodes will be the length of the buffer. The weight for non-leaf nodes will the total weight in the left subtree (which includes the right side of the left subtree, recursively). The main benefit of rope is the ability to edit strings rather quickly in logarthimic time. However, the implementation and memory complexity is significantly higher than other approaches mentioned.
A rope may need to be rebalanced too in order to avoid situations where the tree is skewed which reduces the performance for certain operations. There are papers on when to rebalance but it's a bit more complex. Tree-like data structures tend to be more complicated to implement, so be careful and test and debug plenty.
Advantages: Good performance for edits.
Disadvantages: High memory usage, higher difficulty in implementing, and may need a rebalance if a skew tree structure happens.
B-Tree / B+ Tree
Both B-tree and B+ tree are different but will have somewhat similar results, so they are grouped together. These trees have many different uses such as using other data structures in the nodes while maintaining good access performance, useful for separating sections of text, and other uses that people can cleverly think of.
For example, you could store a rope/gap buffer/or another data structure inside the nodes and allow edits inside there. You could also have section based indexed tree.
Just like the rope, the difficulty of implementing is significantly more difficult than the other methods.
Advantages Good access performance and edit performance can be potentially good depending on how you use the tree.
Disadvantages High memory usage, higher difficulty in implementing, and may not be clear how to use this data structure properly.
Piece Table

A much simplier approach than the tree-like structures while still maintaining high performance would be a piece table. Interstingly enough, there is not much information about this data structure since implementation varies and there is no clear cut way to implement it. A piece table will often contain a resource of buffers to use from along with offsets and lengths to store. Storing information about these edits rather than actually performing them can all later be applied when the results are needed. When the results are needed, you would simply apply the operations on a big buffer to hold all the information to allow quick edits. This is also helpful for the additional features such as undo, redo, copy and pasting, and etc.
Often times, the edits may be stored in a list but more performant piece tables have decided to use a splay tree or a balanced tree of some sort to allow better performance and cache the most recent edit.
Other Honorable Mentions
Here are other data structures to consider:
- Zipper / Finger Trees
- A useful functional data structure that represents a tree-like structure. These are often a favorite for functional programming languages to implement a text editor in combination with another data structure.
- RRB-Tree
- A Relaxed Radix Balanced Tree is another data structure for functional programming languages. Esentially it's a tree-like structure that is similar to the idea of a btree and rope. Essentially ti's a relaxed version of BTree while providing vector contatencation similar to that of a rope.
- Interval Trees
- Interval trees are helpful for implementing some of the additional features such as highlights, annotations, and etc. As interval trees will provide a good interface for a range of strings.
- Tries
- A dynamic tree-like structure that consumes quite a lot of memory in return for providing very cool features such as auto-completion, prefix look-ups, pattern matching and etc. They are not too difficult to implement either.
- Patch
- Another data structure for advance features for a text editor, one that Atom uses for concurrent-friendly edits. It's somewhat similar to a piece-table in the fact that it simply has edits stored in patches which later get applied to the buffer.
- Splay Tree
- This data structure is more of a supplement to other data structures. Although a tree-like data structure will have decent efficiency, it can still be more optimized for text editors. Often times people will make edits in one area then move to a different area, well if you are able to cache these areas to be closer to the root of the tree then there is very little lookup needed. Splay trees are a great optimization for caching previous edits.
Code
There is already a python implementation of the rope data structure
https://iq.opengenus.org/rope-data-structure/
however I wanted to share with you a Java implementation.
This implementation is not optimized and does not check for bad input values
You should also use inorder traversal to get the correct order of how the strings would be outputted.
//reference: https://en.wikipedia.org/wiki/Rope_(data_structure)
import java.util.LinkedList;
import java.util.Queue;
public class Rope {
protected static class Node {
Node left;
Node right;
int lengthWeight;
String data;
public Node() {}
public Node(String str) {
data = str;
lengthWeight = str.length();
}
private Node(Node left, Node right) {
if (left.lengthWeight == 0) {
left = right;
right = null;
}
this.left = left;
this.right = right;
lengthWeight = getWeight(left);
}
protected static int getWeight(Node leftChild) {
int weight = leftChild.lengthWeight;
if (!leftChild.isLeaf() && leftChild.right != null) {
do {
weight += leftChild.right.lengthWeight;
leftChild = leftChild.right;
} while (leftChild.right != null);
}
return weight;
}
public boolean isLeaf() {
return data != null;
}
public boolean isEmpty() {
return lengthWeight == 0;
}
}
private static class Pair {
Node left;
Node right;
public Pair(Node left, Node right) {
this.left = left;
this.right = right;
}
}
private Node root;
public void insert(String str, int index) {
if (str == null || str.length() == 0) {
return;
}
Node newNode = new Node(str);
if (root == null) {
root = newNode;
} else {
Pair splitNodes = split(index, root);
root = concatenate(splitNodes.left, concatenate(newNode, splitNodes.right));
}
}
public void delete(int from, int to) {
if (root == null) {
return;
}
if (from == 0) {
Pair splitNodes = split(to, root);
root = splitNodes.right;
if (root.isEmpty()) {
root = null;
}
} else {
Pair splitNodesLeft = split(from, root);
Pair splitNodesRight = split(to - from, splitNodesLeft.right);
root = concatenate(splitNodesLeft.left, splitNodesRight.right);
}
}
private Node concatenate(Node left, Node right) {
return new Node(left, right);
}
private Pair split(int index, Node startingRoot) {
Queue<Node> prunedNodes = new LinkedList<>();
goDownPathAndUpdate(index, startingRoot, prunedNodes);
return new Pair(startingRoot, rightSideSplit(prunedNodes));
}
private void goDownPathAndUpdate(int index, Node current, Queue<Node> pruneNodes) {
if (current.isLeaf()) {
pruneNodes.add(new Node(current.data.substring(index)));
current.data = current.data.substring(0, index);
current.lengthWeight = current.data.length();
} else {
Node selectedChild = null; //Remember which child we went down
if (current.lengthWeight <= index && current.right != null) {
selectedChild = current.right;
goDownPathAndUpdate(index - current.lengthWeight, selectedChild, pruneNodes);
} else {
selectedChild = current.left;
goDownPathAndUpdate(index, selectedChild, pruneNodes);
}
//Update the parent node based on child node
if (current.right != selectedChild) { //only prune right side if child was left
pruneNodes.add(current.right);
current.right = null;
} else if (current.left.isEmpty()) { //fixing the child links
current.left = current.right;
current.right = null;
} else if (current.right.isEmpty()) {
current.right = null;
}
current.lengthWeight = Node.getWeight(current.left);
}
}
private Node rightSideSplit(Queue<Node> prunedNodes) {
Node rightSide = prunedNodes.remove();
while (!prunedNodes.isEmpty()) {
rightSide = concatenate(rightSide, prunedNodes.remove());
}
return rightSide;
}
public char charAt(int index) {
return charAt(index, root);
}
private char charAt(int index, Node current) {
if (current == null) {
return '\0';
}
if (!current.isLeaf()) {
if (current.lengthWeight <= index && current.right != null) {
return charAt(index - current.lengthWeight, current.right);
} else {
return charAt(index, current.left);
}
} else {
return current.data.charAt(index);
}
}
public String report(int start, int end) {
return report(start, end, root);
}
private String report(int start, int end, Node current) {
if (current == null || end < 1) {
return "";
}
if (current.isLeaf()) {
if (start > current.lengthWeight) {
return "";
}
if (end > current.lengthWeight) {
end = current.lengthWeight;
}
if (start < 0) {
start = 0;
}
return current.data.substring(start, end);
}
return report(start, end, current.left)
+ report(start - current.lengthWeight, end - current.lengthWeight, current.right);
}
public static void main(String[] args) {
Rope rope = new Rope();
rope.insert("llo_", 0);
rope.insert("na", 4);
rope.insert("my_", 4);
rope.insert("me_i", 9);
rope.insert("s", 13);
rope.insert("_Simon", 14);
rope.insert("He", 0);
String finalInput = "Hello_my_name_is_Simon";
for (int i = 0; i < finalInput.length(); i++) {
System.out.print(rope.charAt(i));
} //Hello_my_name_is_Simon
rope.delete(0, finalInput.length()/2); //delete "Hello_my_na",
System.out.println("\n" + rope.report(0, finalInput.length())); //me_is_Simon
rope.delete(3, 5); //delete "is", result = me__Simon
System.out.println(rope.report(0, finalInput.length())); //me__Simon
rope.insert("Hello my na", 0);
rope.insert("is", 14);
System.out.println(rope.report(0, finalInput.length())); //Hello_my_name_is_Simon
}
}
Resources
You could do your own research on what you might need to do for implementing a text editor, however here are some resources that might help.
- http://texteditors.org/cgi-bin/wiki.pl?DesigningTextEditors
- A collection of links that go through different aspects of a text editor from designing to implementing.
- There are plenty of videos online going through tutorials of basic text editors.
- Almost all of them lack depth in functionality.
- Look at the source code of text editors on Github to see what certain text editors did.
- Some text editors are very complex and or unorganized to read. Some are very easy to read. Must also consider what programming language they implemented the low-level parts of the functionalities in.
References
- https://en.wikipedia.org/wiki/Text_editor
- https://en.wikipedia.org/wiki/Gap_buffer
- https://en.wikipedia.org/wiki/Rope_(data_structure)
- https://code.visualstudio.com/blogs/2018/03/23/text-buffer-reimplementation
- https://blog.atom.io/2017/10/12/atoms-new-buffer-implementation.html
{kind=link}
{kind=link}