
In this article, we will look at Apache ZooKeeper and how it is useful in distributed systems.
Table of Contents
- What is ZooKeeper?
- Distributed Systems and the Need for ZooKeeper
- ZooKeeper Architecture
- ZooKeeper Data Model
- Various Types of Znodes
- Sessions
- Watches
- Working of ZooKeeper
- Application of ZooKeeper in the Hadoop Ecosystem
What is ZooKeeper?
Apache ZooKeeper is a service that offers distributed synchronization, maintaining configuration metadata, naming, and group services to a distributed cluster. ZooKeeper simplifies the process of managing services in distributed systems by providing a simple API.
It is an open-source project hosted by the Apache Software Foundation. ZooKeeper is widely used by companies such as Reddit, eBay, Facebook, etc, and is applied in distributed frameworks like Apache Kafka, Apache Hbase, Apache Solr, Facebook Messages, etc.
ZooKeeper was initially developed at Yahoo! Labs (now Yahoo! Research). The name ZooKeeper was decided because they felt that distributed systems are like zoo animals and are chaotic and hard to control and ZooKeeper was built to control them.
Distributed Systems and the Need for ZooKeeper
A distributed system consists of multiple software processes running concurrently on multiple physical machines. It can exploit the power of multiple machines to solve complex problems. These machines may communicate through messages through the network or using shared storage. A typical Master-worker distributed system may look like the following figure. The Master is responsible for keeping track of the tasks and assigning them to workers.
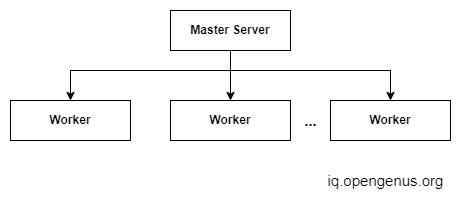
Coordination of these distributed processes is hard. How do we ensure that all the processes have the same application configuration? we can distribute the configuration to all the systems and restart but this will cause more downtime and performance issues. Another issue is, What happens if we add or remove new machines? but all these are functional problems and can be solved when we implement our distributed system.
The more difficult problems to address in distributed systems are how to deal with crashes and failures. What happens when the master or worker fails? or even worse what happens if the communication system itself fails? This is where ZooKeeper comes into play. It provides a simple framework for developers to use. Developers can focus on application functionality instead of worrying about distributed coordination.
ZooKeeper Architecture
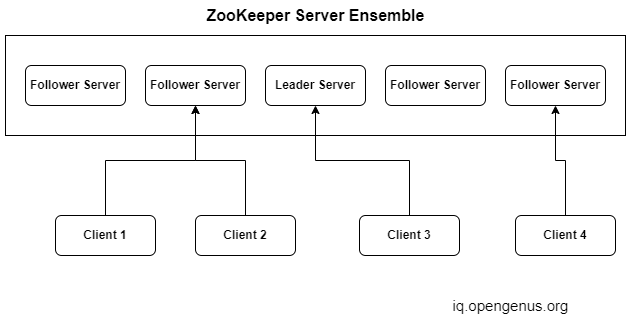
ZooKeeper follows a client-server architecture.
The Ensemble is a group of ZooKeeper servers. It needs a minimum of 3 servers.
The Servers provide services to the clients. Each client sends a message at particular time intervals to let the server know that it is alive and the server sends back an acknowledgment. If no acknowledgment is received, the client may redirect the message to another server at the ensemble.
One of the servers is elected as Leader at startup. It provides data recovery if any of the connected nodes fail. The Follower servers follow the orders of the leader.
Clients are nodes that are part of the distributed application and connect to the servers for accessing information.
ZooKeeper Data Model
Any method of storing data is called a data model. ZooKeeper allows synchronization by storing data in the ZooKeeper data model. The ZooKeeper data model looks similar to the UNIX filesystem. It follows a hierarchical namespace. Each node in the namespace is called a Znode.
Each Znode has is has a name preceded by a '/'. In the ZooKeeper namespace, a path identifies every Znode. Each node stores some data and may have children associated with it.
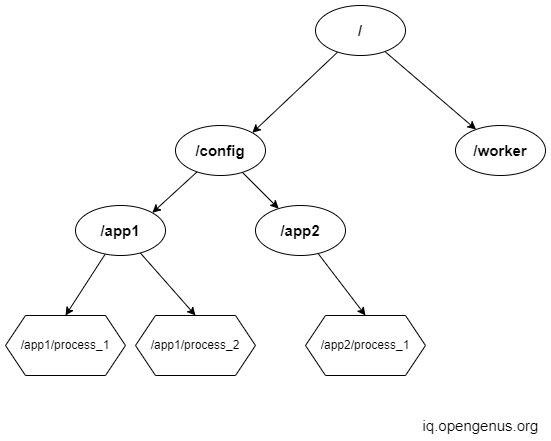
The '/' is the root namespace. It consists of 2 more namespaces called 'worker' and 'config'. The worker namespace is used for the naming process and the config namespace stores the configuration.
Every Znode stores its metadata in a stat structure. It consists of
Verison Number: It is increased each time the data in the node changes.
Access Control List(ACL): Used to restrict the read and write operations.
Timestamp: Stores the elapsed from the creation and modification of Znode in milliseconds.
Data Length: The length of the data stored in Znode. The maximum length is 1MB.
Within each of the ZooKeeper servers, the ZNode hierarchy is stored in memory. this helps for quick responses to reads from the clients.
Various Types of Znodes
1. Persistence Znodes:
These nodes stay alive even after the client that created them is disconnected. By default, all Znodes are Persistent Znodes.
2. Ephemeral Znodes:
They get deleted when the client is disconnected. They are not allowed to have any children. Ephemeral Znodes are used in leader election.
3. Sequential Znode:
Sequential Znodes can be either persistent or ephemeral. When a new Sequential Znode gets created, ZooKeeper sets the path by attaching a 10 digit sequence number to the original name. They are used for locking and synchronization.
Sessions
A session is a time interval for which the client receives service. When a client is connected, ZooKeeper automatically assigns it a unique Session-ID. The client sends a periodic PING message to the server to keep the session alive. A specific timeout is decided at the starting of the service and if the server does not receive any PING messages within the timeout, the client is assumed to be dead and the ephemeral nodes of that session get deleted.
Watches
Watches are a mechanism used to notify clients when there is a change in the ensemble. A client can also set watches while reading a Znode. When the data in the Znode or the children of the Znode are changed, the watches get triggered and the clients are notified. Znode watches are triggered only once. When the client is disconnected, the associated watches will be deleted.
Working of ZooKeeper
Now that we learned about the various components and architecture of ZooKeeper, let have a high-level overview of how ZooKeeper workflow.
First, The ZooKeeper ensemble starts, and a leader is elected. Then clients can connect to one of the serves in the ensemble. It can be either a leader server or a follower server. Once connected, each client is assigned a unique Session-ID.
The server sends an acknowledgment to the client. If no acknowledgment is received within the timeout, then the client tries to connect to another server in the ensemble. After this, the client can perform all the operations like reading, writing, etc.
During the connection, the client sends periodic PING messages to the server to show that it is alive. If the messages are not received within the timeout, then the client is assumed to be dead or disconnected.
Application of ZooKeeper in the Hadoop Ecosystem
Hadoop runs in a distributed structure with many nodes. A group of nodes is called a rack. Similarly, a group of racks is called a cluster.
In case of Hadoop, ZooKeeper is used for the coordination among the different nodes.
When there are thousands of nodes, ZooKeeper helps to easily configure all the nodes and sync the changes.
Say for example, In Hadoop you take 100 nodes and form a cluster and write some program to run on the cluster. In this case, you need to setup a network configuration between these nodes so that they can communicate and work together.
These configurations must be made for all the 100 nodes for synchronization, naming etc. This is a tedious process and in case there is a issue with the setup, we wouldn't want to reset each configuration.
This is where ZooKeeper comes to the rescue. It manages all these for us in a massive scale and also provides services such as monitoring race conditions, bug fixing etc.
With this article at OpenGenus, you must have the complete idea of ZooKeeper in System Design.