
Get this book -> Problems on Array: For Interviews and Competitive Programming
Reading time: 35 minutes | Coding time: 10 minutes
Extractive Text summarization refers to extracting (summarizing) out the relevant information from a large document while retaining the most important information.
BERT (Bidirectional Encoder Representations from Transformers) introduces rather advanced approach to perform NLP tasks. In this article, we would discuss BERT for text summarization in detail.
Introduction
BERT (Bidirectional tranformer) is a transformer used to overcome the limitations of RNN and other neural networks as Long term dependencies. It is a pre-trained model that is naturally bidirectional. This pre-trained model can be tuned to easily to perform the NLP tasks as specified, Summarization in our case.
Till the date, BERTS are considered as the best available technique to perform the NLP tasks.
Points to a glance:
- BERT models are pre-trained on huge datasets thus no further training is required.
- It uses a powerful flat architecture with inter sentence tranform layers so as to get the best results in summarization.
Advantages
- It is most efficient summarizer till date.
- Faster than RNN.
- The Summary sentences are assumed to be representing the most important points of a document.
Methodology
For a set of sentences {sent1,sent2,sent3,...,sentn,} we have two possibilities , that are , yi={0,1} which denotes whether a particular sentence will be picked or not.
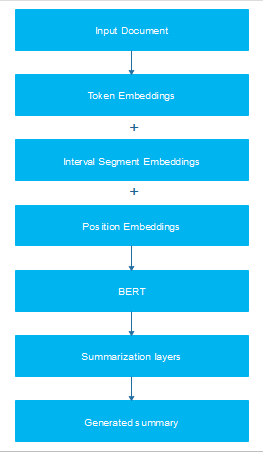
Being trained as a masked model the output vectors are tokened instead of sentences. Unlike other extractive summarizers it makes use of embeddings for indicating different sentences and it has only two labels namely sentence A and sentence B rather than multiple sentences. These embeddings are modified accordingly to generate required summaries.
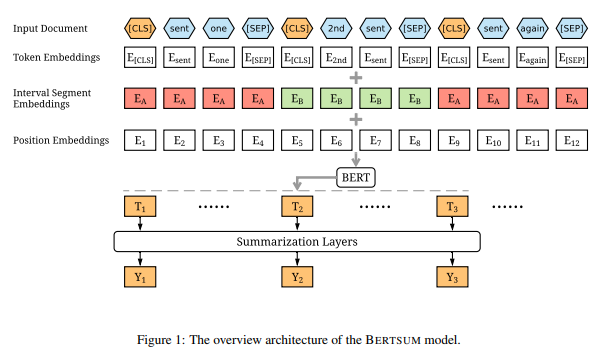
The complete process can be divided into several phases, as follows:
Encoding Multiple Sentences
In this step sentences from the input document are encoded so as to be preprocessed. Each sentence is preceeded by a CLS tag and succeeded by a SEP tag. The CLS tag is used to aggregate the features of one or more sentences.
Interval Segment Embeddings
This step is dedicated to distinguish sentences in a document. Sentences are assigned either of the labels discussed above. For example,
{senti}= EA or EB depending upon i. The criterion is basically as EA for even i and EB for odd i.
Embeddings
It basically refers to the representation of words in their vector forms. It helps to make their usage flexible. Even the Google utilizes the this feature of BERT for better understanding of queries. It helps in unlocking various functionality towards the semantics from understanding the intent of the document to developing a similarity model between the words.
There are three types of embeddings applied to our text prior to feeding it to the BERT layer, namely:
a. Token Embeddings - Words are converted into a fixed dimension vector. [CLS] and [SEP] is added at the begining and end of sentences respectively.
b. Segment Embeddings - It is used to distinguish or we can say classify the different inputs using binary coding. For example, input1- "I love books" and input2- "I love sports". Then after the processing through token embedding we would have
c. Position Embeddings - BERT can support input sequences of 512. Thus the resulting vector dimensions will be (512,768). Positional embedding is used because the position of a word in a sentence may alter the contextual meaning of the sentence and thus should not have same representation as vectors. For example, "We did not play,however we were spectating."
In the sentence above "we" have must not have same vector representations.
NOTE - Every word is stored as a 768 dimensional representation. Overall sum of these embeddings is the input to the BERT.
BERT uses a very different approach to handle the different contextual meanings of a word, for instand "playing" and "played" are represented as play+##ing and play+ ##ed . ## here refers to the subwords.
BERT Architecture
There are following two bert models introduced:
- BERT base
In the BERT base model we have 12 transformer layers along with 12 attention layers and 110 million parameters. - BERT Large
In BERT large model we have 24 transformer layers along with 16 attention layers and 340 million parameters.
Transformer layer- Tranformer layer is actually a combination of complete set of encoder and decoder layers and the intermediate connections. Each encoder includes Attention layers along with a RNN. Decoder also has the same architecture but it includes another attention layer in between them as does the seq2seq model. It helps to concentrate on important words.
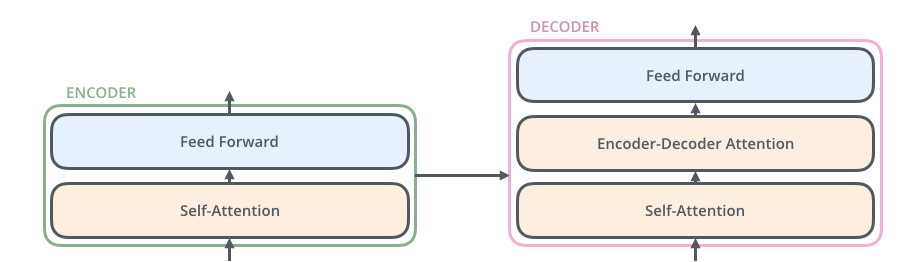
Summarization layers
The one major noticable difference between RNN and BERT is the Self attention layer. The model tries to identify the strongest links between the words and thus helps in representation.
We can have different types of layers within the BERT model each having its own specifications:
-
Simple Classifier - In a simple classifier method , a linear layer is added to the BERT along with a sigmoid function to predict the score Yˆi.
Yˆi = σ(WoTi + bo) -
Inter Sentence Transformer - In the inter sentence transformer ,simple classifier is not used. Rather various transformer layers are added into the model only on the sentence representation thus making it more efficient. This helps in recognizing the important points of the document.
where h0 = PosEmb(T) and T are the sentence vectors output by BERT, PosEmb is the function of adding positional embeddings (indicating the position of each sentence) to T, LN is the layer normalization operation, MHAtt is the multi-head attention operation and the superscript l indicates the depth of the stacked layer.
These are followed by the sigmoid output layer
hL is the vector for senti from the top layer (the L-th layer ) of the Transformer.
- Recurrent Neural network - An LSTM layer is added with the BERT model output in order to learn the summarization specific features. Where each LSTM cell is normalized. . At time step i, the input to the LSTM layer is the BERT output Ti.
where Fi, Ii, Oi are forget gates, input gates,
output gates; Gi is the hidden vector and Ci is the memory vector, hi is the output vector and LNh, LNx, LNc are there difference layer normalization operations. The output layer is again the sigmoid layer.
Pseudocode
BERT summarizer library can be directly installed in python using the following commands
pyhton pip install bert-extractive-summarizer for the easies of the implementation.
Import the required module from the library and create its object.
from summarizer import Summarizer
model=summarizer()
Text to be summarized is to be stored in a variable
text='''
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.OpenGenus is all about positivity and innovation.Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
'''
Finally we call the model to pass our text for summarization
summary=model(text)
print(summary)
OUTPUT-
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch , reduce the time spent on searching by exploiting the fact that almost 90 % of the searches are same for every generation and to make programming more accessible. We run one of the most popular Internship program and open-source projects and have made a positive impact over people 's life .
Further Reading
- Fine-tune BERT for Extractive Summarization (PDF) by Yang Liu (University of Edinburgh)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (PDF) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova (Google AI Language)
- Understanding searches better than ever before (Application) by Google
- Text Summarization using RNN by Ashutosh Vashisht (OpenGenus)
- Latent Semantic Analysis for text summarization by Ashutosh Vashisht (OpenGenus)
With this, you will have the complete knowledge of Text Summarization using BERT. Enjoy.