
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have explained the idea behind Google Cloud BigQuery in System Design and how it is used in real systems.
Table of contents:
- Introduction to Google Cloud BigQuery
- Google BigQuery's Key Features
- Google BigQuery Architecture
- How BigQuery stores data?
- BigQuery's pricing structure
Introduction to Google Cloud BigQuery
Google BigQuery is a fully managed enterprise data warehouse that is serverless, highly scalable, and cost-effective for analyzing petabytes of data and billions of rows using ANSI SQL.
So, what does this imply for you?
There is no need for server maintenance or configuration.
Scaling to infinity automatically.
The development and maintenance of tables and data are the only responsibilities.
If you're already familiar with the widely used ANSI SQL, you're good to go. It is simple to get started.
With BigQuery, Google provides a managed relational database with a pay-as-you-go model, charging you only for the time you use the service.
BigQuery also has the advantage of being easy to integrate with other GCP products. In addition, Google's Data Studio makes it simple to view data from BigQuery.
You may use BigQuery to handle the entire interaction in a variety of ways.
• Using the Google Cloud Platform console
• Client libraries for the programming language of your choosing
• Using CLI commands
Google BigQuery's Key Features
Why did Google introduce BigQuery, and why would you choose it over a more well-known data warehouse solution?
Implementation Ease: It's costly, time-consuming, and tough to grow if you build your own. BigQuery requires you to load data first and only pay for what you need.
Speed: Processes billions of rows in seconds and can handle real-time data analysis.
BigQuery is a complex service with 12 user-interface elements:
- Storage Engine: BigQuery features a storage engine that optimizes and evolves the storage without causing any disturbances.
- Jupiter Network: The Jupiter Network is an internal data center network that enables BigQuery to divide storage and computation.
- Dremel Execution Engine and Standard SQL: Dremel enables for clever scheduling and pipeline execution.
- Serverless Service Model: The serverless service model provides the maximum level of abstraction, automation, and manageability.
- Enterprise-Grade Data Sharing: Because computing and storage are separated, BigQuery allows the sharing of Exabyte-scaled datasets. You can even share data with other businesses, and you only pay for storage while others pay per inquiry.
- Federated Query Engine: You can query data from BigQuery without moving it if it's stored in GCS, Google Drive, or Bigtable. Federated Query Engine is the name for this.
- IAM, Audit Logs, and Authentication: BigQuery enables enterprises to regulate and role people at a high level of granularity. The two kinds of authentication utilized for access controls are OAuth and Service Accounts.
- Datasets: It has four pricing tiers: public, commercial, marketing, and free.
- User interface, command line interface, software development kit, ODBC/JDBC, and API: Everything is wrapped around a REST API in this access pattern.
- Pay-Per-Query AND Flat-Rate Price: The two pricing models are based on the needs of the user.
- Streaming Ingest: This feature allows you to process millions of rows at once.
- Batch Ingest: Capable of processing millions of records, although not as quickly as streaming processing.
Google BigQuery Architecture
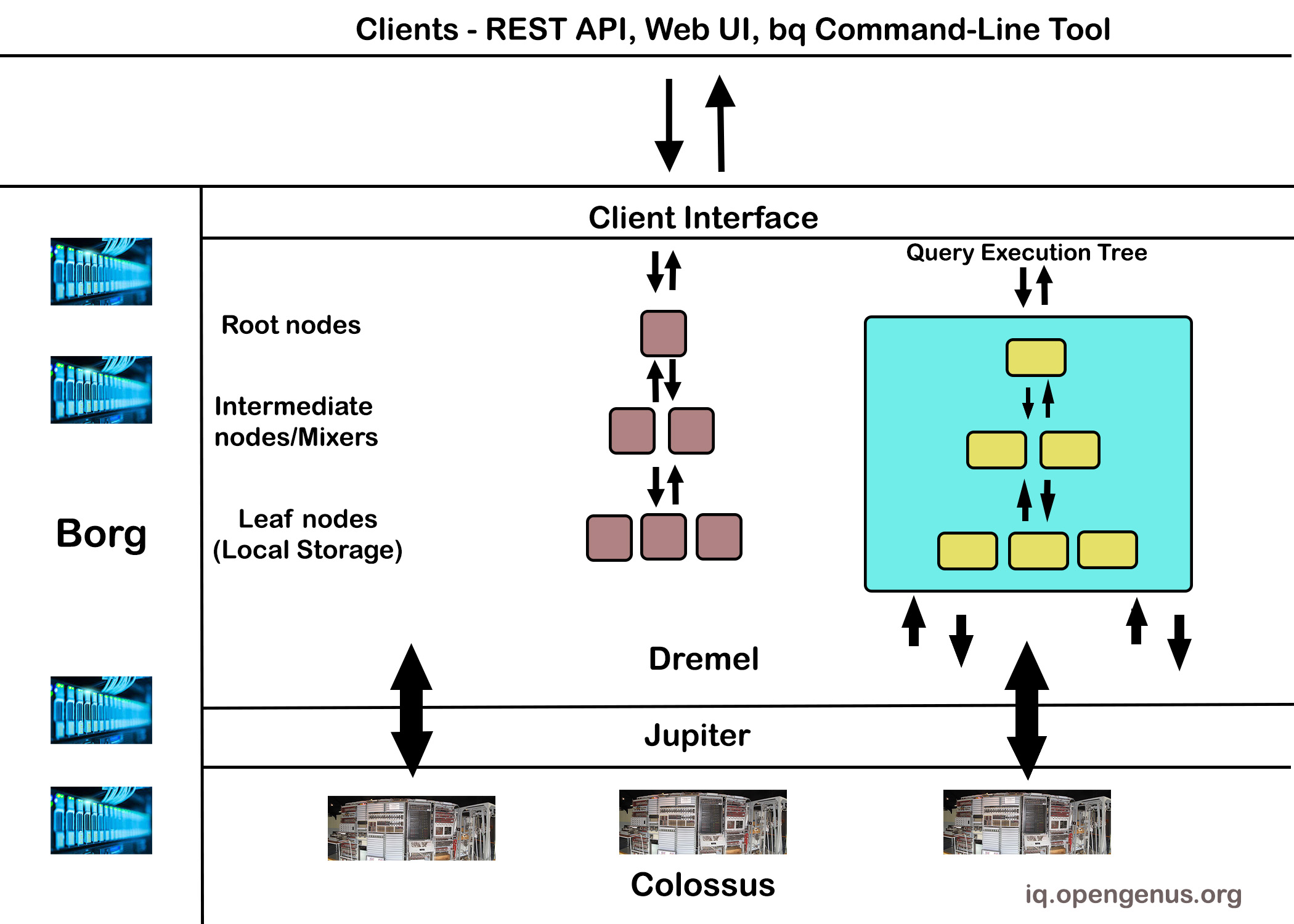
The storage and computation resources are segregated in BigQuery's serverless architecture. This enables you to quickly import data of any size into the warehouse and begin data analysis. The infrastructure technologies that enable this are as follows:
Colossus is in charge of storage. This is a global storage system that is designed to read massive volumes of structured data and handle replication, recovery, and distributed management.
Dremel is in charge of computation. This is a multi-tenant cluster that generates execution trees from SQL queries. The leaves of these trees are known as slots, and a single user can have thousands of slots to perform their queries.
Jupiter is in charge of data flow between storage (Colossus) and computation (Dremel). This is a petabit network that transfers data from one location to another incredibly quickly.
Borg is in charge of allocating hardware resources. This is a cluster management framework that allows BigQuery to perform hundreds of thousands of jobs.
How BigQuery stores data?
The Google BigQuery Architecture employs a column-based storage or columnar storage structure, which allows it to process queries quicker while using fewer resources. It's the main reason Google BigQuery can manage massive datasets and offer fast results.
Because it is an efficient means of storing data for transactional databases, the row-based storage structure is utilized in Relational Databases where data is kept in rows. For analytical applications, storing data in columns is more efficient because it requires a faster data reading speed.
Assume a database has 1000 records or 1000 data columns. If we store data in a row-based structure, querying only 10 rows out of 1000 will take longer because the query output will include all 1000 rows. This is not the case with Google BigQuery's Columnar Database, which stores all data in columns rather than rows.
In the interest of the query, the columnar database will process only 100 columns, making the whole query processing faster.
BigQuery: The Service
Finally, these low-level infrastructure components are joined with several high-level technologies, APIs, and services, like as Bigtable, Spanner, and Stubby, to create BigQuery, a transparent and powerful analytics database.
The true value of BigQuery isn't in the fact that it provides great computing scale; it's in the fact that you can use that scale for your everyday SQL queries without having to bother about software, virtual machines, networks, or storage. BigQuery is a true Serverless database, and its simplicity allows clients with tens of petabytes of data to have a nearly identical experience to those on the free tier.
BigQuery's pricing structure
Three different cost drivers must be considered while using BigQuery:
- Costs of storage (active vs long-term)
- Costs of inserts (batch vs streaming)
- The cost of a query (pay-as-you-go vs flat-rate pricing)
Storage Price

The cost of storing data in BigQuery is referred to as storage price. You must pay for both active and long-term storage.
• Any table or table partition that has been updated in the last 90 days is considered active storage.
• Any table or table partition that has not been updated for 90 days is considered long-term storage. The cost of storage for that table is automatically reduced by about half. Between active and long-term storage, there is no difference in performance, durability, or availability.
When you load data into BigQuery or query it, you are charged based on the size of the data. The size of each column's data type is used to calculate data size.
The size of your saved data and the data processed by your queries are measured in gigabytes (GB), with one GB equaling 230 bytes. A gibibyte is another name for this unit of measurement (GiB). Likewise, 1 TB is 240 bytes (1,024 GB).
Inserting data in various ways
There are two ways to put data into your tables in BigQuery:
- Streaming
- Batch loading
When you use batch loading, you load all of the data into your BigQuery tables in one single batch transaction. Importing CSV files, an external database, or a group of log files are all common use cases.
The streaming technique, on the other hand, allows you to dynamically insert one record or small batches of records into your BigQuery tables. A typical use case is when your servers write logs or user interactions — such as tracking — directly to BigQuery without going through any intermediate steps.
On-demand pricing for Google BigQuery queries.
You are charged for the number of bytes handled by each query under this pricing model. Each month, the first 1 TB of query data processed is free.
Pricing that is set at a fixed rate. You buy slots, which are virtual CPUs, under this price arrangement. When you purchase slots, you are purchasing specialized processing capability to run queries. The following commitment plans have slots available:
• Flex slots: You commit to a 60-second slot at first.
• Monthly: You commit to a 30-day period at first.
• Annual: You make a 365-day commitment.
Monthly and annual plans offer a lower pricing in exchange for a longer-term commitment of capacity.

Google Cloud Pricing Calculator
Estimate
BigQuery flat-rate
Monthly flat-rate
Location: Iowa - US (multi-regional)
Slots: 500
Active Storage: 2,048 GiB
Long-term Storage: 0 GiB
USD 10,040.76
Total Estimated Cost: USD 10,040.76 per 1 month
Estimate Currency
USD - US Dollar
Free usage is available for the following operations:
Loading data (network pricing policy applicable in case of inter-region).
Copying data.
Exporting data.
Deleting datasets.
Metadata operations.
Deleting tables, views, and partitions.
Metadata operations
Reading pseudo columns
Reading meta tables
User-defined functions (UDFs)
Conclusion
If you want to master a new technology, you must first master the fundamentals. As we can see, Big query is a perfect blend of Cloud Computing and Big Data solutions, therefore understanding these technologies is beneficial to everybody.
With this article at OpenGenus, you must have the complete idea of Google Cloud BigQuery in System Design.