
In this article, we have explored the idea of MemCached in System Design and how it is used in different systems.
Introduction
Caching is a method of alleviating server loads when clients request data. Reading data from remote machines is asynchronous and time-consuming, because servers often need to make network calls to other servers and make I/O operations to query, update, and read databases. There are two common software tools for implementing a cache, called Memcached and Redis.
Contents
- Caching Basics
- Types of Caching
- Cache Invalidation
- Eviction Policy
- Memcache
- Redis
- What to Use
Caching Basics
We can use caching to store the either the most frequently called or recently called results. For example, a webpage where reading articles is more common than posting articles would benefit from caching network calls related to requesting a specific article than network calls requesting recently uploaded articles.
Requested data from a cache can lead to either a cache hit or a cache miss. Cache hits occur when a cache successfully contains the data related to a recieved network call and returns it to the application server. A cache miss occurs when a request is made for data not in the cache, so the application server then pulls data from the database to then send client side and store into a cache.
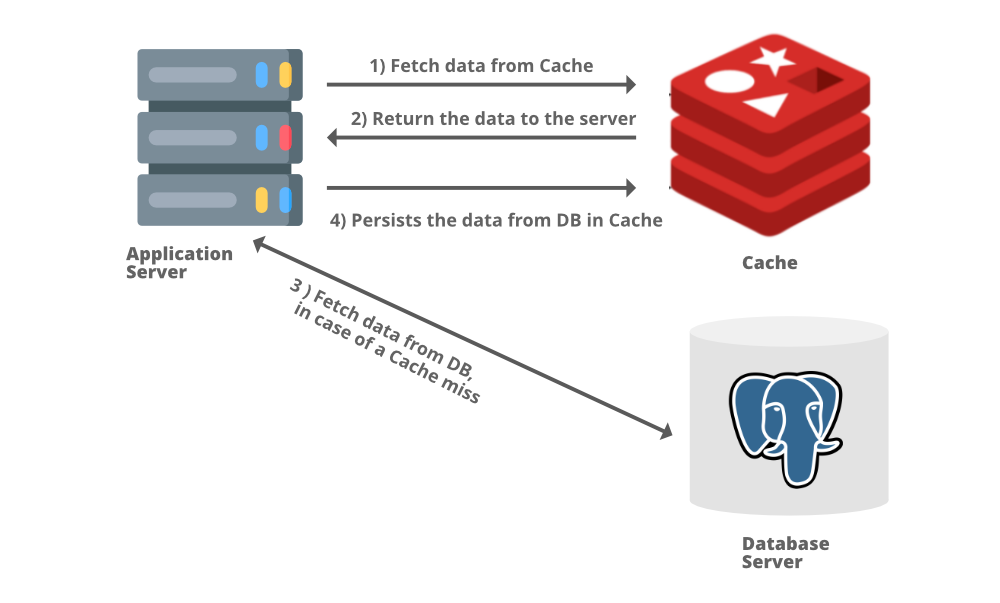
Types of Caching
1. Application Server Cache
Caches can be stored alongside an application server. The cache can be configured to store requests made to the application server, so if the same request is made again the cache will return the result.
New requests are fetched directly from disk, and then the application server will send the data to both the client and cache.
Note that caches take up additional memory on an application server, so the tradeoff to using one is faster server responses.
Problems arise when you are scaling a cache. For example, you add multiple servers nodes to your web application each with an independent cache. In this scenario, you’ll end up with a lot of cache misses because each node will be unaware of an already cached request.
We can overcome this problem with either distributed caches or global caches.
2. Distributed Cache
A distributed cache involves splitting a cache among all server nodes in a scaled system. Each cache will use a consisting hashing function, so requests made to one cache in a node will redirect to other caches in a different node.
Distributed caches are easy to scale, as we can simply add more nodes to the network. They have the weakness of increasing request times, as misses can result in network calls to other servers containing a different portion of the cache. Distributed caches will also store more information per server in the form of tables of pointers referencing stored data in remote caches.
3. Global Cache
A global cache takes the opposite approach of a distributed cache, by storing the cache on a dedicated server that all application servers will send requests to first before reading a database.
Scaling a global cache would simply mean upgrading the memory of the machine the cache is stored on. It has the benefit of reducing request times, since we only need to optimize a single server, but it has a single point of failure.
4. CDN (Content Distribution Network)
A CDN is used to cache a large amount of static content. This can be HTML files, CSS files, JavaScript files, pictures, videos, etc. First, request the CDN for the resources you require and if it exists then the data will be returned. If not, the CDN will query the backend servers and then cache it locally. These requests are normally made using a url to a resource stored in the CDN.
Cache Invalidation
The database acts as a consistent source of truth for the cache. But in many applications, the database is constantly updated, so results stored in the cache may be outdated. We can invalidate data in the cache by overwriting a previously cached request (essentially storing the updated request and removing the old one).
There are three schemes for achieving this:
- Write Through Cache
- Write Around Cache
- Write Back Cache
1. Write Through Cache
In this method, the server updates both the cache and database, first storing data in the cache and then the database after. This approach leads to a lower chance of data loss, but increases latency since data is written to two places every write request.
2. Write Around Cache
In this method, the server only updates the database. The cache will then query the database for any updates. This has the advantage of reducing the load on the server, since it only makes one write request, but has the downside of a cache that updates at a slower rate, so more cache misses will occur.
3. Write Back Cache
In this method, data is flushed from the cache, and then data is written to the cache alone. Once the data is updated in the cache, mark the data as modified, which means the data needs to be updated in DB later. A synchronous job is performed where the DB reads modified data from the cache at regular intervals. This approach has a high risk of data loss, since if the cache is cleared before the DB is updated, the DB is now incorrect.
Eviction Policy
Caches can store and evict data based on 4 policies:
- LRU
- LFU
- MRU
- Random Replacement
1. Least Recently Used (LRU)
As the name suggests, the cache stores incoming data like a queue, evicting data that was stored first or the least recently called request.
2. Least Frequently Used (LFU)
The cache keeps track of the frequency of incoming requests and evicts the least frequently used item.
3. Most Recently Used (MRU)
The cache gets rid of the most recently used data. This method gives priority to older data stored in the cache and prevents users from seeing recent data. For example, image a social media site with many posts. It would be ideal for a user to consistently see new posts rather than a post seen two minutes ago, so an MRU policy can track and remove recently seen items from a cache.
4. Random Replacement
This method selects a random item from the cache and discards it. This way priority isn't given to older or newer data.
Memcached
Memcached is a high-performance, distributed memory object caching system, originally used for speeding up dynamic web applications by alleviating database loads.
When installed on multiple nodes/machines/disks, memcached can take empty disk partitions and logically combine them into a single cache.
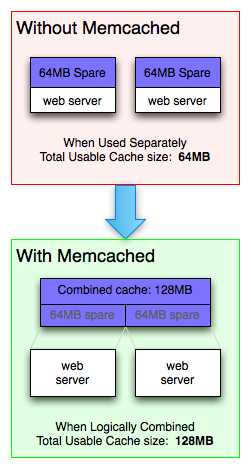
Memcached currently only has support on Linux and BSD servers.
Memcached currently consists of the following components:
- Client software, which is given a list of available memcached servers.
- A client-based hashing algorithm, which chooses a server based on the "key".
- Server software, which stores values with their keys into an internal hash table.
- LRU Cache.
It offers API integration for all the major languages like PHP, Java, C/C++, Python, Ruby, Perl etc.
Redis
Redis is another caching software like Memcached that offers many client-side libraries to access the redis-server. Redis also supports multiple eviction policies, but by default operates as an LRU cache.
Similar to Memcached, redis is a key-value store, but the values can be any complex data structure, from strings, hash tables, trees, graphs, and so on.
Redis also organizes distributed caches differently from Memcached, having master caches store keys to data stored on slave caches.
Below is a picture indicating the storage schemes used by both caches when scaling:
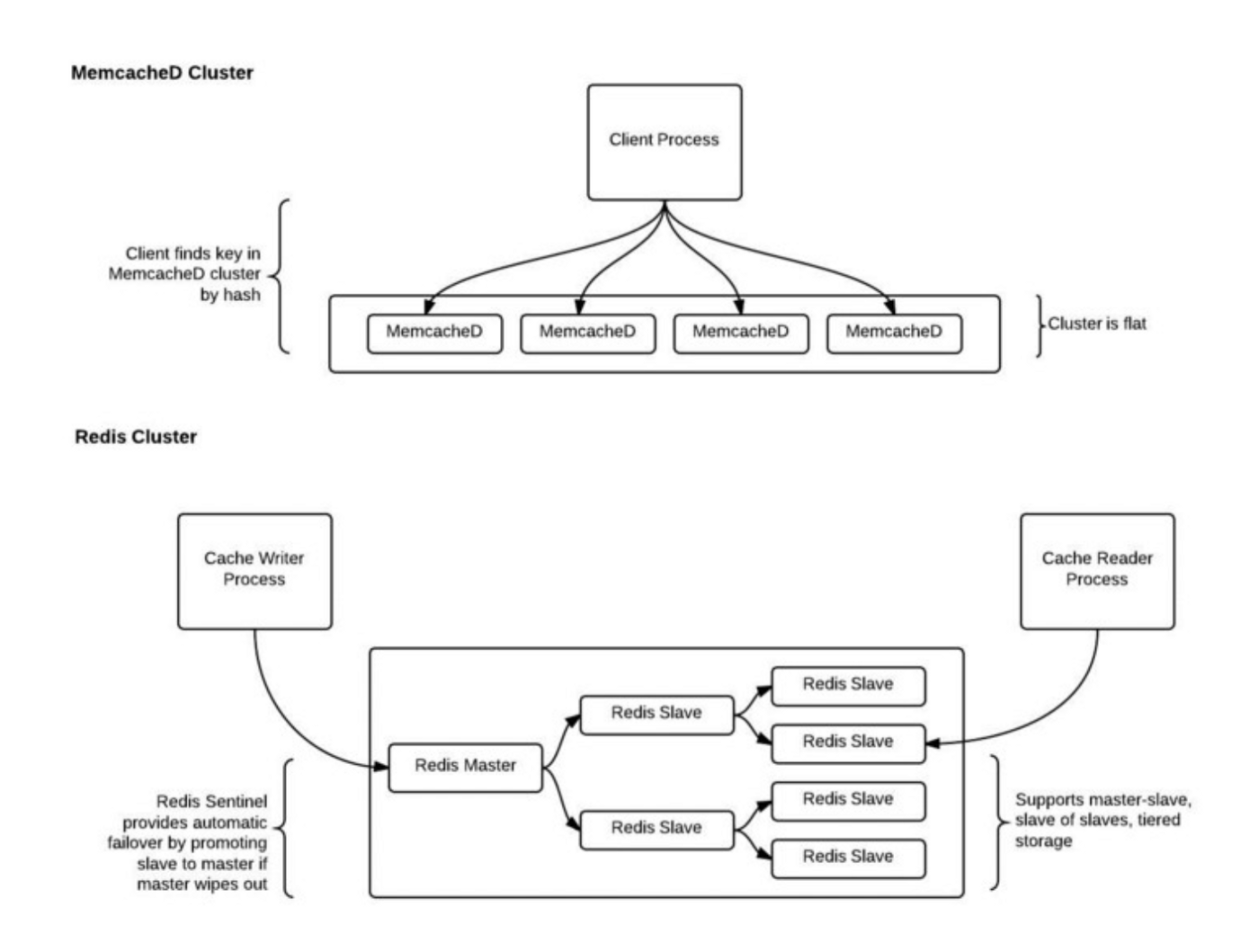
Memcached logically combines empty space across physical storage volumes (disks) into a single Memcached DB. To access a specific partition of the logical volume, a unique cryptographic key is used to access it. Memcached can be scaled horizontally by simply adding more volumes to add into the single Memcached DB. This means a new key will need to be generated to refer to the specific partition.
Redis on the other hand hierachically clusters partitions into a single logical volume in the form of a tree structure. Redis can specify a master cache to handle read and writes with slave replicas branching below the master to handle reads only. Redis is highly scalable in this way as growing the tree simply means making more slaves. If the master fails, a slave can take its place to continue the work.
Memcached is much easier to scale and faster to access, but doing so may cause loss of data since consistent hashing may not be able to generate valid unique keys for added data.
Redis is much harder to scale, but can scale more vertically and horizontally with slightly slower data access.
When to Use
Memcached is good for applications that require fast data access for small databases that recieve a large amount of requests. For example, caching webpage responses for a commonly visited route.
Redis is better for applications that have massive scaling databases where data access doesn't have to be as fast. For example, Redis would be better at caching the millions of tweets read when a hashtag is queried. Redis can be scaled to handle a massive amount of reads and writes.
With this article at OpenGenus, you must have the complete idea of MemCached in System Design.