
Capsule neural networks or CapsNet is an artificial neural network which consists of capsules(bunch of neurons) which allow us to confirm if entities (components) are present in the image. We will cover Capsule Networks in depth.
Introduction
Convolutional neural networks have proven to be a standard for classifying images. They are the main reason why deep learning has become so popular. However, they are not flawless as they have several disadvantages.
The major disadvantage being that they lack spatial information. Spatial information is the information about relative relationships between features(entities of the image). The max pooling layer was at fault as it was used to choose the most active neurons and thereby losing most of the important information about the spatial positions of the entities. These disadvantages led up to the creation of capsule neural networks.
Capsule neural networks
Capsule neural networks or CapsNet is an artificial neural network which consists of capsules(bunch of neurons) which allow us to confirm if entities(components) are present in the image. The capsule then assigns the entities the following:
- The probability of their (entity) existence.
- Their (entity) instantiation parameter which include the object angle, the scale, and the position.
A single Capsule consists of a bunch of neurons thereby representing a layer within a layer i.e a nested layer. These capsules are used to determine parameters of features present in the image by not only considering the existence of the features but also taking into consideration the spatial information of the entities in the image.
Capsule networks take their inspiration from computer graphics. In computer graphics , some amount of geometric data is given to the computer and the computer generates an image based on the data provided. The geometrical data is stored in the form of an array which takes into consideration the spatial representation of the entities it wants to generate. Then a software is used to take the data and generate the image, this process is called rendering.
Capsule networks operate on the idea of reverse graphics. In which we retrieve the data from the image and try to match it with the data we have.
Working of capsule networks:
Let’s try and understand how capsule networks work by taking a look at the image below.
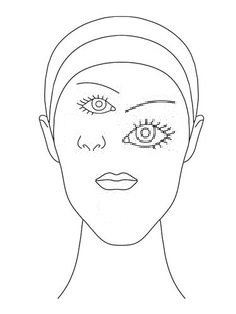
[Disoriented Face]
This image doesn't resemble a face even though it has all the components to make one. A CNN would classify this to be a face because CNNs do not pay attention to the pose and that’s what makes it hard for them to detect the features.
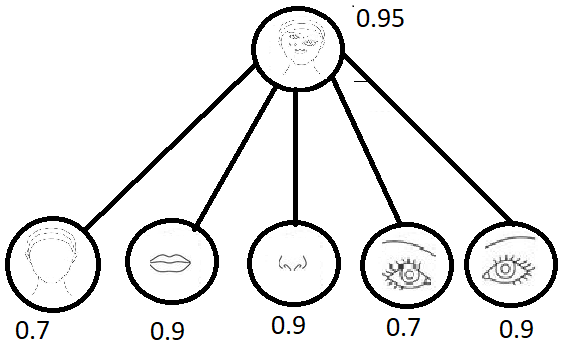
[CNN sub-structures]
The capsule networks intend to solve this problem by implementing a group of neurons (capsule) which are used to encode spatial information along with the probability of the entity being present. This would result in a capsule vector which would consist of the probability of the entities in the image along with the direction of the vector thereby representing the spatial information.
With the help of inverse graphics which is used in capsule networks, the capsules tries to reproduce an image based on it’s comparison with the labelled examples in the training set. By repeating this process, it gets better at predicting the instantiation parameters.The main idea behind capsule networks is to use “equivariance” instead of invariance.
Invariance states that the internal representation of the image doesn't change when the property of the image changes whereas equivariance states that the internal representation captures the property of the image. CNNs use invariance while capsule networks use equivariance. Invariance fails to capture the rotation of the image along with salient features such as the lighting, the tilt etc.
To demonstrate the above context let’s look at the image below:

[Diffrently shaded image]
Our brain would classify this as a statue regardless of the lighting and the rotations present. The object detection here is invariant to changes in lighting and rotation, but the internal representation is equivariant to these changes.
This in-turn means that moving a feature in the image will change the vector representation in the capsule, but will not change the probability of its existence.
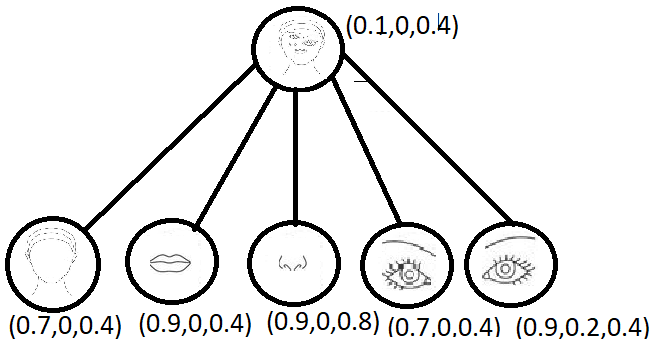
[CapsNet sub-structures]
Operations performed by capsule networks:
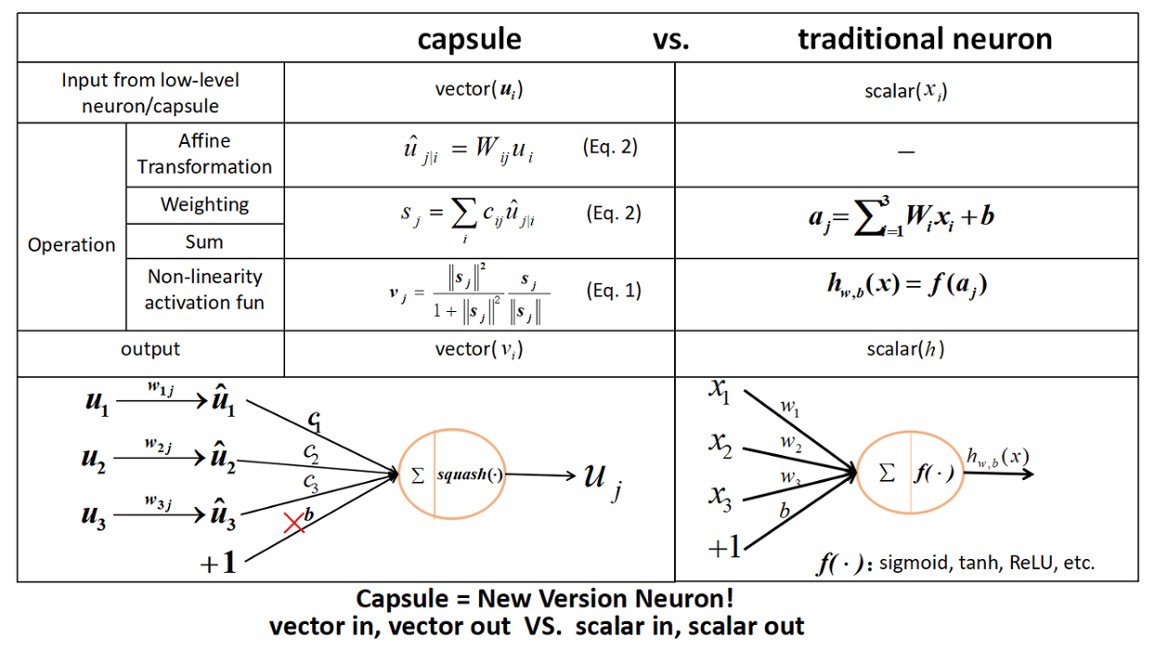
A regular neural network performs the following operations:
-
Step-1: Initially start with values which are mostly random for the network parameters (Wij weights and bj biases).(read ij and j as subscript)
-
Step-2: Take a set of input examples and pass them through the network to obtain the prediction.
-
Step-3: Comparing the outputs with the known outputs and calculating the loss.
-
Step-4 : Performing back propagation to update the parameters of the neural network andthe gradient descent in order to reduce the total loss.
-
Step-5 : To Continue iterating the previous steps until a better model is reached.
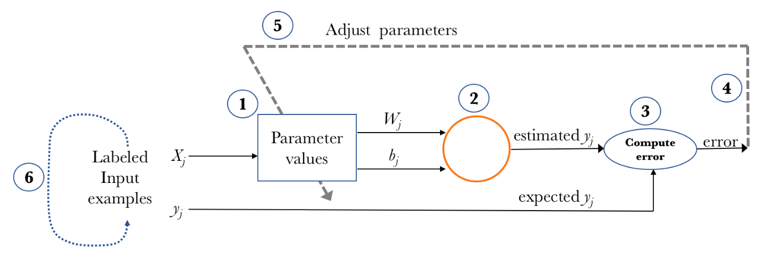
[Traditional Neural Network]
The operations are slightly changed for the capsules and are represented in the following steps: -
The first step revolves around the matrix multiplication of the weight matrices and the input vectors. This step is essential as it helps in encoding the spatial relations between the low level features and high level features of the image.
-
The second step revolves around dynamic routing in which the weights help in deciding which high level capsule will the current capsule send the output to.
-
The third step is the summation of the weighted input which is also similar to the step in the processing of the neural network.
-
The last step is where we apply the nonlinearity function otherwise known as the “squashing function” or the “squash function”. This function takes a vector and “squashes” the vector to value between 0 and 1 also retaining the direction of the vector.
[Comparision between networks]
More on dynamic routing:
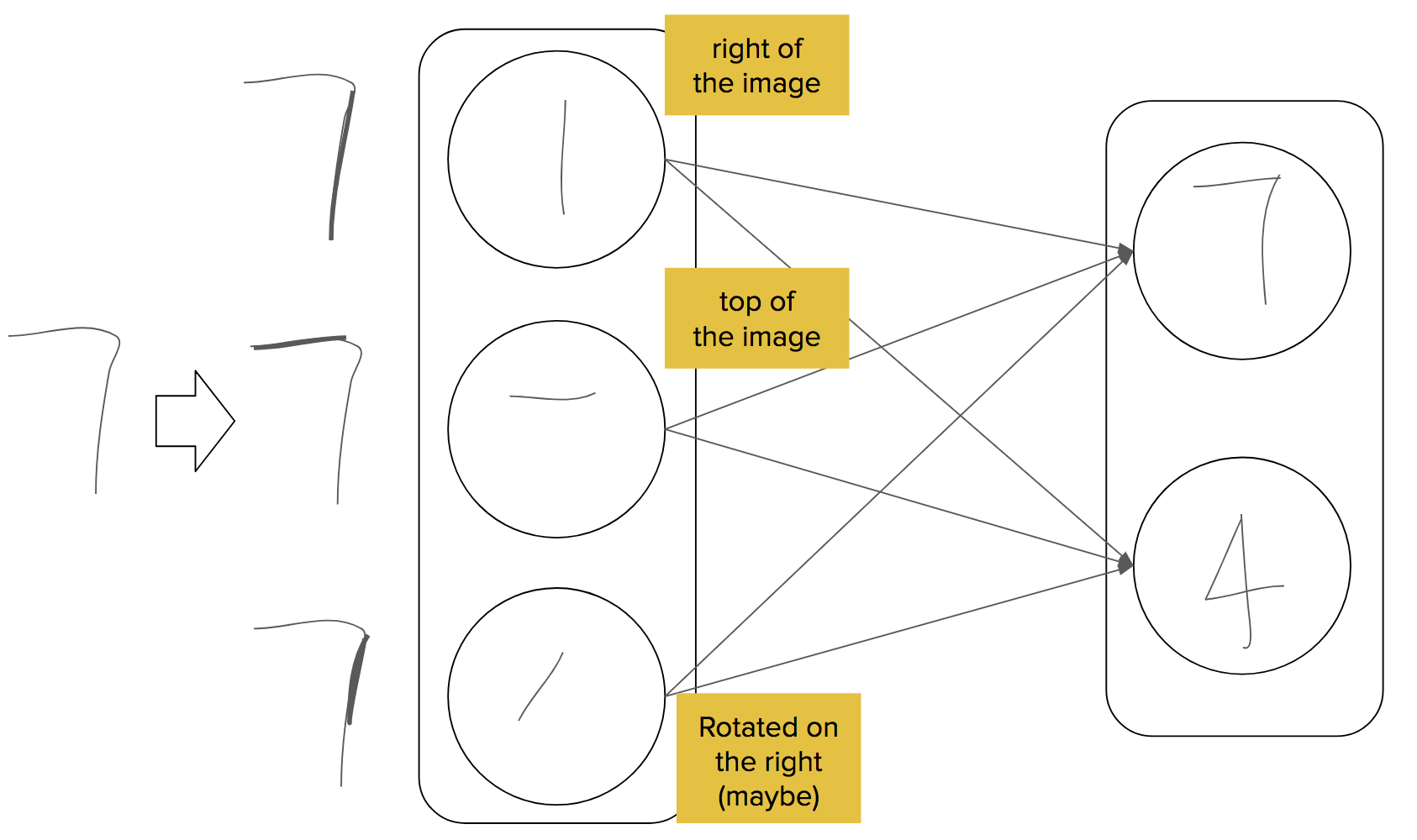
The process of dynamic routing revolves around the lower capsules, in which they send their data to a higher capsule. The parent capsule is the capsule which receives the data from the lower capsule and agrees with the lower capsule to process the data further.
The lower capsule computes a prediction vector which is formed by the dot product of its own output and the weight matrix. If the prediction vector is a large scalar value after the dot product with the output of a higher possible capsule, this results in increasing the coupling coefficient for the higher capsule and decreasing it for other capsules. Dynamic routing between capsules could be considered as a superior mechanism to max pooling as max pooling routes the strongest feature detected in the lower layers.
[Dynamic Routing]
The pseudocode for dynamic routing is:
procedure ROUTING(Ûj|i,r,l):
for all capsule i in layer l and capsule j in layer (l+1) : bij ← 0.
for r iterations do
for all capsule i in layer l: cj ← softmax(bi)
for all capsule j in layer (l+1): sj ← Σi cijûj|i
for all capsule j in layer (l+1): vj ← squash(sij)
for all capsule i in layer l and capsule j in layer (l+1):
bij ← bij + ûj|i.vj
return vj
(In the pseudocode above i and j are in subscript)
Squash Function:
The squash function is a type of activation function present in the capsule neural network which is used to normalize the output vector rather than the scalar elements itself. The output after the normalization guides us on the routing process of the data through various capsules which are then trained to learn several concepts.
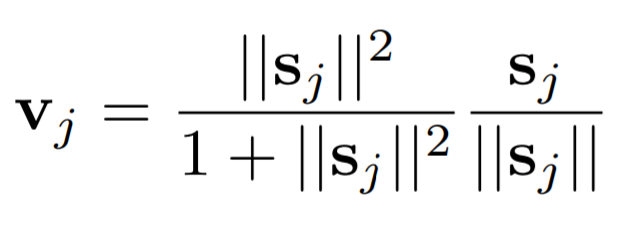
[Squashing Function]
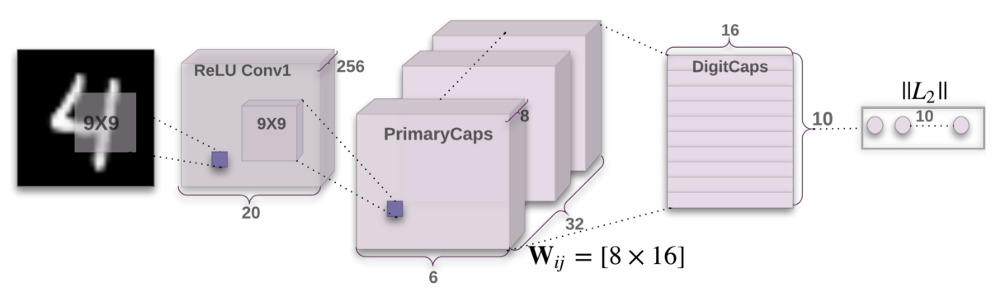
Architecture of capsule neural networks:
[CapsNet Architecture]
The architecture of the capsule network is made up of two parts which are :
- The encoder
- The decoder
Encoder:
The job of the encoder is to take an image as an input and present it as a vector (16-dimensional) which consists of all the instantiation parameters which are required to render the image. The encoder further displays the essentials such as:
-
Convolutional layer - This helps in detecting the basic features that are later analysed by the capsules. The conv layer consists of 256 kernels of size 9x9x1.
-
Lower capsule layer – This layer consists of 32 different capsules and are used to produce combinations which were based on the basic features detected by the convolutional layer. They produce a 4D vector as an output.
-
Higher capsule layer - This layer is the highest layer of the capsule neural network. This layer consists of all the instantiation parameters. The primary layer routes to this layer. This layer outputs a 16 dimensional vector which is used to rebuild the object.
Decoder:
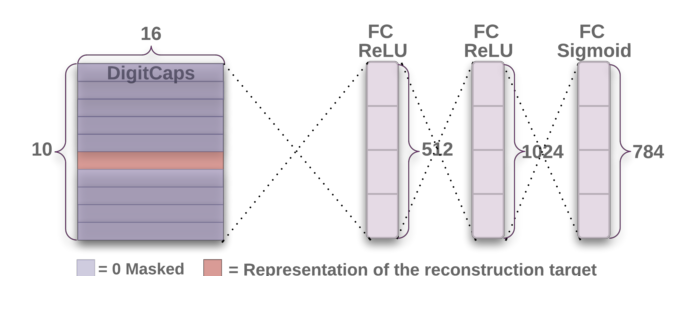
[Decoder Architecture]
The decoder is used to decode the 16D output provided by the higher capsule layer and also learn to decode the instantiation parameter to generate an image which we are trying to detect. The decoder uses a euclidean distance based loss function to determine how similar the reconstructed image is to the actual features of the image it is being trained on. The decoder further has three fully connected layers.
Conclusion:
Even though CapsNet has achieved state of the art performance on simple datasets such as the MNIST dataset. It however, struggles to perform with large datasets such as CIFAR-10 or Imagenet. This might be due to the excessive amount of information which proves to work against the idea of capsules by overflowing them with data. The capsule networks are still in the research phase but will surely set the standard for image classification in the near future.
With this article at OpenGenus, you must have a good idea of Capsule Neural Network. Enjoy.