
To discuss database replication, we first need to discuss the concept of replication in computing. Replication involves making copies of software, hardware, data, objects, states or such other related items and sharing them across multiple systems to achieve consistency and improve aspects like accessibility, fault tolerance and reliability.
Simply defined database replication is about storing copies of same data in many locations for backup, efficiency and other reasons. It also involves considering issues like how data will be accessed and ensuring data may or can be kept as similar as possible across all copies.
ACID
To understand the challenges of database replication and concept of consistency, we first have to understand the acronym ACID which ensures data validity and data intergrity regardless of errors or faults.
-
Atomicity is A - either a transaction fails or succeeds there must be no partial update in a database.
-
Consistency is C - ensures databases only moves between valid states, and is about the rules that must be enforced in database.
-
Isolation is I- execution of transcations in parallel must result in same state as when those same transactions are executed one after the other.
-
Durability is D- if a transaction is committed to database, we expect it continues despite errors or failures, it must be able to be recovered.
ACID : Atomicity, Consistency, Isolation, Durability
Most database replication can be represented as variations of the image below. data_replication_type1.png.
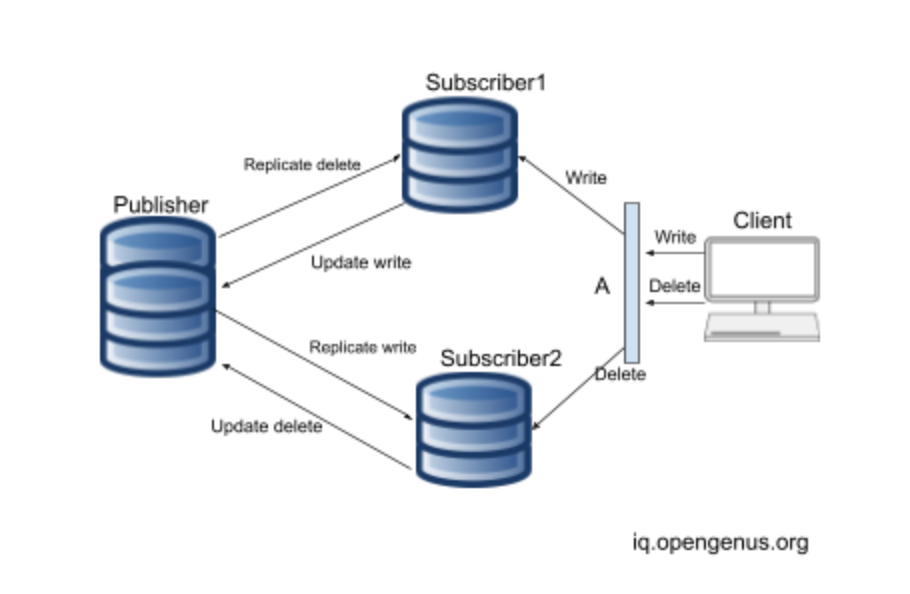
How it works?
In the image above commonly referred to as a Master-slave Architecture. Publisher is the Master and Subscribers are the slaves. If a client adds data to the database the write may go to Subscriber1. The Subscriber is connected to the main database the Publisher. Subscriber1 adds the new data to the Publisher. The Publisher makes changes to its database and replicates copies to all other subscribers connected to it like Subscriber2. If client deletes data, delete may go to Subscriber 2 which deletes the data and informs the Publisher. The Publisher will also delete the data and replicate copies of the database to all other subscribers connected to it, Subscriber1 in this case. Such a database replication system ensures entire system works as if it were one database and databases have same copy of data.
Example some replication techniques
Following are the types of Database Replication techniques:
- Full table replication - all data ie. rows in a table are copied in replication
- Key based replication - replicates only new or updated data
- Log based replicaiton - identifies the modification to database e.g inserts, deletes etc.
- Fast sync - similar to full table but with some optimizations for speed
Challenges database replication
-
Network latency may imply slaves lag severely from the Master. It may take time to replicate copies of database to slaves. Client which recently wrote to Subscriber1 but the change has not replicated to Subscriber 2. When client reads from Subscriber2 it is missing the new data. To solve this, many databases offer Read-After-Write consistency e.g like enforcing that reads are from a single database in the replica sets e.g Master.
-
Cost as you require more storage and resources to replicate databases
-
Normal databases operations may become disrupted e.g In some databases batch processing becomes impossible. Deletes have to be changeed to soft deletes so that data can be restored if needed.
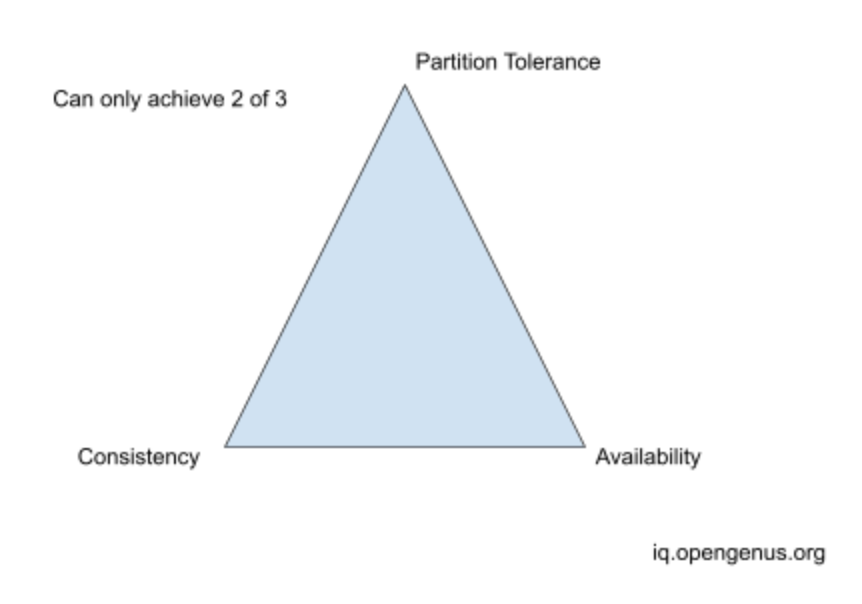
- CAP Theorem - capm_theorem.png above illustrates CAP Theorem. Partition Tolerance is about a system continuing to function when there is network partition between components in the system. When partition occurs you need to choose between Consistency and Availability. Its a tradeoff and one has to suffer.
Applications
Amazon Dynamo DB popularized the idea of leaderless replication.
A common architecure is that clients send writes to single a Leader node that replicates changes to the copy databases that can only be read from. Writing to many databases poses the challenge were nodes attempt to change the same row, data or object.
Therefore, leader replication is considered ideal but suffers from scalability, latency etc as leader has to receive all the writes which can be challenging for write intensive apps and geographic distribution.
In leaderless replication used in Dynamo DB, any database in architecture can receive writes. Client sends writes to multiple nodes and consensus is established as to confirm if write was successful when it has been written to a given number nodes.
Example where to use database replication
An organization with various branches but single database at main branch may struggle with issues like data access, availability, latency, overload on read and writes on central database.
A solution is to have replica databases at each branches. The main database can act as a Subscriber and the remaining as Publishers that will occasionally replicate data to the Subscriber central database. Alternatively merge replication can allow the branches to work independantly and occasionally merge data into asingle result.