
In this article we will talk about one of the game changer and the state-of-art in context of natural language processing field, which is the GPT 3.5 model from which a revolutionary chatGPT come from. As we all know that the transformers is the base model of GPT which is strictly decoder only model.
In short, GPT-3.5 model is a fined-tuned version of the GPT3 (Generative Pre-Trained Transformer) model. GPT-3.5 was developed in January 2022 and has 3 variants each with 1.3B, 6B and 175B parameters. The main feature of GPT-3.5 was to eliminate toxic output to a certain extend.
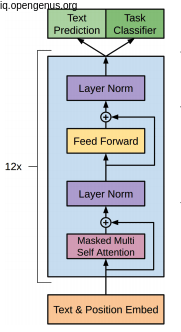
A 12 stacks of the decoders blocks with multi-head attention blocks.
So in this article we will talk about the history of GPT models till 3.5 versions for full understanding.
Table of Contents
1. The first GPT model.
2. GPT-2 Version.
3. The revolution of GPT-3.
4. Upgrade to GPT-3.5 series.
5. Differences between GPT-3.5, GPT-3 and GPT-2
Let's go through this amazing journey.
1. The first GPT model :
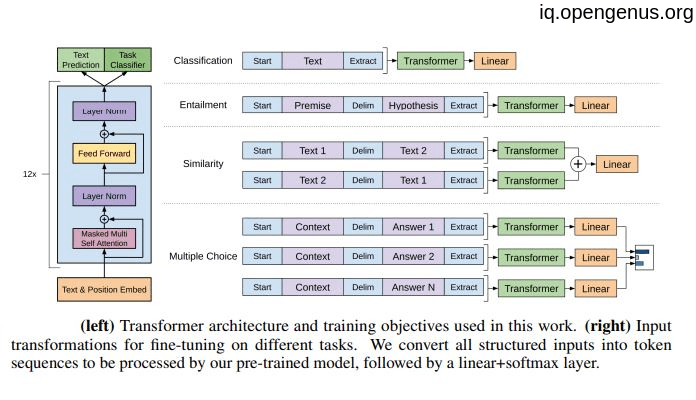
After the paper called "attention is all you need" come to light, a great model called GPT-1 invented based on the decoder of the transformers the paper suggest. this model take 12 layer of the decoder stacks and about 117 million parameter that will be trained on dataset of over 40GB of text. And after the training process we need to fine tune the model to the specific task that we need it for such as :
- Natural Language Inference
- Classification
- Question Answering
- Semantic Similarity
So, GPT-1 need two steps for working the first is training process and the the fine tunning process.
2. GPT-2 Version :
After a successful GPT-1 an OpenAI organization (the developer of GPT models) improve the model by releasing GPT-2 version which also based on decoder architecture of transformer but with 48 layers and 1.5 billion parameters that trained on 40 terabytes of text datasets from the internet sources.
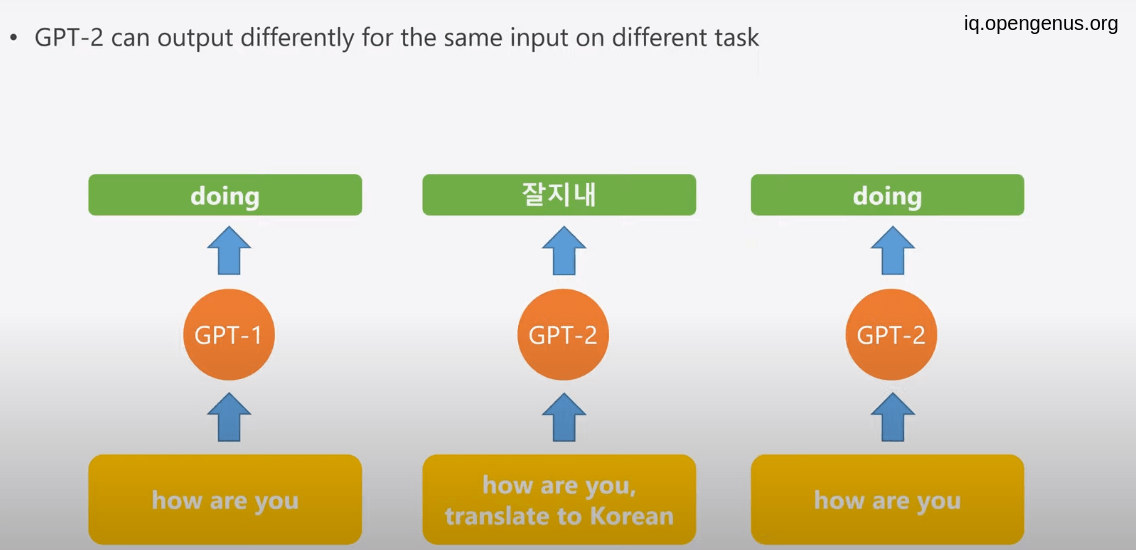
this large amount of data make it possible to be able to introduce the task name into the input of GPT-2 this enable us to get rid of fine tunning process which is expensive and time consuming .
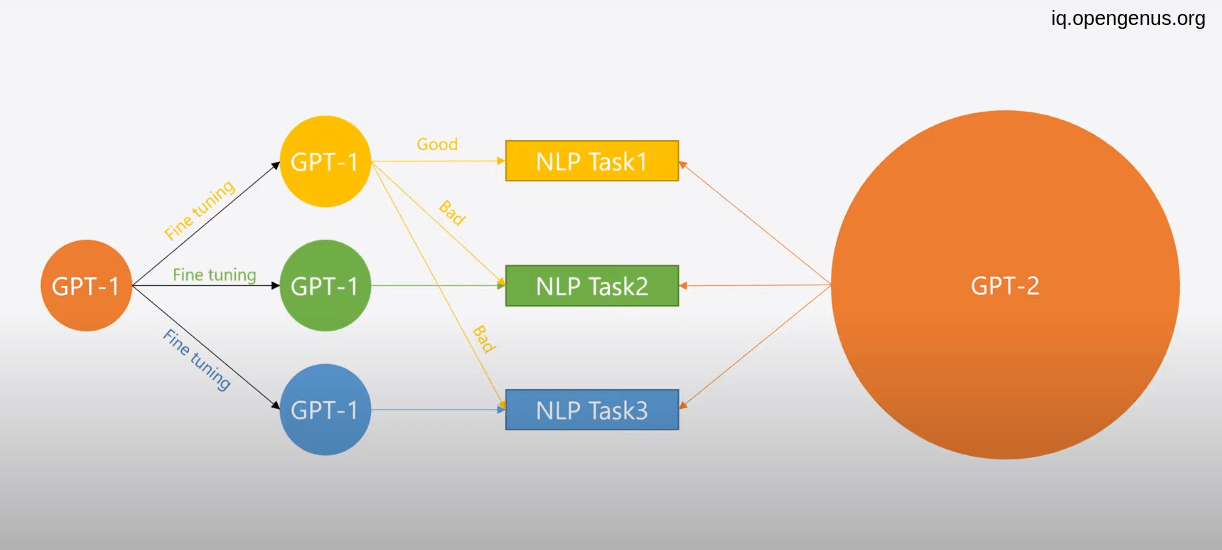
You can see the difference between the two model size !!!
 .
.
you can see that GPT-2 doing the task directly without need to fine tuning.
3. The revolution of GPT-3 :
Then introducing some techniques such as :
- zero-shot learning --> Given only the task name with "zero" example the model can predict the answer
- one-shot learning --> in addition to the task name and description we provide the model with "one" example the the model will be able to predict the answer.
- few-shot learning --> "few" examples will introduced to the model with the task description.
Introducing this learning processes and 175 billion parameters that train on a massive text data from diverse resources make GPT-3 produce more human-like text generation. Of course this was a huge improvement in the NLP field but it wasn't the end.
4. Upgrade to GPT-3.5 series:
GPT-3.5 is based on GPT-3 but work within specific policies of human values and only 1.3 billion parameter fewer than previous version by 100X. sometimes called InstructGPT that trained on the same datasets of GPT-3 but with additional fine tuning process that adds a concept called ‘reinforcement learning with human feedback’ or RLHF to the GPT-3 model.
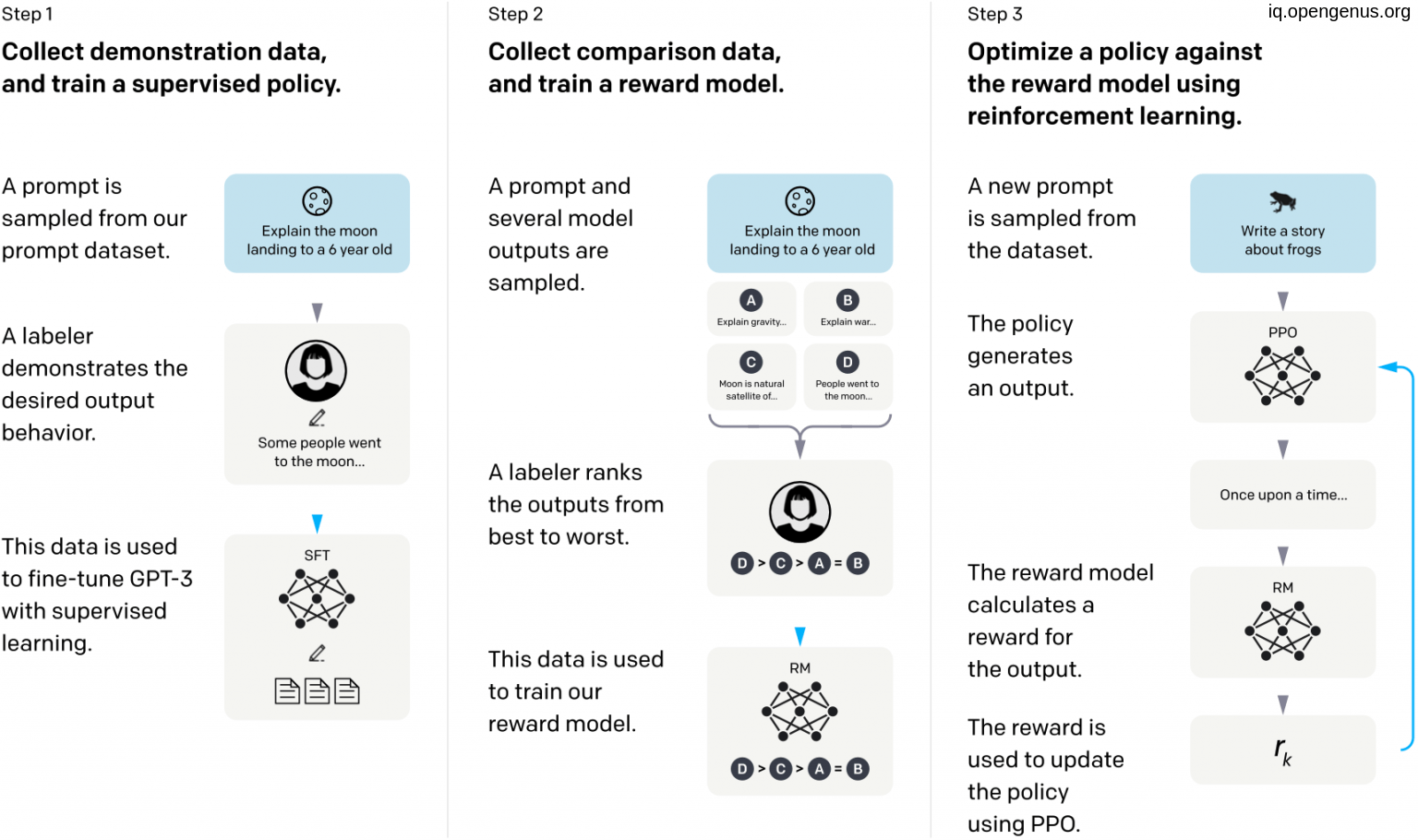
(RLHF) is a subfield of Artificial Intelligence (AI) that focuses on using human feedback to improve machine learning algorithms. In RLHF, the human provides feedback to the machine learning algorithm, which is then used to adjust the model's behavior. This approach is used to address the limitations of supervised and unsupervised learning, where the machine learning algorithms have limited ability to learn from just labeled or unlabeled data.
The human feedback can be provided in various forms, such as rewarding or punishing the model's actions, providing labels for unlabeled data, or adjusting model parameters. The goal of RLHF is to incorporate human expertise and knowledge into machine learning algorithms to improve their performance and ability to solve complex tasks.
So, Models referred to as "GPT 3.5" series is a series of models that was trained on a blend of text and code from before Q4 2021. The following models are in the GPT-3.5 series:
- code-davinci-002 is a base model, so good for pure code-completion tasks
- text-davinci-002 is an InstructGPT model based on code-davinci-002
- text-davinci-003 is an improvement on text-davinci-002
the highly famous ChatGPT dialogue model is a fine-tuned version of GPT-3.5 or InstructGPT, which itself is a fine-tuned version of GPT-3 that can engage in conversations about a variety of topics.
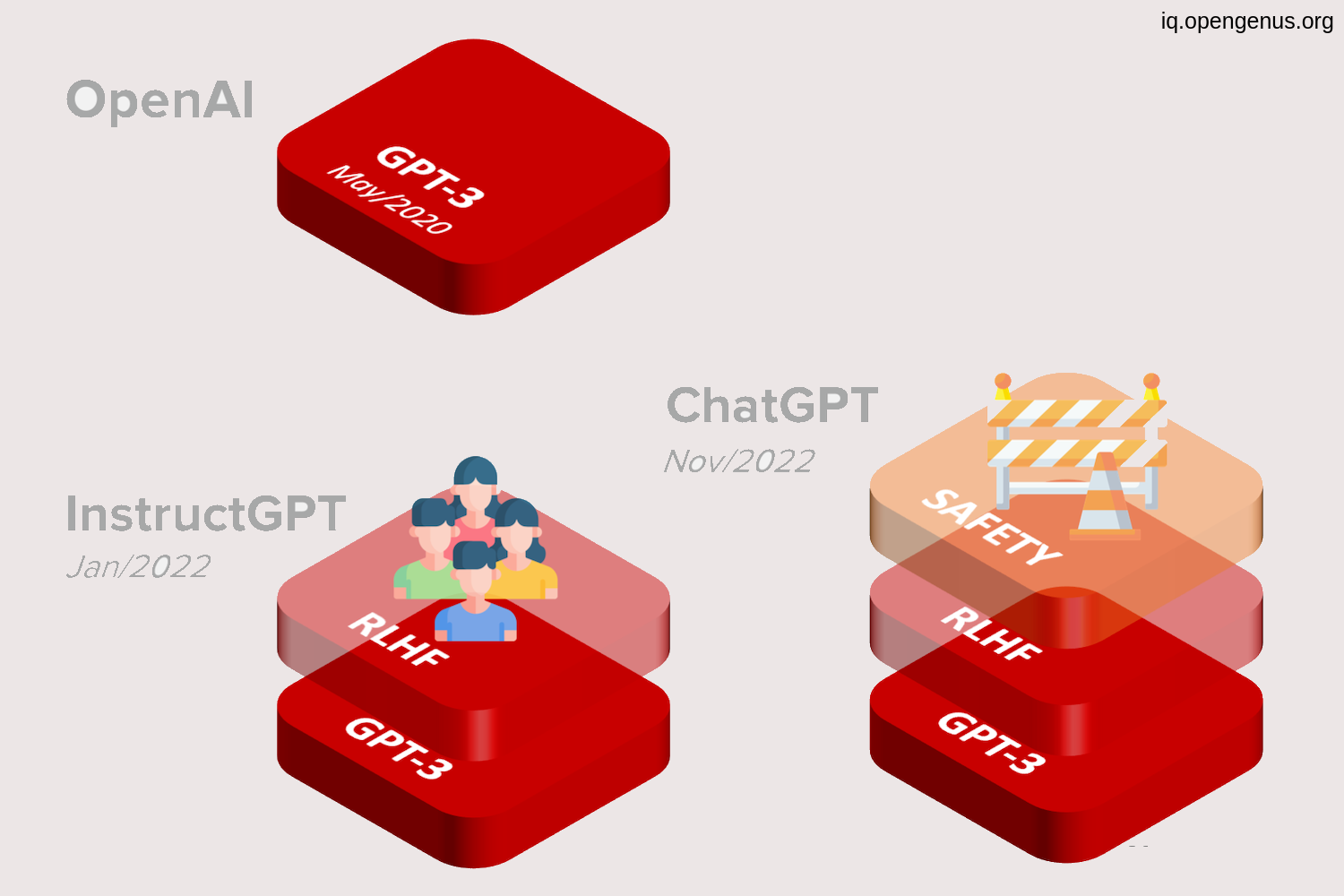
Observe the fine-tuning process added.
Use cases for ChatGPT include digital content creation, writing and debugging code, and answering customer service queries.
NOW the world is waiting the updated version of GPT family which is GPT-4 that supposed to be a great progress and another game-changer in the field, impressing the whole world by its capabilities, So let's wait and see.
So now we can table a time line for the GPT model as following :
| GPT-1 | GPT-2 | GPT-3 | GPT-3.5 | ChatGPT |
|---|---|---|---|---|
| Jun-2018 | Feb-2019 | May-2020 | Jan-2022 | Nov-2022 |
5. Differences between GPT-3.5, GPT-3 and GPT-2
| GPT-2 | GPT-3 | GPT-3.5 |
|---|---|---|
| Feb-2019 | May-2020 | Jan-2022 |
| one model | one model | three models |
| 1.5 billion parameters | 175 billion parameters | (1.3B, 6B, and 175B parameters) |
| produce a human-like text | Improved answers | the state of art with fewer toxic outputs |
And finally, I want to thank you for your accompany in this short journey of GPT-3.5.