
“Karma of humans is Artificial Intelligence”
Let's quickly run through the topics this post covers:
- Introduction to my background so that you can understand how I started to understand ML on my own.
- We'll commence with the question "why" because before diving deep into something, we must understand the essence of it.
- Then we'll cover the essentials that one must know, to get an extensive insight into machine learning.
- We then proceed to see "what" exactly is machine learning, and get rid of any misconceptions the world has!
- Then we see a basic roadmap I devised, for anybody who wishes to pursue this art further.
Introduction
As a freshman in college, I had a multitude of specializations to choose from in college. Going with the herd, I decided to opt for Artificial Intelligence and Machine Learning as my major alongside CSE, without even knowing what it meant. To put things into perspective, I was just a class 12 graduate with minimal knowledge of C++ and programming in general.
As uni started to pick up its pace, I found myself surrounded by buzzwords, "AI" and "ML" being the most frequent. Looking at seniors code up project after project, I started to feel frightened and lost in the wide world I had just entered. But I did not let this pull me down and I started exploring machine learning, by reading more. And before I knew, I would spend hours reading about the same online. I started talking to more seniors, who were experienced and started collecting resources to begin the beautiful journey. As advised, soon I was spending nights diving deep into machine learning algorithms and coding them from scratch, by following guides and articles.
I decided to collect resources and concentrate them to form a basic roadmap, to help other beginners like myself, who would like to explore the field further and not feel lost.
Who should read this?
- Technical people who wish to revisit the basics of machine learning quickly.
- Non-technical people who want an introduction and an intuition to machine learning but have no idea about where to start from.
- Anybody who thinks machine learning is “hard.”
Why Machine Learning?
Artificial Intelligence. It seems like the buzz word of this decade, doesn't it? To a newbie, this term accompanied by the hype around it creates a vivid scene from some sci-fi movie. But in reality, I like to call it an art of numbers. And like any other artform, this too can be mastered with consistent practice.
AI will shape the world more drastically than any other innovation in this century. After two AI winters over the past four decades, the game is now changing. And the credit goes to the growing volumes and varieties of available data, computational processing that is cheaper and more powerful, and affordable data storage.
Prerequisites to start with machine learning?
To understand the concepts presented, it is recommended that one meets the following prerequisites:
- An introduction to linear algebra: It is advisable to be well versed with basics such as variables, coefficients, equations, and basic calculus.
- Proficiency in programming basics: One should be comfortable reading and writing Python code including function definitions/invocations, loops, conditional statements, lists, etc.
- Basic knowledge of the following Python libraries:
- Numpy
- Pandas
- SciKit-Learn
- Matplotlib (and/or Seaborn)
The Semantic Tree
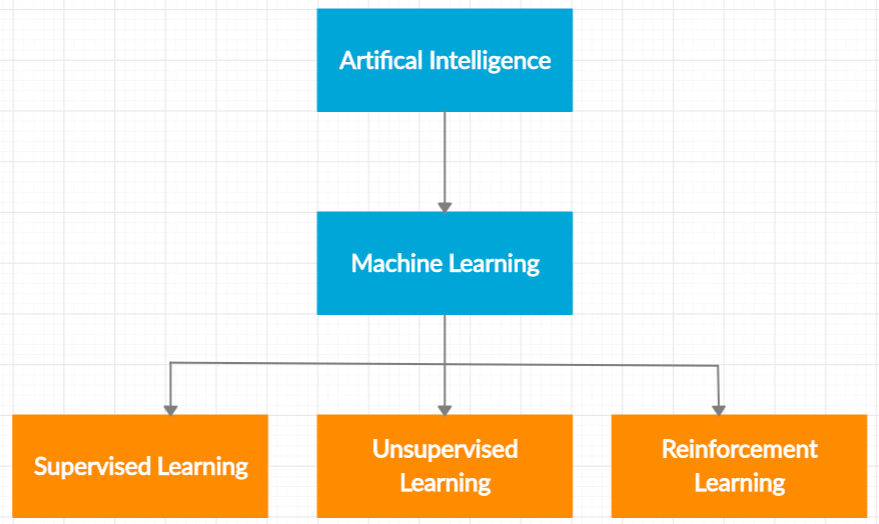
Artificial Intelligence may be defined as the study of agents that perceive the world around them, form plans, and make decisions to achieve their goals. A common mistake people often make is to use the terms AI and machine learning interchangeably.
Machine learning is a subfield of artificial intelligence. It enables computers to learn on their own and predict patterns in data without being explicitly programmed.
The following illustration provides a better intuition into what I just discussed.
What is Machine Learning?
Arthur Samuel described machine learning as: “The field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition that now holds little meaning.
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E concerning some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
In Layman's terms, machine learning is the idea that there can be generic algorithms that tell us interesting facts about a set of data without us having to write any custom code specific to a problem. Rather than writing code, we may feed the data to a generic algorithm and it devises its logic based on the data.
Machine learning algorithms may fall into one of the following three categories -
- Supervised Learning: A supervised learning algorithm functions on labeled data and makes predictions on new data. This can be either in the form of a classification problem or a regression problem.
- Unsupervised Learning: Unsupervised learning is when we are dealing with data that has not been labeled or categorized. The goal is to find patterns and create structure in data to derive meaning. these include clustering and dimensionality reduction.
- Reinforcement Learning: Reinforcement learning uses a reward system and trial-and-error to maximize the long-term reward.
Roadmap to begin with Machine Learning
As a freshman, I felt lost. I wished to explore ML as a field, but I could not find an end to begin with. The buzzwords seemed to intimidate me and I just could not get a start. But as I asked around and started reading more, it all started to make sense. Hence, I decided to form a basic roadmap of what all I followed, so nobody else has to feel the way I did.
- The best place to start is to learn (and/or) revise linear algebra. This should introduce you to all the core concepts of linear algebra such as matrices,vectors, etc., what I call the 'cogs' that make machine learning algorithms work.
- Calculus should be your next focus, as often there will be a need to play around with derivatives. Here you must focus on the meaning of derivatives, and how we can use them for optimization, as optimization is a big fragment of machine learning.
- Get thorough with Python libraries used in machine learning, mainly Numpy, Pandas, Matplotlib, and SKLearn. Machine learning without all these supporting libraries will be a tough task.
- Get your hands dirty! It is advisable to implement all algorithms from scratch yourself before using the models in SciKit - Learn, as it gives you a better and in-depth knowledge of how it works.
Some helpful resources to get started with Python:- Learning Python the hard way (book)
- The Python documentation
I did the algorithms in the following order of growing complexity, but you may start anywhere. Use cases for the same have also been explained:
-
Linear Regression - If 2 data points can be modeled in the form of a linear equation, then linear regression works the best. But the same fails if the equation moves to a higher order. For higher dimension equations, we then move onto polynomial regression. For example, total kilometers driven vs money spent on gas can be explained using linear regression.
-
Logistic Regression - Logistic regression, on the other hand, is the appropriate regression to conduct when we have a binary dependent variable. For example, to predict whether an email is a spam (1) or (0). Or, whether the tumor is malignant (1) or not (0).
-
Naive Bayes Classifier - As the name suggests, Naive Bayes classification is based on the famous Bayes's theorem and assumes the data to be 'naive,' that is, not correlated. It well suits models where we generatively classify over multiple classes. Its most popular use case is text classification and often works perfectly even with more scattered data.
-
K - Nearest Neighbors (KNN) - KNN classifier is a supervised lazy classifier, hence it is not used for real-time prediction. But, it gives us a much more complex decision boundary as it inherently optimizes locally. Here K refers to the number of nearest neighbors of a data point. It has wide-ranged use cases in credit faults.
-
K - Means - K-Means executes clustering which is the task of dividing the data points into several groups such that data points in the same groups are more similar to other data points in the same group than those in other groups. In simpler terms, it segregates groups with similar traits. Here, K refers to the number of centroids, which in turn decides the number of clusters formed.
-
Support Vector Machine (SVM) - SVM of Support Vector Machine is a supervised machine learning algorithm that is used for classification or regression problems. It uses a technique called the kernel trick to transform the data and finds an optimal boundary based on these transformations. It is used to capture much more complex relationships between the data points, that is, higher-order polynomial relationships.
-
Decision Trees - A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences. It is a flowchart like model where each internal node represents a conditional 'test' at each branch represents the outcome of the test, and each leaf node represents the decision taken in the form of a class label. Tree-based methods empower predictive models with high accuracy, stability, and ease of interpretation. Unlike linear models, they can also map non-linear relationships. Decision Tree algorithms are hence referred to as CART (Classification and Regression Trees).
-
Random Forests - Random Forest is quite similar to Decision Trees and is actually a collection of the latter. A decision tree is built on an entire dataset, whereas a random forest randomly selects specific features to generate multiple decision trees from and then averages their results. After a large number of trees are built, and classification is done via voting by each tree and the class that receives the most votes, is the predicted class.
-
Gradient Boosting - Gradient boosting is a machine learning technique for both regression and classification problems which produces a stronger prediction model based on an ensemble of weaker prediction models. This is the newest technique in the industry and is still being widely researched upon.
How to implement an ML algorithm?
After covering all the theoretical aspects of machine learning, I would advise you to start implementing that knowledge. Without practical application, machine learning loses its essence.
I decided to start with arguably the most famous algorithm, Linear Regression. As I implemented it on real-world data, it all started to make sense to me. And that feeling was incomparable, as I was witnessing a machine derive logic itself, and it began to find correlations between mere variables.
Starting from something so basic, I soon began playing around with other algorithms. I would read about them, whenever I could, and then try to implement them myself. And even before I knew, it started coming to me, naturally.
Here's a strategy that worked well for me:
- Get data to work on. There are millions of data sets available on the internet, catering to even the weirdest of your needs. One can also generate her/his data, pertaining to the problem at hand.
- Choose an algorithm. Once you have the data in a good place to work with it, you can start trying different algorithms. The official documentation provides a basic guide.
You can also refer to Joel Grus’s Github, where he has documented all the implementations from his book, “Data Science from Scratch”. - Visualise the data! This is my favorite step. Python has various libraries that help us plot and visualize the data and then the final result, to help us get a better intuition of your data and what you will be doing. (and of course, makes the model look fancy!)
- Tune the algorithm. All the models that we implement, have tons of buttons and knobs to play around with, better known as hyper-parameters. The learning rate, the k value, etc. all can be changed to get the best possible model.
- Evaluate the model. The Python library, SKLearn provides a lot of tools to evaluate your model and check for metrics such as accuracy, f1 score, precision, etc. This is the most important step, as, without proper evaluation of the model, we can never be sure of its performance and in real life, there is a lot at stake.
Side notes
- Once you are familiar with a few concepts, start with a mini-project that is not super complex (to begin with).
- Don’t be afraid to fail. Many a times, hours or even days will be spent trying to figure out the math, or how and why an error popped up. But, tenacity is key. Sooner or later, you will find your way around it, so cheer up!
- If you really wish to dive deep into machine learning then I would recommend you to start with any one of the following :
- Andrew Ng’s Machine Learning course on Coursera (free, easier)
- CS-229 course, taught at Stanford University (free, relatively tougher, complex math)
This is my very first article here, and I would love to hear from you all and collaborate upon something with an impact. Stay safe and thank you for reading!
External references
-
Python libraries:
- Numpy
- Pandas
- SciKit-Learn
- Matplotlib (and/or Seaborn)
-
MIT open courseware:
-
Python 3.6 documentation
-
Best sources for datasets:
-
Courseware:
-
SK Learn's guide to choosing algorithms
Go on to master Machine Learning.