
In machine learning, classification problems are very common. We know that the classification problem is all about predicting a class label by studying the input data of predictors, and the output or target variable is categorical in nature. One such problem is- Imbalanced data problem, which is that instances of the target class labels’ numbers of observation is significantly lower than other class labels.
Table of contents:
- What is imbalanced data ?
- Real-life application of Imbalanced data
- Example of a dataset with an imbalanced class
- Problems with imbalanced data classification
- Techniques for handling imbalanced classes
- Downsampling and Upweighting techniques
- Conclusion
What is imbalanced data ?
When a dataset's distribution of classes is uneven, it is said to have imbalanced data. In other words, compared to the other classes, one class has significantly more or fewer samples. This can be a problem because most machine learning algorithms are made to function best with balanced data, which means that there are roughly equal numbers of samples for each class.
Because it has more samples from which to learn in the case of unbalanced data, the algorithm may end up being biased in favour of the majority class. Poor performance on the minority class, which is important in many applications, may result from this. In the event that a particular group of people is underrepresented in a field, it may result in a reduction in the effectiveness of the field.
There are a number of methods that can be used to address the problem of imbalanced data. Resampling the data, either by oversampling the minority class or undersampling the majority class, is a common strategy. Another strategy is to employ specialized algorithms, such as those that employ ensemble methods or cost-sensitive learning, that are created to function with unbalanced data. Utilizing appropriate evaluation metrics that account for the class imbalance, such as precision, recall, and F1-score, is also crucial.
Real-life application of Imbalanced data
Assume that "A" is a bank that provides its clients with credit cards. The bank is now worried that some fraudulent transactions are occurring, and when the bank checked their data, they discovered that there were only 30 fraud cases recorded for every 2000 transactions. Therefore, less than 2% of transactions are fraudulent, or more than 98% of transactions are "No Fraud" in nature. The class "No Fraud" in this instance is referred to as the majority class, while the much smaller class "Fraud" is referred to as the minority class.
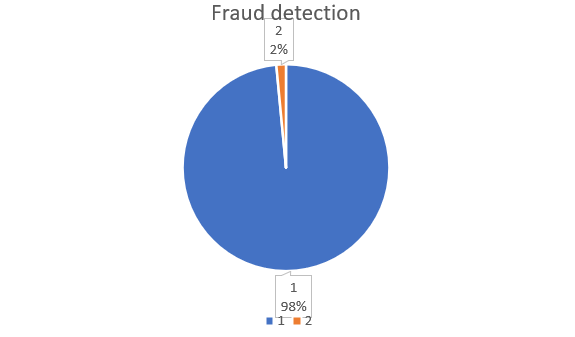
Example of a dataset with an imbalanced class
- Creating a skewed dataset:
from sklearn.datasets import make_classification
from collections import Counter
# generate an imbalanced classification dataset
X, y = make_classification(n_samples=1000, n_classes=2, weights=[0.9, 0.1], random_state=1)
# summarize the distribution of classes
counter = Counter(y)
print(counter)
- We generate an imbalanced classification dataset with 1000 samples, two classes, and a weight ratio of 0.9 to 0.1 between the majority and minority classes. The Counter function is then used to count the number of samples for each class, which prints out the following result:
Counter({0: 905, 1: 95})
This shows that the majority class has 905 samples, while the minority class has only 95 samples, making it an imbalanced class problem.
Problems with imbalanced data classification
The Problems with imbalanced data classification are:
- Biased models
- Poor predictive performance
- Over-fitting
- False evaluation metrics
We will dive into each problem deeper.
-
Biased models: If classes are unbalanced, the machine learning model may end up favoring the dominant class. This indicates that the model may perform well for the majority class while being inaccurate for the minority class.
-
Poor predictive performance: Imbalanced classes can cause the minority class to perform poorly in predictions, which is important in many applications. For instance, if the minority class in fraud detection is fraud cases, the model's failure to catch them can result in sizable financial losses.
-
Over-fitting: The machine learning model may over-fit to the dominant class when the classes are unbalanced. This indicates that while the model may adequately fit the majority class, it may not translate well to fresh data.
-
False evaluation metrics: When classes are unbalanced, conventional evaluation metrics like accuracy may not be appropriate. A model that consistently predicts the majority class, for instance, may have high accuracy but perform poorly when predicting the minority class.
To address these problems, it's important to use appropriate techniques that can handle imbalanced classes, such as resampling, using specialized algorithms, or using appropriate evaluation metrics.
Techniques for handling imbalanced classes
The different techniques for handling imbalanced classes are:
- Resampling
- Cost-sensitive
- Making use of specialized algorithms
- Ensemble techniques
- Using appropriate evaluation metrics
We will dive into each technique further.
-
Resampling: The classes in the dataset can be balanced using resampling. To achieve balance, one can either oversample the minority class or undersample the majority class. Undersampling methods include random undersampling, Tomek links, and edited nearest neighbours. Oversampling methods include random oversampling, SMOTE (Synthetic Minority Over-sampling Technique), and ADASYN (Adaptive Synthetic Sampling).
-
Cost-sensitive learning involves allocating various classes with various costs of misclassification. This strategy might persuade the model to pay more attention to the minority class.
-
Making use of specialized algorithms: Some algorithms are made to deal with unequal classes. Decision trees, random forests, and gradient boosting are a few examples.
-
Ensemble techniques: To enhance the model's performance on the minority class, ensemble techniques like bagging and boosting can be used.
-
Using appropriate evaluation metrics: If the classes are imbalanced, accuracy might not be the best evaluation metric to use. The model's performance on both classes can be assessed using metrics like precision, recall, F1-score, and ROC AUC.
Here is an example of using Python and scikit-learn to balance the classes in an unbalanced dataset using SMOTE:
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
from collections import Counter
# generate an imbalanced classification dataset
X, y = make_classification(n_samples=1000, n_classes=2, weights=[0.9, 0.1], random_state=1)
# summarize the distribution of classes
counter = Counter(y)
print(counter)
# apply SMOTE to balance the classes
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
# summarize the new distribution of classes
counter = Counter(y)
print(counter)
Here, with 1000 samples, two classes, and a weight ratio of 0.9 to 0.1 between the majority and minority classes, we first create an unbalanced classification dataset in this example. The minority class is then oversampled using the SMOTE algorithm to balance the classes. The Counter function is then used to count the samples for each class both before and after SMOTE.
Downsampling and Upweighting techniques
Downsampling: Reducing the number of samples or data points in a dataset by selecting a random subset of them is known as downsampling. When there is an imbalance in the classes of the data or when there are insufficient computational resources, this technique is frequently used.
For instance, downsampling the majority class can balance the number of samples between the two classes in a binary classification problem where the majority class has significantly more samples than the minority class. This will enhance the performance of the machine learning algorithm. Downsampling should only be used after a thorough analysis of the dataset because it also has the potential to discard important information from the data.
Upweighting: Upweighting in machine learning is the process of giving specific data points or samples in a dataset a higher weight or importance. When the data are unbalanced—that is, when one class of the data is significantly underrepresented relative to another class—this technique is frequently used.
Upweighting can also be used in other situations, such as when specific data characteristics or data points are more crucial for the task at hand than others. But it's crucial to carefully consider the justifications for upweighting as well as any possible effects it might have on the model's performance.
Conclusion
Imbalanced classes can result in a number of issues with machine learning, such as biased models, inferior predictive performance, overfitting, and inaccurate evaluation metrics. It's crucial to employ the right techniques, such as resampling, cost-sensitive learning, specialized algorithms, ensemble methods, and suitable evaluation metrics, to address these issues.
While cost-sensitive learning involves allocating various misclassification costs to various classes, resampling techniques such as oversampling or undersampling can be used to balance the classes. Unbalanced classes can be handled by specialized algorithms like gradient boosting, random forests, and decision trees. The model's performance on the minority class can be enhanced by ensemble techniques like bagging and boosting.
Finally, to assess the model's performance across both classes, appropriate evaluation metrics like precision, recall, F1-score, and ROC AUC should be used.