
Merkle tree is named after Ralph Merkle, it is a tree data structure where non-leaf nodes are a hash of its child nodes and leaf nodes are a hash of a block of data. It has a branching factor of 2 (it can have a maximum of 2 children). Merkel trees allow efficient and secure verification of the contents of a large data structure.
Note: Merkle Tree is a USPTO patented Algorithm/ Data Structure and hence, you cannot use it in production without permission or by paying royality to Ralph Merkle. Merkle Tree is also known as Hash Tree.
Table of contents:
- How does Merkle tree work?
- Structure of the node of binary Merkle tree
- Find operation in Merkle tree
- Add operation in Merkle tree
- Delete a node from merkle tree
- Time and Space complexity of Merkle Tree
- Why is Merkle tree better than binary tree?
- Applications of Merkle tree
- Why Merkle tree is used in blockchain?
- How Merkle tree is used in Git?
How does Merkle tree work?
Merkel tree is also called as hash tree. To better understand Merkle tree, we need to first understand how hash functions work.
Hash functions
hash function is a function that takes a set of inputs and maps them into a table or data structure. The output generated by hash function is unique for every input. This helps in fingerprinting of data. The hash functions vary from one application to another.
Merkle tree representation
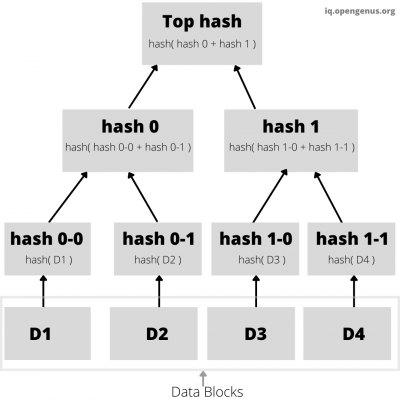
As you can see in the above image, The data is broken up into blocks D1, D2, D3 and D4. These blocks are hashed using hash functions. Then each pair of nodes are hashed recursively until we reach the root node. Hash 0-0 contains the hash of D1 and hash 0-1 contains the hash of D2. Hash 0 contains hash of the sum of its children( hash(hash 0-0 + hash 0-1)). Similarly, all non-leaf nodes are a hash of their child nodes and the root node contains the hash of all nodes below it.
Structure of the node of binary Merkle tree
It contains four variables:
- It contains a key variable.
- It contains value variable
- It contains two links.
Implementing the structure of the node.
struct node
{
int key;
int value;
struct node *left;
struct node *right;
};Find operation in Merkle tree
This function is used to check whether the given key is present in the merkle tree or not. If it is present then it will return that node else it will return null. This function is used to retrieve data from Git. When we commit a change to a repository in git. Git computes SHA-1 ( SHA-1 produces a 160-bit hash value from an arbitrary length string) over the contents of that directory tree and stores them with metadata. It is stored in .git/objects and gives you back the unique key that now refers to that data object. You can use this key to retrieve the data.
git cat-file -p key
This command can be used to display the contents of the data object that this key refers to.
Algorithm of find function in Merkle tree
Step 1: We will take tree and key as parameters.
Step 2: If the tree is null then we will return null.
Step 3: If the tree->key is equal to the key we will return the tree.
Step 4: If the key is smaller than tree->key then we will return find(tree->left, key)
Step 5: else return find(tree->right, key)
Implementing find function
/* this function finds the given key in the Binary Tree*/
struct node* find(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (tree->key == key)
{
return tree;
}
else if (key < tree->key)
{
return find(tree->left, key);
}
else
{
return find(tree->right, key);
}
}Add operation in Merkle tree
This function is used to add a node into the merkle tree. This function is used to insert source code into a git repository. When we commit a change to a repository. Git computes SHA-1 over the contents of that directory tree and stores them with metadata. The metadata includes information such as pointer to parent commit and a commit message as a commit object.
We will create a structure called binary_tree. It contains a pointer to a node called head.
struct binary_tree
{
/* head pointing to the root of Binary Tree */
struct node *head;
};We will create a pointer called arr of datatype binary_tree.
struct binary_tree *arr;
Algorithm to add a node in Merkle tree.
Step 1: We will take key and value as parameters.
Step 2: Take the hash(key) and store it in a variable called index.
Step 3: store (struct node*) arr[index].head in a pointer called tree of datatype node.
Step 4: create a new node with its key as key and value as value and both links as null.
Step 5: If the tree is null then assign the new node to the head and increment the size by 1.
Step 6: If the tree is not null then we will check if the key is already present in the tree using the find function.
Step 7: If the key is already present in the tree then we will update the value.
Step 8: If it is not present in the tree then we will use the insert function to insert the element.
Algorithm of insert function.
Step 1: It will take tree and item pointers of node data type as parameters.
Step 2: If item->key is smaller than tree->key and tree->left is null then assign the item to tree->left.
Step 3: If item->key is smaller than tree->key and tree->left is not null then call insert function with tree->left and item as parameters.
Step 4: If item->key is greater than tree->key and tree->right is null then assign the item to tree->right.
Step 5: If item->key is greater than tree->key and tree->right is not null then call insert function with tree->right and item as parameters.
Algorithm implementing add node function.
//hash function that takes a key as its parameter.
int hash(int key)
{
return (key % maxim);
}
/* this function inserts the newly created node
in the existing Binary Tree */
void insert_element(struct node *tree,
struct node *item)
{
if (item->key < tree->key)
{
if (tree->left == NULL)
{
tree->left = item;
return;
}
else
{
insert_element(tree->left, item);
return;
}
}
else if (item->key > tree->key)
{
if (tree->right == NULL)
{
tree->right = item;
return;
}
else
{
insert_element(tree->right, item);
return;
}
}
}
/* this function finds the given key in the Binary Tree*/
struct node* find(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (tree->key == key)
{
return tree;
}
else if (key < tree->key)
{
return find(tree->left, key);
}
else
{
return find(tree->right, key);
}
}
//function that adds a node in merkle tree.
void add(int key, int value)
{
int index = hash(key);
struct node *tree = (struct node*) arr[index].head;
/* creating an item to insert in the hashTree */
struct node *item = (struct node*)
malloc(sizeof(struct node));
item->key = key;
item->value = value;
item->left = NULL;
item->right = NULL;
if (tree == NULL)
{
/* absence of Binary Tree at a given
index of Hash Tree */
arr[index].head = item;
size++;//incrementing size
}
else
{
/* a Binary Tree is present at given index
of Hash Tree */
struct node *temp = find(tree, key);
if (temp == NULL)
{
/* Key not found in existing Binary Tree.*/
insert_element(tree, item);
size++;
}
else
{
/* Key already present in existing Binary Tree
Updating the value of already existing key
*/
temp->value = value;
}
}
}
Delete a node from merkle tree
This function is used to delete a node from Merkle tree. If the key given is present in the merkle tree then it will delete the node from the tree. Git remembers all the files you have staged and stores them in a tree structure inside the commit. The nodes of this tree represent your files and directories. This function is used to delete these nodes.
Algorithm to delete a node in Merkle tree.
Step 1: We will take a key as a parameter.
Step 2: Take the hash(key) and store it in a variable called index.
Step 3: store (struct node*) arr[index].head in a pointer called tree of datatype node.
Step 4: If the tree is null then the key is not present.
Step 5: If the tree is not null then we will check if the key is already present in the tree using the find function.
Step 6: If the find function returns null then the key is not present in the tree.
Step 7: If it is not null then we will use the remove function to delete the element.
Algorithm of remove function.
Step 1: It will take tree and key as parameters.
Step 2: If the tree is null then return null.
Step 3: If the key is smaller than the tree->key then tree->left is equal to remove(tree->left, key) and return tree.
Step 4: If the key is greater than the tree->key then tree->right is equal to remove(tree->right, key) and return tree.
Step 5: else if the tree->left is equal to null and the tree->right is equal to null then decrement the size and return tree->left.
Step 6: else if the tree->left is not equal to null and the tree->right is equal to null then decrement the size and return tree->left.
Step 7: else if tree->left is equal to null and tree->right is not equal to null then decrement the size and return tree->right.
Step 8: else assign tree->left to a pointer called left of data type node.
Step 9: While left->right is not equal to null, left is equal to left->right.
Step 10: tree->key is equal to left->key.
Step 11: tree->value is equal to left->value.
Step 12: tree->left is equal to remove(tree->left, tree->key).
Step 13: Return tree.
Implementing delete function.
//hash function that takes a key as its parameter.
int hash(int key)
{
return (key % maxim);
}
/* this function finds the given key in the Binary Tree*/
struct node* find(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (tree->key == key)
{
return tree;
}
else if (key < tree->key)
{
return find(tree->left, key);
}
else
{
return find(tree->right, key);
}
}
void delete(int key)
{
int index = hash(key);
struct node *tree = (struct node*)arr[index].head;
if (tree == NULL)
{
cout << key << " Key is not present" << endl;
}
else
{
struct node *temp = find(tree, key);
if (temp == NULL)
{
cout << key << " is not present";
}
else
{
tree = remove_element(tree, key);
}
}
}
struct node* remove(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (key < tree->key)
{
tree->left = remove(tree->left, key);
return tree;
}
else if (key > tree->key)
{
tree->right = remove(tree->right, key);
return tree;
}
else
{
/* reached the node */
if (tree->left == NULL && tree->right == NULL)
{
size--;
return tree->left;
}
else if (tree->left != NULL && tree->right == NULL)
{
size--;
return tree->left;
}
else if (tree->left == NULL && tree->right != NULL)
{
size--;
return tree->right;
}
else
{
struct node *left= tree->left;
while (left->right != NULL)
{
left= left->right;
}
tree->key = left->key;
tree->value = left->value;
tree->left = remove(tree->left, tree->key);
return tree;
}
}
}
Implementing Merkle tree.
- C++
C++
#include<bits/stdc++.h>
using namespace std;
/* determines the maximimum capacity of Hash Tree */
int maxim = 20;
/* determines the number of elements present in Hash Tree */
int size = 0;
struct node
{
int key;
int value;
struct node *left;
struct node *right;
};
struct binary_tree
{
/* head pointing to the root of Binary Tree */
struct node *head;
};
struct binary_tree *arr;
//hash function that takes a key as its parameter.
int hashvalue(int key)
{
return (key % maxim);
}
/* this function inserts the newly created node
in the existing Binary Tree */
void insert_element(struct node *tree,
struct node *item)
{
if (item->key < tree->key)
{
if (tree->left == NULL)
{
tree->left = item;
return;
}
else
{
insert_element(tree->left, item);
return;
}
}
else if (item->key > tree->key)
{
if (tree->right == NULL)
{
tree->right = item;
return;
}
else
{
insert_element(tree->right, item);
return;
}
}
}
/* this function finds the given key in the Binary Tree*/
struct node* find(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (tree->key == key)
{
return tree;
}
else if (key < tree->key)
{
return find(tree->left, key);
}
else
{
return find(tree->right, key);
}
}
//function that adds a node in merkle tree.
void add(int key, int value)
{
int index = hashvalue(key);
struct node *tree = (struct node*) arr[index].head;
/* creating an item to insert in the hashTree */
struct node *item = (struct node*)malloc(sizeof(struct node));
item->key = key;
item->value = value;
item->left = NULL;
item->right = NULL;
if (tree == NULL)
{
/* absence of Binary Tree at a given
index of Hash Tree */
arr[index].head = item;
size++;//incrementing size
}
else
{
/* a Binary Tree is present at given index
of Hash Tree */
struct node *temp = find(tree, key);
if (temp == NULL)
{
/* Key not found in existing Binary Tree.*/
insert_element(tree, item);
size++;
}
else
{
/* Key already present in existing Binary Tree
Updating the value of already existing key
*/
temp->value = value;
}
}
}
/* displays content of binary tree of
particular index */
void display_tree(struct node *tree)
{
if (tree == NULL)
{
return;
}
cout << tree->key << " and " <<
tree->value << " ";
if (tree->left != NULL)
{
display_tree(tree->left);
}
if (tree->right != NULL)
{
display_tree(tree->right);
}
}
/* displays the content of hash Tree */
void display()
{
int i = 0;
for(i = 0; i < maxim; i++)
{
struct node *tree = arr[i].head;
if (tree == NULL)
{
cout << "arr[" << i << "] has no elements" << endl;
}
else
{
display_tree(tree);
}
}
}
void init()
{
int i = 0;
for(i = 0; i < maxim; i++)
{
arr[i].head = NULL;
}
}
/* returns the size of hash Tree */
int size_of_hashTree()
{
return size;
}
struct node* remove(struct node *tree, int key)
{
if (tree == NULL)
{
return NULL;
}
if (key < tree->key)
{
tree->left = remove(tree->left, key);
return tree;
}
else if (key > tree->key)
{
tree->right = remove(tree->right, key);
return tree;
}
else
{
/* reached the node */
if (tree->left == NULL && tree->right == NULL)
{
size--;
return tree->left;
}
else if (tree->left != NULL && tree->right == NULL)
{
size--;
return tree->left;
}
else if (tree->left == NULL && tree->right != NULL)
{
size--;
return tree->right;
}
else
{
struct node *left= tree->left;
while (left->right != NULL)
{
left= left->right;
}
tree->key = left->key;
tree->value = left->value;
tree->left = remove(tree->left, tree->key);
return tree;
}
}
}
void delete_element(int key)
{
int index = hashvalue(key);
struct node *tree = (struct node*)arr[index].head;
if (tree == NULL)
{
cout << key << " Key is not present" << endl;
}
else
{
struct node *temp = find(tree, key);
if (temp == NULL)
{
cout << key << " is not present";
}
else
{
tree = remove(tree, key);
}
}
}
int main()
{
int choice, key, value, n, c;
arr = (struct binary_tree *)malloc(maxim *sizeof(struct binary_tree*));
init();
do
{
cout <<"1.Insert an item in the Hash Tree"
"\n2.Remove an item from the Hash Tree"
"\n3.Check the size of Hash Tree"
"\n4.Display Hash Tree"
"\n\n Please enter your choice-:";
cin >> choice;
switch(choice)
{
case 1:
cout << "Enter key and value-: ";
cin >> key >> value;
add(key, value);
break;
case 2:
cout << "\n Enter the key to delete-:";
cin >> key;
delete_element(key);
break;
case 3:
n = size_of_hashTree();
cout << "Size of Hash Tree is-:" << n << endl;
break;
case 4:
display();
break;
default:
cout << "Wrong Input" << endl;
}
cout << "\n Do you want to continue-: (press 1 for yes) ";
cin >> c;
}while(c == 1);
return 0;
}
Time and Space complexity of Merkle Tree
- The time complexity for searching is
O(log n)because the time complexity for searching in a binary tree isO(log n). - The time complexity for insertion is
O(log n). - The time complexity for deletion is
O(log n). - The space complexity is
O( n ).
Why is Merkle tree better than binary tree?
- It provides both integrity and validity of data.
- The memory needed to store the data is significantly reduced.
- It only needs small amounts of information to be transmitted across networks
- It provides a way of verifying transactions in a block without downloading an entire block.
Applications of Merkle tree
- Apache Cassandra uses Merkle Trees to detect inconsistencies.
- Git uses a merkle tree to store its data.
- Ethereum uses a Merkle Patricia Trie.
- It is a fundamental part of the blockchain.
Why Merkle tree is used in blockchain?
A blockchain is comprised of various blocks that are linked with one another, hence the name blockchain. Merkle tree stores the blockchain data in an efficient and secure way. It can verify blockchain data very quickly. It also provides quick movement of large amounts of data from one computer node to the other blockchain network.
Every transaction that occurs on the blockchain network has a hash associated with it. These hashes are stored in the form of a tree-like structure such that each hash is linked to its parent. Since numerous transactions are stored on a particular block. All the transaction hashes that are present in the block are also hashed, which results in a Merkle root.
How Merkle tree is used in Git?
At the core, git is a simple key-value data store. One of the main data structures of git is an object store. It contains all the data files, log messages and other information required to rebuild the branch of the project. There are four different types of objects:
- blob
- tree
- commit
- tag.
Git stores these different types of objects in .git/objects.
Blobs: blobs are binary streams of data and do not store anything but its contents.
Trees: A tree is basically like a directory- it references a bunch of other trees and blobs.
Commit: It holds metadata for each change made in the repository, including committer, commit-data, and log- messages.
Tag: A tag object assigns an arbitrary human-readable name to a specific object usually a commit.
Every blob, tree, and commit is a hashed object. If you want to refer to a specific object then you must know its hash.
When you make a commit in git, a commit id is generated using SHA-1. The commit ID of each commit is the hash of that commit object. This hash is calculated from all of the data that makes up that commit, including
- File changes included in the commit
- File names of the committed files
- Commit message
- Parent commit ID
Because the complete contents of an object contribute to the hash value and the hash value is believed to be effectively unique to that particular content, the SHA1 hash is a sufficient index or name for that object in the object database. Any tiny change to a file causes the SHA1 hash to change, causing the new version of the file to be indexed separately.
These tasks can be accomplished using the Merkle tree data structure.
With this article at OpenGenus, you must have a strong idea of Merkle Tree and how it is used in BlockChain and Git.