
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have explained Multithreading in Python Programming Language in depth along code examples.
Table of Contents
- Introduction
- Code
- Complexity
- Applications
- Questions
- Conclusion
Introduction
-
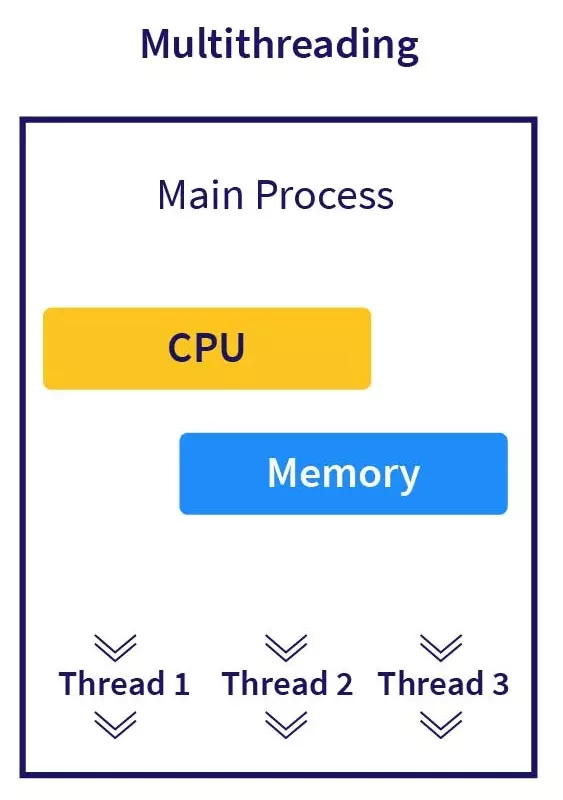
Multithreading is a technique that allows a program to perform multiple tasks concurrently within a single process. In Python, the threading module provides a way to create and manage threads.
-
A thread is a separate flow of execution within a process. Each thread has its own stack and program counter, but shares memory and other resources with other threads in the same process. This allows threads to communicate and share data with each other more easily than if they were separate processes.
-
In this guide, we will explore the basics of multithreading in Python and learn how to create and manage threads. We will also discuss some common applications of multithreading and look at some techniques for avoiding synchronization issues.
Code
- Here’s an example of how to create and start a thread in Python:
import threading
def my_function():
print("Hello from thread!")
my_thread = threading.Thread(target=my_function)
my_thread.start()
In this example, we define a function my_function that simply prints a message. We then create a thread object by calling threading.Thread and passing the function as the target argument. Finally, we start the thread by calling its start method.
- Here’s an explanation of the code provided, line by line:
import threading
This line imports the threading module, which provides a way to create and manage threads in Python.
def my_function():
print("Hello from thread!")
This defines a function called my_function that simply prints a message when it is called.
my_thread = threading.Thread(target=my_function)
This line creates a new thread object and assigns it to the variable my_thread. The target argument specifies the function that the thread should run when it is started. In this case, we pass my_function as the target, so the thread will run that function when it is started.
my_thread.start()
This line starts the thread by calling its start method. When the thread is started, it will call the my_function function and print the message “Hello from thread!”.
Examples to illustrate the use of multi-threading
Matrix Multiplication
- Below code example demonstrates how to use multi-threading for matrix multiplication. The function multiply_matrices takes two matrices as input and returns their product. It does this by creating a new matrix of zeros with the same shape as the product matrix, and then creating a new thread for each element in the product matrix. Each thread calls the function multiply_row_column, which takes a row index, column index, and result matrix as input, and computes the dot product of the corresponding row in the first matrix and column in the second matrix. The result is stored in the result matrix.
import numpy as np
import threading
def multiply_row_column(row, column, result_matrix):
result_matrix[row][column] = np.dot(matrix1[row], matrix2[:, column])
def multiply_matrices(matrix1, matrix2):
result_matrix = np.zeros((matrix1.shape[0], matrix2.shape[1]))
threads = []
for i in range(matrix1.shape[0]):
for j in range(matrix2.shape[1]):
thread = threading.Thread(target=multiply_row_column, args=(i, j, result_matrix))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return result_matrix
matrix1 = np.array([[1, 2], [3, 4]])
matrix2 = np.array([[5, 6], [7, 8]])
result_matrix = multiply_matrices(matrix1, matrix2)
print(result_matrix)
- Here’s an explanation of the code provided, line by line:
import numpy as np: This line imports the NumPy library and gives it the alias np.
import threading: This line imports the threading module.
def multiply_row_column(row, column, result_matrix):: This line defines a function called multiply_row_column that takes a row index, column index, and result matrix as input. It computes the dot product of the corresponding row in the first matrix and column in the second matrix and stores the result in the result matrix.
def multiply_matrices(matrix1, matrix2):: This line defines a function called multiply_matrices that takes two matrices as input and returns their product. It creates a new matrix of zeros with the same shape as the product matrix and then creates a new thread for each element in the product matrix. Each thread calls the function multiply_row_column to compute the corresponding element. The result is stored in the result matrix.
matrix1 = np.array([[1, 2], [3, 4]]): This line creates a NumPy array representing the first matrix.
matrix2 = np.array([[5, 6], [7, 8]]): This line creates a NumPy array representing the second matrix.
result_matrix = multiply_matrices(matrix1, matrix2): This line calls the function multiply_matrices to compute the product of the two matrices and stores the result in a new variable called result_matrix.
print(result_matrix): This line prints out the resulting product matrix.
Vector Scalar Multiplication
- Below code example demonstrates how to use multi-threading for vector scalar multiplication. The function multiply_vectors_scalars takes two lists of vectors and scalars as input and returns their element-wise product. It does this by creating a new thread for each vector-scalar pair, which calls the function multiply_vector_scalar, which takes a vector and scalar as input and returns their product.
import numpy as np
import threading
def multiply_vector_scalar(vector, scalar):
return vector * scalar
def multiply_vectors_scalars(vectors, scalars):
result_vectors = []
threads = []
for i in range(len(vectors)):
thread = threading.Thread(target=multiply_vector_scalar, args=(vectors[i], scalars[i]))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return result_vectors
vectors = [np.array([1, 2]), np.array([3, 4])]
scalars = [5, 6]
result_vectors = multiply_vectors_scalars(vectors, scalars)
print(result_vectors)
- Here’s an explanation of the code provided, line by line:
import numpy as np: This line imports the NumPy library and gives it the alias np.
import threading: This line imports the threading module.
def multiply_vector_scalar(vector, scalar):: This line defines a function called multiply_vector_scalar that takes a vector and scalar as input and returns their product.
def multiply_vectors_scalars(vectors, scalars):: This line defines a function called multiply_vectors_scalars that takes two lists of vectors and scalars as input and returns their element-wise product. It creates a new thread for each vector-scalar pair and calls the function multiply_vector_scalar to compute their product. The result is stored in a new list called result_vectors.
vectors = [np.array([1, 2]), np.array([3, 4])]: This line creates a list of NumPy arrays representing vectors.
scalars = [5, 6]: This line creates a list of scalars.
result_vectors = multiply_vectors_scalars(vectors, scalars): This line calls the function multiply_vectors_scalars to compute the element-wise product of the two lists of vectors and scalars. The result is stored in a new list called result_vectors.
-
Multithreading can be used to improve the performance of certain types of programs by allowing them to do multiple things at once. For example, if you have a program that needs to download multiple files from the internet, you could use multithreading to download several files at the same time.
-
However, multithreading can also introduce complexity into your programs. When multiple threads are running concurrently, you need to be careful to avoid race conditions and other synchronization issues.
Complexity
-
One of the challenges of using multithreading is dealing with the complexity that it introduces. When multiple threads are running concurrently, you need to be careful to avoid race conditions and other synchronization issues.
-
A race condition occurs when the behavior of a program depends on the timing of events, such as the order in which threads are scheduled to run. If two threads access shared data concurrently, and at least one of them modifies the data, a race condition can occur.
-
To avoid race conditions, you can use various synchronization mechanisms such as locks, semaphores, and conditions. These mechanisms allow you to control the order in which threads access shared data and ensure that only one thread accesses the data at a time.
-
Here’s an example that shows how to use a lock to protect a shared counter:
import threading
counter = 0
counter_lock = threading.Lock()
def increment_counter():
global counter
with counter_lock:
counter += 1
threads = [threading.Thread(target=increment_counter) for _ in range(10)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(counter)
In this example, we create a global variable counter and a lock object counter_lock. The increment_counter function increments the counter, but only after acquiring the lock. This ensures that only one thread can access the counter at a time.
- Here’s an explanation of the code provided, line by line:
import threading
This line imports the threading module, which provides a way to create and manage threads in Python.
counter = 0
This line creates a global variable called counter and initializes it to 0.
counter_lock = threading.Lock()
This line creates a lock object and assigns it to the variable counter_lock. A lock is a synchronization mechanism that can be used to ensure that only one thread can access a shared resource at a time.
def increment_counter():
global counter
with counter_lock:
counter += 1
This defines a function called increment_counter that increments the global counter variable. The function uses the with statement to acquire the lock before accessing the counter variable. This ensures that only one thread can access the counter variable at a time.
threads = [threading.Thread(target=increment_counter) for _ in range(10)]
This line creates a list of 10 thread objects. Each thread is created with the increment_counter function as its target, so when the threads are started, they will each call that function.
for thread in threads:
thread.start()
This loop starts all of the threads by calling their start method.
for thread in threads:
thread.join()
This loop waits for all of the threads to finish by calling their join method. The join method blocks until the thread has completed.
print(counter)
Finally, this line prints the value of the counter variable. Since each of the 10 threads increments the counter once, the final value should be 10.
Applications
- Some common applications of multithreading in Python include:
- Performing multiple tasks concurrently (e.g., downloading files)
- Improving the responsiveness of GUI applications
- Speeding up CPU-bound tasks by taking advantage of multiple cores
Questions
- What is multithreading?
- How do you create and start a thread in Python?
- What are some common applications of multithreading in Python?
- What is a race condition?
- How can you avoid race conditions in multithreaded programs?
Conclusion
-
In conclusion, multithreading is a powerful tool that can help you improve the performance and responsiveness of your Python programs. By allowing multiple threads to run concurrently within a single process, you can perform multiple tasks at the same time and take advantage of multiple cores.
-
However, multithreading also introduces complexity into your programs. When using multithreading, you need to be careful to avoid race conditions and other synchronization issues. By using synchronization mechanisms such as locks, semaphores, and conditions, you can control the order in which threads access shared data and ensure that your programs behave correctly.