
Reading time: 30 minutes
The paper (Few-Shot Adversarial Learning of Realistic Neural Talking Head Models) is one of the most challenging and exciting Machine Learning papers to read. I hope to do justice with explaining this paper in this post, so that it becomes a little easy to read and understand.
It has been a work by researchers (Egor Zakharov, Aliaksandra Shysheya, Egor Burkov and Victor Lempitsky) from Samsung AI Center, Moscow and Skolkovo Institute of Science and Technology. This is the paper: Few-Shot Adversarial Learning of Realistic Neural Talking Head Models which you may read.
We all are familiar with the advancements made in the field of Deep Fakes, which is basically creation of fake photos or videos of humans using neural networks. The only issue with such tasks is that they require a large amount of training data, however, in practical cases, we might want the personalized talking head models to learn from only a few image views of a person.
This is what the paper mentioned here resolves. A team of researchers at Samsung AI has figured out how to create realistic talking heads from as little as a single portrait photo.
Following is the most interesting application of this technique of creating a moving video of the popular picture Monalisa:

Let's discuss their approach briefly:
The first step was to extract the landmarks of the face images, for which an off the shelf face landmark tracker has been used on a set of 8 frames of the same person. These models work just as well for different angles of the images, originally absent in the training dataset.
This system works for different set of frames, starting right from just 1 frame, which implies that one shot learning has also been achieved by this system.
The Meta Learning Stage
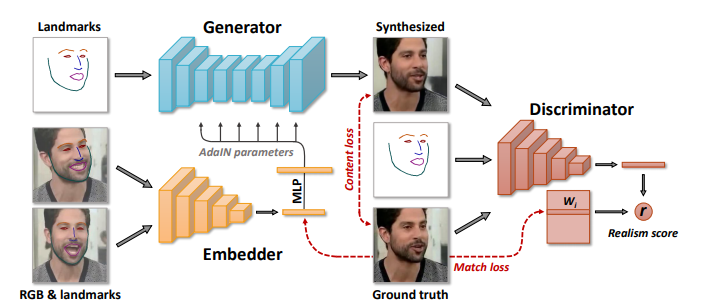
The work described in this paper owes its success to this meta learning stage which uses the following 3 networks:
- Embedder network
- Generator
- Discriminator
The Embedder network maps the frames concatenated with the face landmarks into vectors which are further used to initialize the parameters of layers inside the generator network which maps landmarks into the synthesized videos. The discriminator then assesses the identity preservation in the generated videos and a realism score is calculated based on that.
Few-shot learning model
After the meta learning stage, fine tuning was performed on generator and discriminator networks, and even though there were millions of parameters, the fine tuning was successful with a just a few images because of the meta learning stage. This makes learning quick and possible with only a few images, without compromising on the realism or personalization score.
In depth explanation of this technique
Architecture of networks used in meta learning stage:
-
The Embedder Network: It takes video frames and associated landmark images with it, and then with the help of network parameters learned, it generates a vector containing video specific information such as person's identity. Such type of information is invariant to the pose and mimics in a particular frame.
-
The Generator: It takes the landmark image for the video frame not seen by the embedder, the predicted video embedding from embedder, and outputs a synthesized video frame. The generator is trained to maximize the similarity between its outputs and the ground truth frames.
-
The Discriminator: It contains Convolutional Neural Networks that maps the input frame and the landmark image into a vector. The discriminator predicts a realism score (r), that indicates whether the input frame is a real frame of a particular video sequence and whether it matches the input pose, based on the output of its ConvNet part and the learned parameters.
Meta Learning Stage
In this stage, the parameters of all the three networks are trained in an adversarial fashion, by simulating episodes of K-shot learning.
The parameters of the embedder and the generator are then optimized to minimize the objective comprising the content term, the adversarial term, and the embedding match term.
Here, the content loss uses a similarity measure to quantify the distance between the original image (ground truth) and the reconstructed image, whereas the adversarial term corresponds to the realism score, computed by the discriminator and is to be maximized.
Thus, two kinds of video embeddings are present in this system: one, which are computed by the embedder, and the other corresponding to the columns of discriminator matrix.
Few shot learning by fine-tuning
Once the meta-learning has converged, the systems then learns to synthesize talking head sequences for a new person, unseen during meta-learning stage.
As before, the synthesis is conditioned on the landmark images. The system is learned in a few-shot way, assuming that T training images(e.g. T frames of the same video) are given and the corresponding landmark images are also given.
Now, the meta-learned embedder can be used to estimate the embedding for the new talking head sequence, by reusing the parameters estimated in the meta-learning stage.
To generate new frames corresponding to new landmark images, a generator is applied, using the estimated embedding and the meta-learned parameters. This results in generated images being plausible and realistic, with a considerable identity gap, though.
This identity gap is then bridged via the fine-tuning stage.
The fine-tuning process can be seen as a simplified version of meta-learning with a single video sequence and smaller no. of frames.
In most situations, the fine-tuned generator provides a much better fit of the training sequence. The initialization of all parameters via the meta-learning stage is also crucial.
Let's make this theory full-proof with the amazing results achieved:
- Talking head models fine tuned on few images

- Results with selfies

- Results with portrait paintings

Potential Uses
Though this field is relatively new, and it would be exciting to see its upcoming use cases, some of the possible applications are:
- improvising speech expressions in human computer interactions
- facilitating communication for differently abled
- automated dialogue systems
- gaming industry
- video conferencing
and many more.
References and Further Reading
- Original paper: https://arxiv.org/pdf/1905.08233.pdf
Don't forget to share!