
Reading time: 30 minutes | Coding time: 10 minutes
In this article, we will understand what is object detection, why we need to do object detection and the basic idea behind various techniques used to solved this problem. We start with the basic techniques like Viola Jones face detector to some of the advanced techniques like Single Shot Detector. Some the the techniques are:
- Viola Jones face detector
- Object Detection using Histogram of Oriented Gradients (HOG) Features
- Scale-invariant feature transform (SIFT)
- AlexNet
- Region-based Convolutional Network (R-CNN)
- You Only Look Once (YOLO)
- Single Shot Detector (SSD)
What is Object Detection?
The formal definition for object detection is as follows: A Computer Vision technique to locate the presence of objects on images or videos. Object Detection comprises of two things i.e. Image Classification and Object Localization.
Image Classification answers the question " What is in the picture/frame?". It takes an image and predicts the object in an image. For example, in the pictures below we can build a classifier that can detect a person in the picture and a bicycle.

But if both of them are in the same image then it becomes a problem. We could train a multilabel classifier but we still don’t know the positions of bicycle or person. The task of locating the object in the image is called Object localisation.
Why we need object detection?
Object detection is a widely used technique in production systems. There are variants of object detection problem such as:
- Image classification
- Image segmentation
Object detection has its own place and it is used as follows:
-
An image has multiple objects but every application has a focus on a particular thing such as a face detection application is focused on finding a face, a traffic control system is focused on vechiles, an driving technology is focused on differentiating between vehicles and living beings. In the same line, Object detection technique helps to identify the image segment that the application needs to focus on.
-
It can be used to reduce the dimension of the image to only capture the object of interest and hence, improving the execution time greatly
Object Detection Techniques
Generally, Object detection is achieved by using either machine-learning based approaches or Deep learning based approaches.
Machine Learning Based techniques
In this approach, we define the features and then train the classifier (such as SVM) on the feature-set. Following are the machine learning based object detection techniques:
1. Viola Jones face detector (2001)
- It was the first efficient face detection algorithm to provide competitive results.
- They hardcoded the features of the face (Haar Cascades) and then trained an SVM classifier on the featureset. Then they used that classifier to detect faces.
- The downside of this algorithm was that is was unable to detect faces in other orientation or arrangement (such as wearing a mask, face tilted, etc.)
2. Object Detection using Histogram of Oriented Gradients (HOG) Features
- Navneet Dalal and Bill Triggs introduced Histogram of Oriented Gradients(HOG) features in 2005.
- The principle behind the histogram of oriented gradients descriptor is that local object appearance and shape within an image can be described by the distribution of intensity gradients or edge directions.
- The image is divided into small connected regions called cells, and for the pixels within each cell, a histogram of gradient directions is compiled. A descriptor is assigned to each detector window. This descriptor consists of all the cell histograms for each block in the detector window. The detector window descriptor is used as information for object recognition. Training and testing of classifiers such as SVM happens using this descriptor.
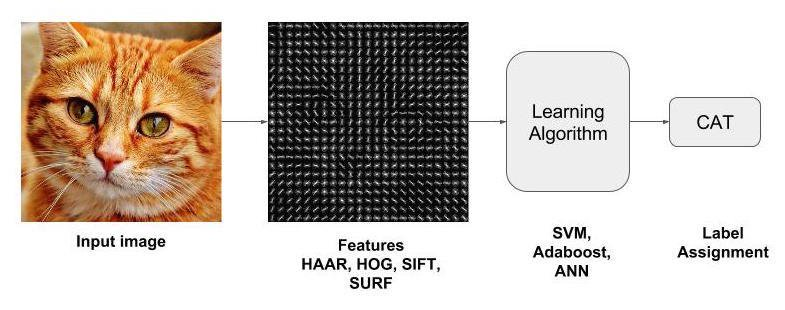
- Despite being good in many applications, it still used hand coded features which failed in a more generalized setting with much noise and distractions in the background.
3. Scale-invariant feature transform (SIFT)
SIFT was created by David Lowe from the University British Columbia in 1999.The SIFT approach, for image feature generation, takes an image and transforms it into a large collection of local feature vectors. Each of these feature vectors is invariant to any scaling, rotation or translation of the image. There are four steps involved in the SIFT algorithm:
-
Scale-space peak selection: Potential location for finding features.
-
Keypoint Localization: Accurately locating the feature keypoints.
-
Orientation Assignment: Assigning orientation to keypoints.
-
Keypoint descriptor: Describing the keypoints as a high dimensional vector.
These resulting vectors are known as SIFT keys and are used in a nearest-neighbour approach to identify possible objects in an image.

Deep Learning Based techniques
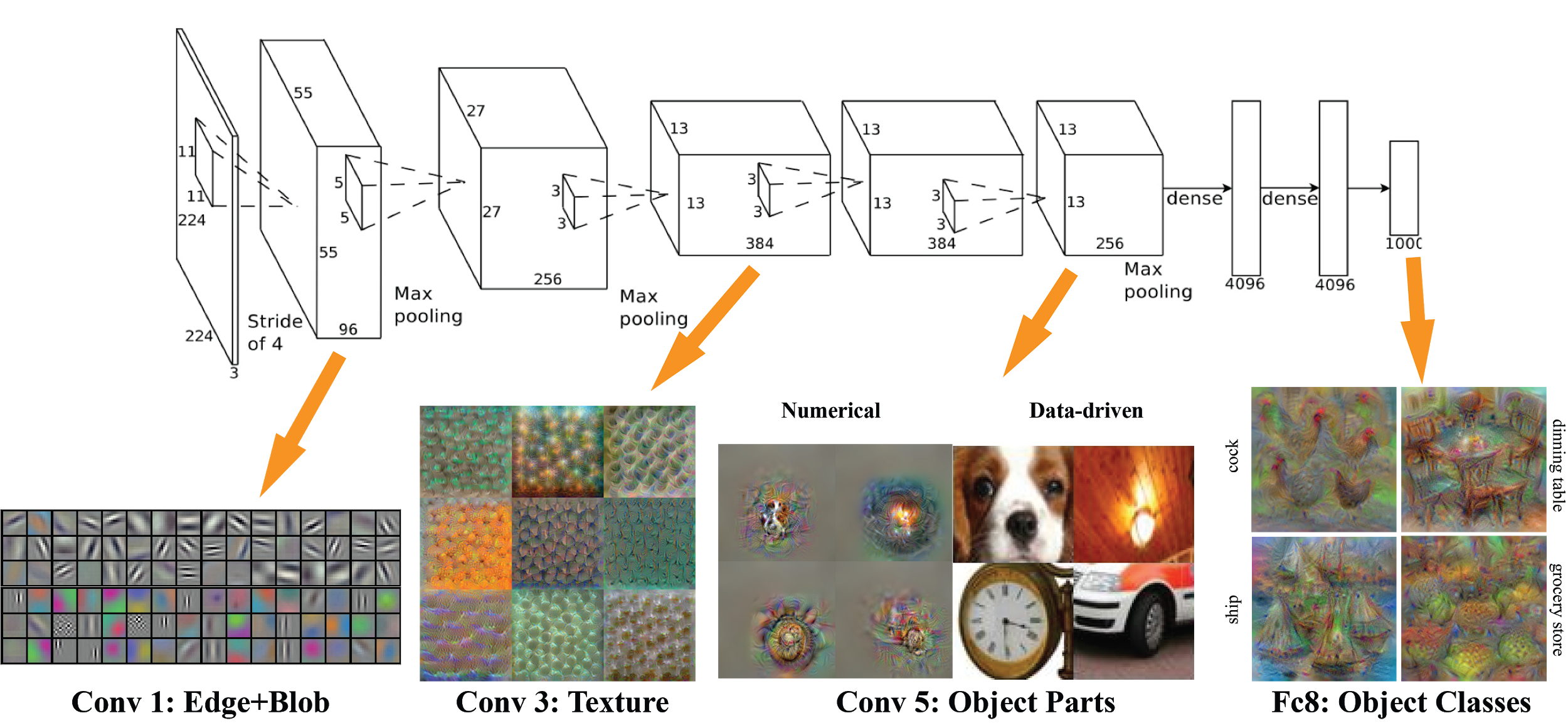
Deep Learning techniques are able to do end-to-end object detection without specifically defining features, and are typically based on convolutional neural networks (CNN). A Convolutional Neural Network (CNN, or ConvNet) is a special kind of multi-layer neural networks, designed to recognize visual patterns directly from pixel images.
1. AlexNet
In 2012, AlexNet significantly outperformed all prior competitors at ImageNet Large Scale Visual Recognition Challenge(ILSVRC) and won the challenge. Convolutional Neural Networks became the gold standard for image classification after Kriszhevsky's CNN's performance during ImageNet.
2. Region-based Convolutional Network (R-CNN)
CNNs were too slow and computationally very expensive. R-CNN solves this problem by using an object proposal algorithm called Selective Search which reduces the number of bounding boxes that are fed to the classifier to close to 2000 region proposals.
In R-CNN, the selective search method developed by J.R.R. Uijlings and al. (2012) is an alternative to exhaustive search in an image to capture object location. It looks at the image through windows of different sizes, and for each size tries to group together adjacent pixels by texture, color, or intensity to identify objects.
The main idea is composed of two steps. First, using selective search, it identifies a manageable number of bounding-box object region candidates (region of interest). And then it extracts CNN features from each region independently for classification.
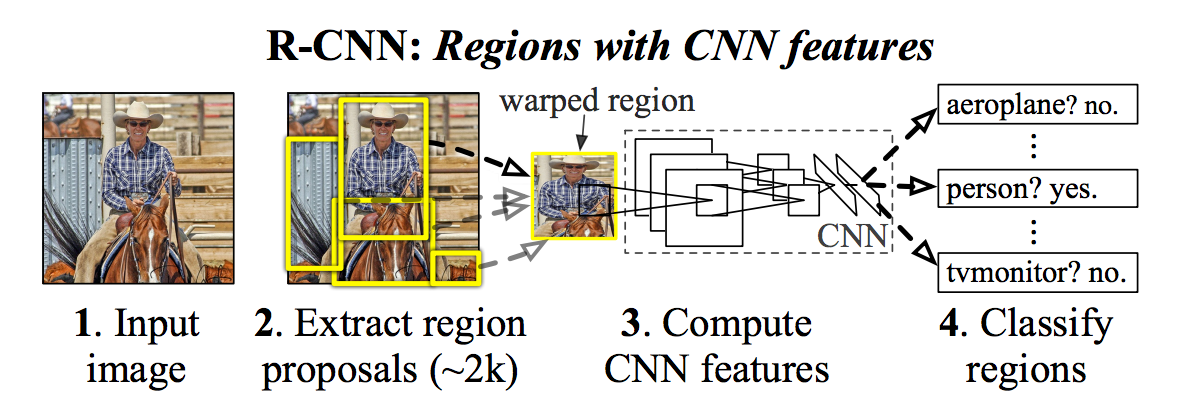
R-CNN was improved over the time for better performance. Fast Region-based Convolutional Network (Fast R-CNN) developed by R. Girshick (2015) reduced the time consumption related to the high number of models necessary to analyse all region proposals in R-CNN.
3. You Only Look Once (YOLO)
The YOLO model (J. Redmon et al., 2016) directly predicts bounding boxes and class probabilities with a single network in a single evaluation. They reframe the object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities.
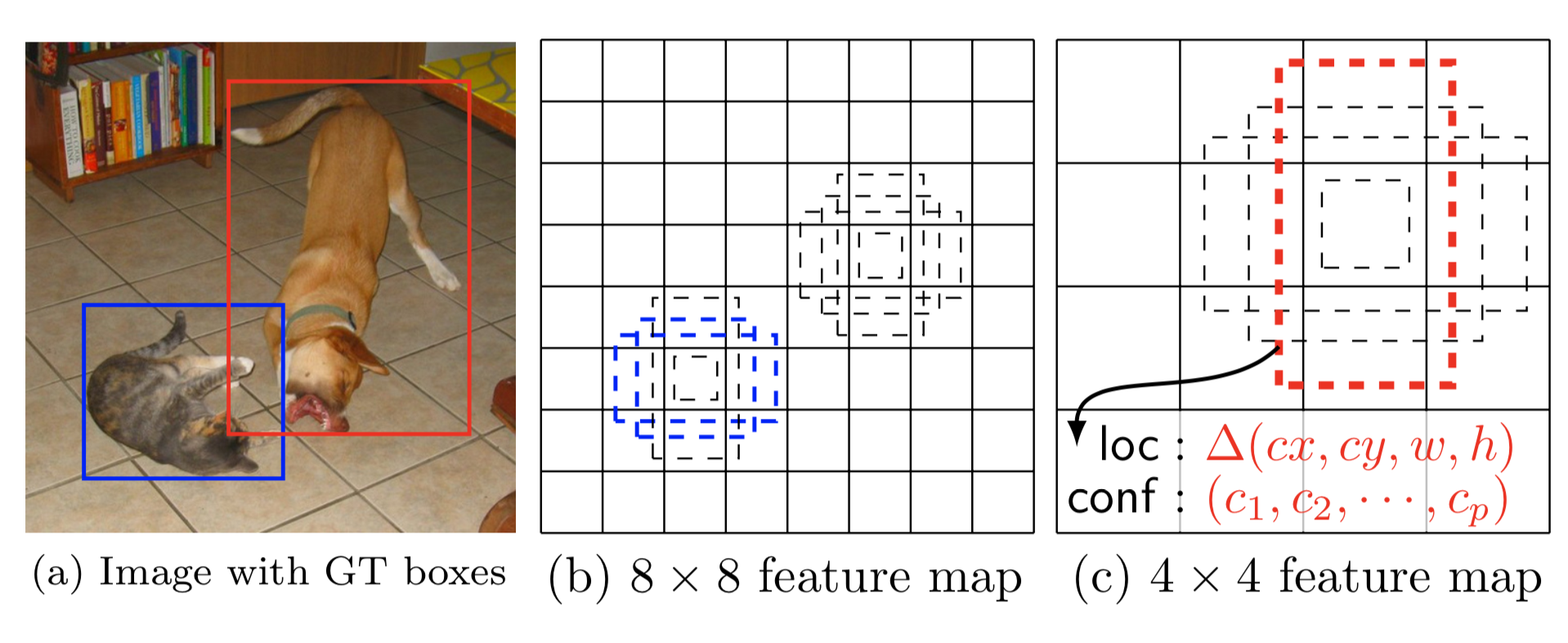
YOLO divides each image into a grid of S x S and each grid predicts N bounding boxes and confidence. The confidence score tells us how certain it is that the predicted bounding box actually encloses some object.

Over time, it has become faster and better, with its versions named as: YOLO V1, YOLO V2 and YOLO V3. YOLO V2 is better than V1 in terms of accuracy and speed. YOLO V3 is more accurate than V2.
4. Single Shot Detector(SSD)
SSD model was published (by Wei Liu et al.) in 2015, shortly after the YOLO model, and was also later refined in a subsequent paper.
Unlike YOLO, SSD does not split the image into grids of arbitrary size but predicts offset of predefined anchor boxes for every location of the feature map. Each box has a fixed size and position relative to its corresponding cell. All the anchor boxes tile the whole feature map in a convolutional manner.
Feature maps at different levels have different receptive field sizes. The anchor boxes on different levels are rescaled so that one feature map is only responsible for objects at one particular scale.
Question
What makes YOLO and SSD algorithms different from all the other deep learning algorithms?
Algorithms for object detection can be based on classification or on regression.
Algorithms based on Classification first select interesting regions in the image and then classify those regions using CNNs. R-CNNs, Faster-RCNN and its imrpoved alogrithms come under these type of algorithm.
Algorithms based on Regression predicts classes and bounding boxes for the whole image in one run of the algorithm.They reframe the object detection as a single regression problem. Yolo and SSD are most popular examples of these type of algorithms