
In this article, we will explore overfitting and how to avoid it. Overfitting is an important concept for you to learn so that you can develop reliable models for your needs.
Table of contents:
- What is overfitting?
- Overfitting vs. underfitting?
- How to detect overfitted models?
- How to avoid overfitting?
What is overfitting?
Overfitting refers to a phenomenon in data science that occurs when a our models aren't able to fit exactly to their training data. If this happens, the algorithm will fail to perform well against unknown data. Generalization of the model is important because at the end, this is what allows us all to use machine learning algorithms every single day to make predictions, classify data and solve important business and real life problems.
Let's start from the beginning. We use a sample dataset to train our machine learning algorithms. If we train our model for a long time, or our Machine Learning model is too complex, sometimes the model can become too dependent on the sample dataset and it can begin to learn irrelevant information which what we call it noise. If the model learns this noise and and our linear or non linear function becomes too close to the training set samples, it can become "overfitted" and cannot perform well to new data which is against the rule of generalization. A model that is unable to generalize to new data will fail to perform the tasks of prediction and classification.
How can we identify overfitting? Well, it can be identified by low error rates and high variance. This type of behavior is usually stopped by setting aside a part of the training dataset as the "test" set to check for overfitting. We can conclude there's an overfitting behaviour, if the training data shows a low error ratio and the test data shows a high error rate.
Overfitting vs. underfitting?
If your model's complexity or overtraining leads in overfitting, then you can either stop the training sooner, this is called "early stopping", or reduce the complexity of the model by eliminating less important inputs. You may find that your model is not fitting properly if you pause too quickly or exclude too important features, and this will lead you to have Underfitting phonomena. If the model isn't trained properly or the input variables are not sufficient to create a meaningful relationship, then the model may be underfitted.
Both scenarios fail to identify the trend from the training dataset. Underfitting can also be a poor predictor of unseen data but, unlike overfitting they experience more bias and less variance in their predictions. This is also what we call the bias-variance trade-off. As we train our model more and more, the bias will decrease but the variance will likely to increase. Fitting a good model will require you to find a sweet spot between underfitting/overfitting so that the model can establish a good trend, and then be applicable to all datasets. At the end this what we want to achieve, a good generalization of our model.
Let's get more deeper.
How to detect overfitted models?
Test for model fitness is essential to determine the accuracy of machine-learning models. Cross-validation of K-folds is one on the ways to test the accuracy of the model.
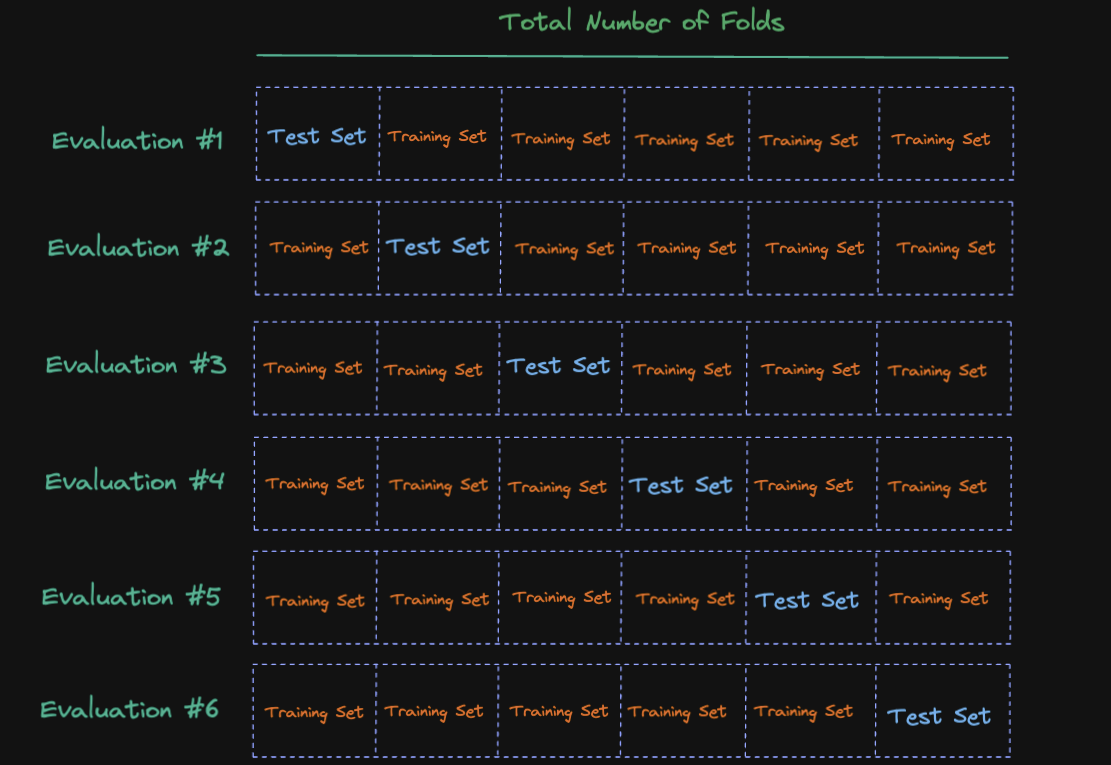
Cross-validation of k-folds data involves splitting the data into k equally sized subsets. These subsets are referred as folds. The test set (also called the validation set, or holdout set) will be one of the k folds. Folds except the holdout fold will train the model. We perform training until each of the k-folds will act as a test set so this means we train the model k times. At each training we evaluate the model with our holdout fold. Once each evaluation is completed, a score will be saved and later be averaged to determine the overall performance of the model.
Let's assume, for instance, that we divide the dataset into six groups. You can visualize this process as follows:
How to avoid overfitting?
We talked about model complexity and you might be thinking, okay let's use less complex linear models. While a linear model is helpful in avoiding overfitting since the complexity is low, many real-world problems can be viewed as nonlinear. Understanding how to spot overfitting is essential, but it's also important to learn how to avoid it. I listed below some of the techniques and high level overview of each of this methods:
-
The early stopping method: This technique aims to stop training before the model learns the noise.As I mentioned earlier, this method could cause the training process to be stopped too quickly, which can lead to underfitting. Always remember that the ultimate goal is to find the sweet spot in bias/variance trade-off.
-
More data in Training Phase: Having a large training set which contains more data, you can improve the model's accuracy by giving more opportunities to identify the relationship between input and output variables. However, always keep in mind to have relevent and clean data in the dataset.
-
Regularization: It is a common problem to overfit a model that is too complex. In this case, we can reduce the number of features. But how do you actually decide what to keep and what to get rif of? Regularization methods are particularly useful if you don't know which features you want to eliminate from your model. Regularization is a method that applies a penalty to input parameters with higher coefficients. This limits the model's variance. You can try to use L1 regularization, Lasso Regularization and drop out techniques.
-
Data augmentation: It's better relevent and clean data as I said, but there are times when noisy data is needed to make a model more reliable. But don't over do it, otherwise model will learn the noise.
-
Feature Selection: While you can have many features or parameters that you use to predict an outcome, it is possible for some of these features to be redundant. Feature selection involves identifying the most significant features in the training data and eliminating any redundant or unnecessary ones. You might also try to use PCA to reduce dimensionality as well.
-
Ensemble Methods: Ensemble methods are techniques that increase the accuracy of model results by combining multiple models rather than using a single model. The combined models greatly improve the accuracy. Ensemble methods are now very popular in machine learning. Most commonly used ensemble methods are bagging, boosting and stacking.