
Over the past decade, deep learning field made tremendous progress in developing intelligent systems that can learn from massive amounts of carefully annotated data to solve industry problems. This paradigm of learning is called supervised learning. Successful supervised learning applications need large annotated datasets which is sometimes impossible/very hard to acquire since the annotation process is tedious, time consuming, expensive and error-prone. Furthermore, these applications lack the skill to generalize well on new distributions that are different from the training distribution.
For these reasons, it is impossible to further advance the deep learning field by only relying on supervised learning paradigms. We need intelligent systems that can generalize well without the need for labeled datasets, so how are researches evolving toward this goal?
Table of Content
- Supervised vs Unsupervised Learning
- Self-Supervised Learning
- How does Self-Supervised Learning work?
- Benefits of Self-Supervised Learning
- Applications of Self-Supervised Learning
- Supervised learning vs Unsupervised leaning vs Self-Supervised learning
- Conclusion
1. Learning Approaches
To answer the question asked earlier in the introduction, we should first review the learning approaches that are available to see what are their limitations and how to overcome them.
Supervised learning
Supervised learning is a machine learning approach that aims to train a model using labeled data, to perform a desired task. The aim of the labels is to give a feedback about the predictions in the training phase.
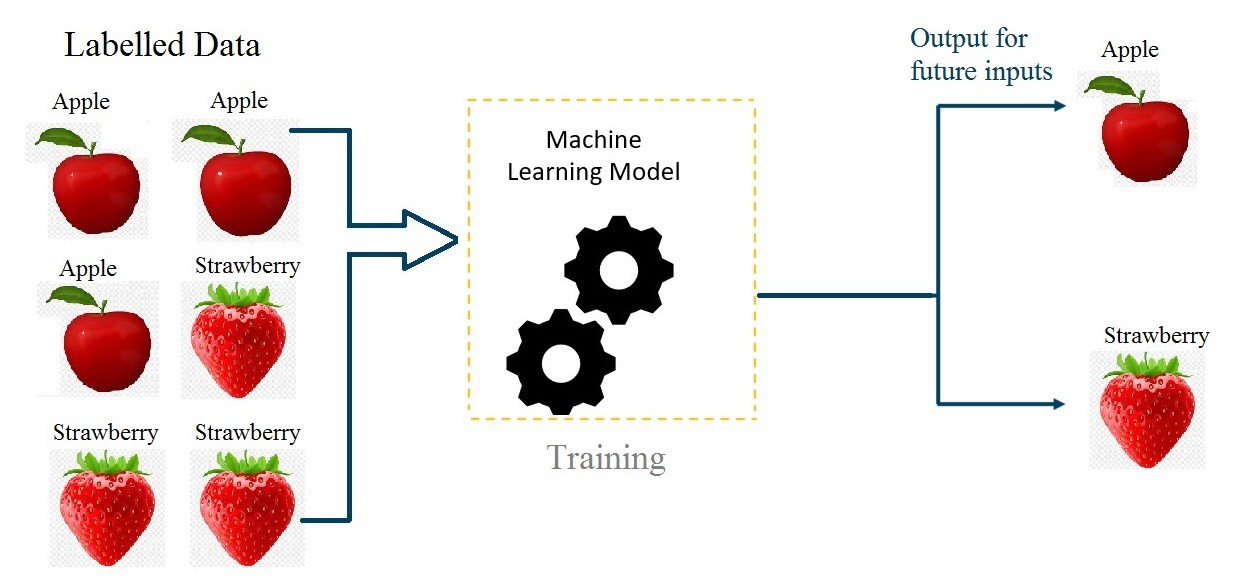
In real life, this method of learning can be described as the following situation: students learning about a topic only through exercise examples and their solutions.
The problem with this method of learning is that it performs well only when the training dataset (in the given situation: the exercises given to students and their solutions) have all the possible cases of the problem, elsewhere if the model is given a situation that never was in the training dataset, it will be incapable of generalizing. In addition to that, in some cases it is just impossible to annotate all possible cases of a problem, which is why this method of learning is ineffective in such situations. Instead, we need a method that can learn from unstructured (unlabeled) data.
Unsupervised learning
Unsupervised learning is a machine learning approach that trains model to find the hidden patterns in the unlabeled dataset and unlike supervised learning, this technique doesn't have a feedback loop. An example of that is giving a child a set of objects with different shapes and colors and asking him to order them the way he thinks it's more suitable.
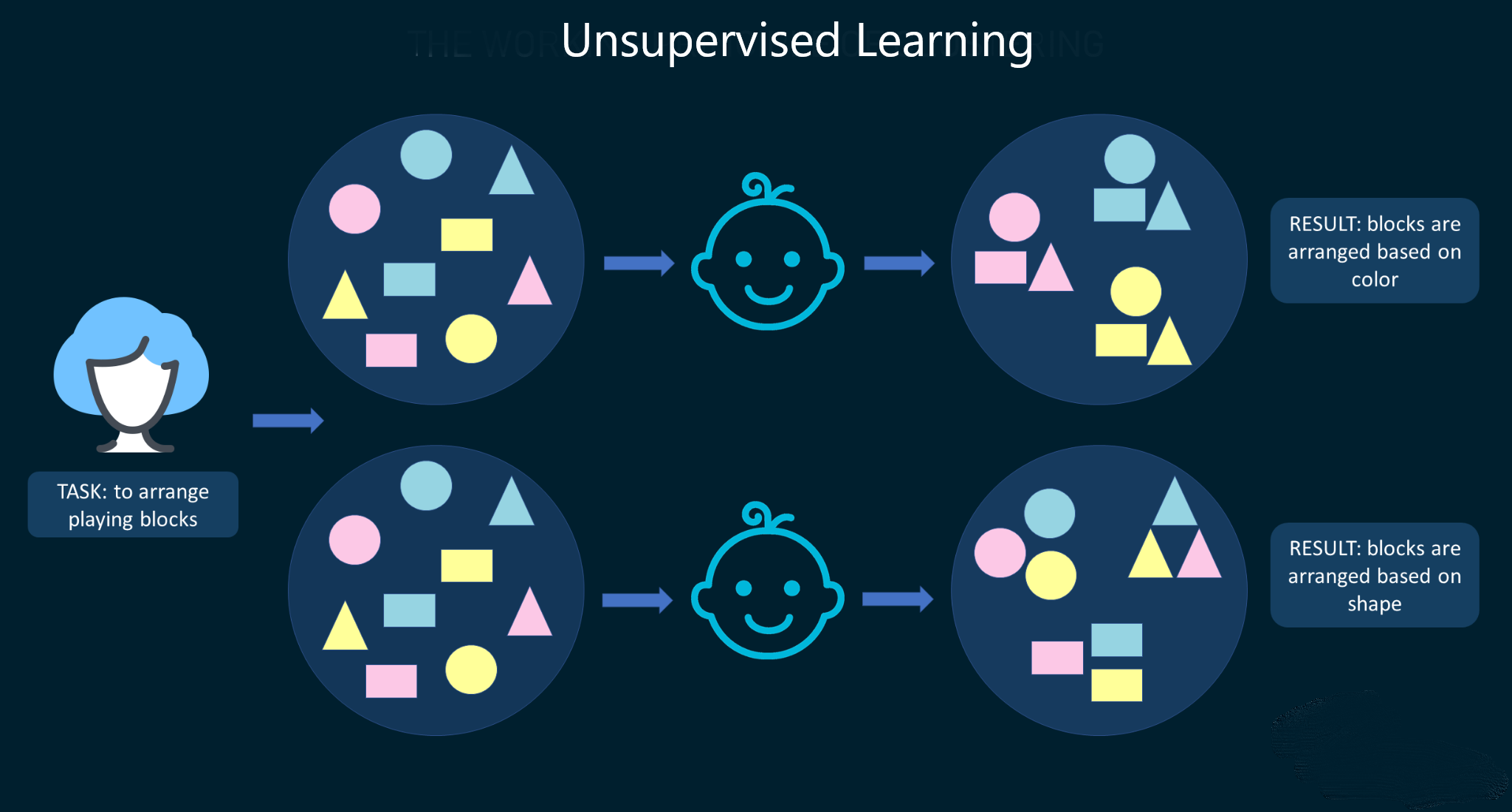
The child then might end up categorizing them by shape or by color. However, this learning method is only good for clustering and dimensionality reduction and doesn't perform well on more complex tasks like classification or regression since it has no guidance or feedback about the task that should be done.
With that being said, so we need an algorithm that does need a feedback loop like supervised learning but doesn't require labeled data.
2. Self-Supervised Learning (SSL)
Before diving to what SSL is let's first understand how humans learn. As babies, humans first start observing the world around them to understand how it works. Then they form predictive models about objects in their environments. Later in life, they observe their environment, act on it and then observe again. They learn through trial and error. Then comes the question, how do humans construct generalized knowledge about the world? well, the answer is common sense.
Common sense makes people rely on their previous acquired knowledge about the world and learn new skills without requiring massive amounts of teaching for every single task.
From this idea of Common Sense that the concept of Self-Supervised Learning was created.
SSL is a predictive learning process that generates supervisory signals by making sense of the data provided to it in unsupervised fashion on the first iteration. In other terms the machine will be provided some parts of the data and it will be asked to generate labels or to recover whole, or parts or merely some features from the inputs. An example of that is used in NLP where the machine is given a part of a sentence and it is asked to complete the rest of the sentence.

However, someone might think since we have no labels, why don't we classify this method as unsupervised learning ?
SSL is different than unsupervised learning, in a way that unsupervised learning is more focused on detecting patterns in data without using labels at any stage of its training, this involves tasks like clustering, dimensionality reduction and anomaly detection. While SSL is more about performing conclusive tasks by generating labels from the data itself like: classification, segmentation, and regression. Thus SSL include supervised paradigms and unsupervised paradigms.
3. How does Self-Supervised Learning work?
In order to train models using SSL, it is important to wisely choose an adequate objective function. In the following sections we will cover the evolution of the loss functions that have been used with SSL along with the needed architectural components.
Energy Based Models (EBM)
An EBM is a trainable system that computes the compatibility between two given inputs x and y using a mathematical function called the Energy Function. This Energy Function plays the roll of the loss function. What does that mean? it means the goal is to minimize this function. So when the energy is low the inputs are said to be compatible and when the energy is high the inputs are said to be incompatible.
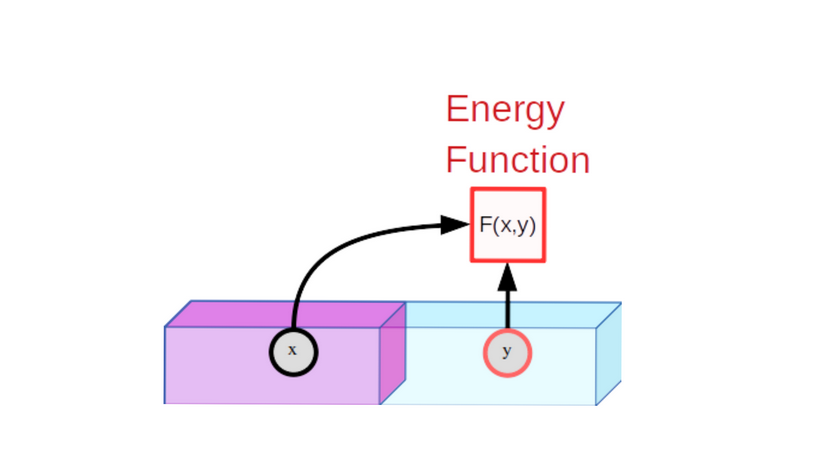
Training an EBM consists of two parts:
- Showing the model x and y that are compatible and training it to produce a low energy.
- Ensure that for x and y that are incompatible, the model produces a high energy. (This is the most difficult part in the training process.)
An example of this method in computer vision, is feeding the model two images that are distorted version from the same image. Say for example one is an image of a cat and the other one is an augmented version of this image: it may be a zoomed version or a version where a Gaussian noise was applied to it for example. The model will then be trained to produce a low energy on these images.
A suitable architecture for such application is the Joint Embedding Architecture that is described in the next section.
Joint embedding architecture
It is also called Siamese Network. It is an EBM model, that is composed of two parallel identical networks that are joined with a third module in the head of the network.
The two inputs x and y are fed to the two networks. Each network calculates an embedding (representation) of its input and the third modules computes the Energy Function as a distance between the embeddings
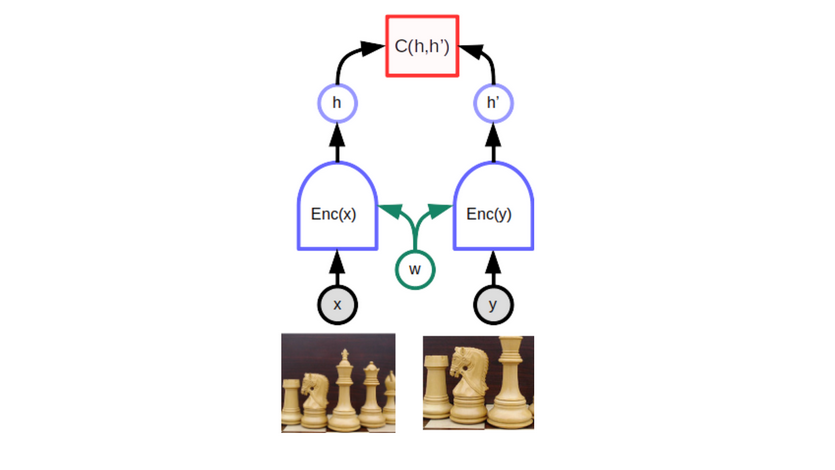
This network can easily ensure outputting nearly identical embeddings for same objects. However, sometimes it is difficult to output different embeddings for different objects, this phenomenon is called collapse. When it occurs the energy of two different objects is not that much high than the energy of two identical objects.
But is there a way to overcome the collapse phenomenon? The answer is that there are methods to avoid the collapse phenomenon which are: Contrastive and non-contrastive methods that we'll cover in the next sections.
Contrastive methods
Since incompatible inputs might yield similar embeddings, then maybe we should have more control and try to construct incompatible (contrastive) pairs x and y from the data, then adjust the weights of the model to output large energy.
This idea was first used in NLP, where the network of embeddings was replaced by a predictive model .The model was first given a text y, then it was corrupted by removing some words to construct an observation x.
The corrupted input x will then be fed to a large neural network that will be trained to reconstruct y. Then also y will be used to reconstruct itself that we will call y*. Finally x will be contrasted to y* and should have a high reconstruction error and y will be contrasted to y* and should have a low reconstruction error.
The neural network that is used to do the reconstruction is called the denoising auto-encoder which have the architecture shown in the figure bellow.
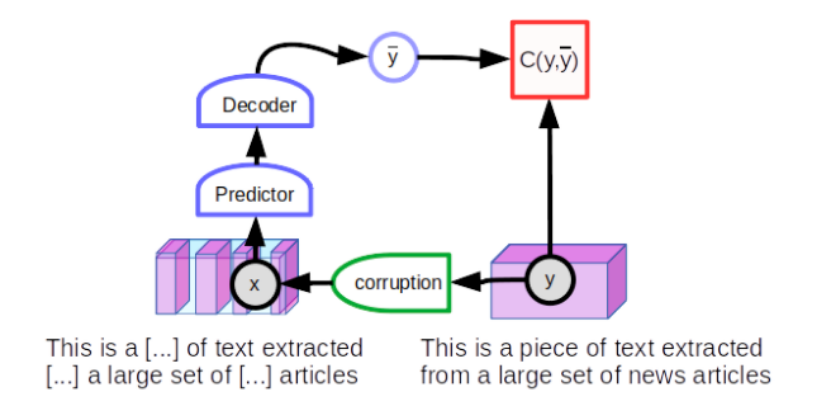
The predictions of the model is a series of scores for every word in the vocabulary for each missing word location.
Someone might ask how is contrastive learning applied in computer vision? It is difficult to apply this technique in computer vision since it's quit hard to generate a set of all possible contrastive examples of an image (There are many ways an image might be different than another image). However, there are some promising research in this direction like: Contrastive Predictive Coding (CPC), Instance Discrimination Methods and Contrasting Cluster Assignments.
Finally, as you may noticed, contrastive learning might be sometimes inefficient in training since it requires enumerating a set for all contrastive examples. So, is there a better way to make sure that the energy of incompatible inputs is higher than the energy of compatible inputs, without having to enumerate explicitly all possible contrastive examples? The answer to this question is given in the next section.
Non-Contrastive methods
Non-Contrastive Self-Supervised Learning (NC-SSL) is mostly used in computer vision. The method use only positive examples without using any contrastive (negative) examples. Despite this sounds counterintuitive, since we try to minimize only positive pairs we may end up in a collapse situation. However, NC-SSL showed to be able to learn non-trivial representations with only positive pairs. With that being said, two questions may arise:
- Why the learned representations with NC-SSL do not create a collapse situation?
- How does the learned representations reduce the sample complexity in downstream tasks?
The answer to the first question is that NC-SSL enforce implicit contrastive constraints to avoid collapse situations by using BatchNormalization, de-correlation, whitening, centering, and online clustering. In addition to that algorithms like BYOL and SimSiam use an extra predictor and stop gradient operation.
The answer to the second question is in [2]. Since non-contrastive learning doesn't use negative (contrastive) examples, the joint embedding architecture becomes linear. The authors of [2] show that a desirable projection matrix can be learned in a linear network settings and helps reducing the sample complexity on downstream tasks. Furthermore, their analysis shows that weight decay plays an important role in NC-SSL since it acts as an implicit threshold that discards features with high variance under data augmentation and keeps only features with low variance.
4. Applications of Self-Supervised Learning
SSL has been widely used in NLP and computer vision tasks, bellow are some examples.
Healthcare
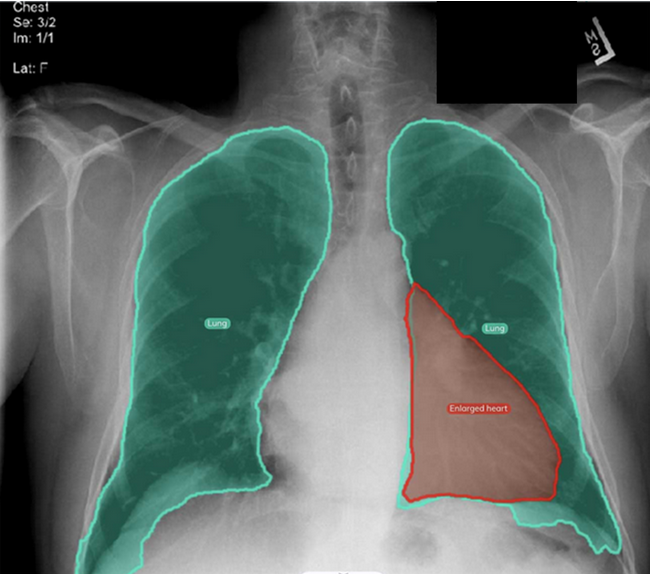
SSL was used in many application like histopathology image classification[3] for cancer detection, organs segmentation in XRay and MRI images.
Colorization
SSL can also be used to automatically colorize grayscale images or videos.
the task boils down to mapping the given grayscale image/video to a distribution over quantized color value outputs.

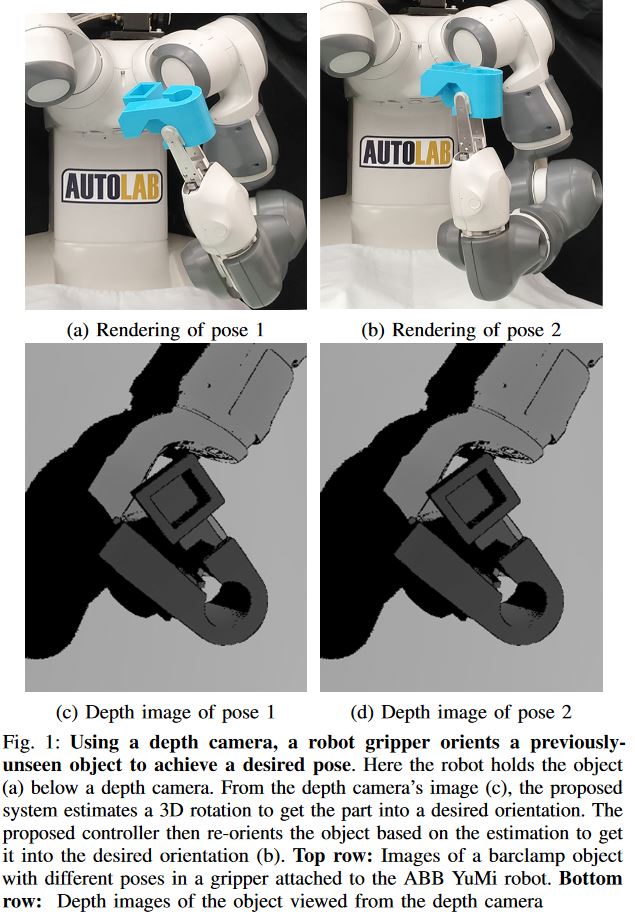
3D Rotation
SSL has been also used to orient 3D objects using robots like in this paper [4]
Detection of hate Speech
Meta (Facebook) uses SSL in proactive detection of hate speech in many languages [1].
5. Pros and cons of Self-Supervised Learning
SSL was popularized by its application in NLP when it was used with transformers like BERT to do tasks like text prediction. However, it is still an area under research and has its own benefits and downsides.
Pros
- Scalability: SSL doesn't require labeled data. It works with unstructured data and can train on massive amounts of it.
- Time saving and Cost Reduction: Tagging data is time consuming and requires a lot of experts especially with big dataset. SSL automates the process of labeling data and thus saves time and eliminates the annotation process costs.
- Generalized AI: SSL is a step forward toward generalized AI since it approximates the human common sense.
Cons
- High computing power needs: The training process for SSL is much slower than the training process for supervised learning, since the model needs first to generate the labels then try to minimize the loss function.
- Reduced Accuracy: SSL generates its own labels without any aided system. This means that if the model predicts a wrong class with a high confidence the model will still believe that it's correct and won't fine tune the parameters against this prediction.
6. Supervised learning vs Unsupervised leaning vs Self-Supervised learning
To help you make a comparison between the three types of learning we covered in this article, the table bellow shows the differences and similarities between supervised learning, unsupervised learning and self-supervised learning
| Supervised Learning | Unsupervised Learning | Self-Supervised Learning |
|---|---|---|
|
|
|
7. Conclusion
To wrap up what have been covered in this article at OpenGenus here are some key takeaways:
- Supervised learning has reached its limitations since it's dependant on massive amounts of labeled data which can be difficult to acquire in some domains.
- Self-Supervised Learning is capable of overcoming the limitations of supervised learning. SSL has the ability to annotate the inputs and uses them as ground truths in future iterations.
- SSL was popularized thanks to its success in NLP when used with the transformer model.
- SSL is still under research especially when it comes to its use in computer vision.
- There are two types of SSL: Contrastive and non-contrastive learning .
- SSL has two main downsides: the need for high computation power and the low accuracy.
References
[1] “Self-supervised learning: The dark matter of intelligence,” Meta AI, 04-Mar-2021. [Online]. Available: https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/.
[2] WANG, Xiang, CHEN, Xinlei, DU, Simon S., et al. Towards demystifying representation learning with non-contrastive self-supervision. arXiv preprint arXiv:2110.04947, 2021.
[3] CIGA, Ozan, XU, Tony, et MARTEL, Anne Louise. Self supervised contrastive learning for digital histopathology. Machine Learning with Applications, 2022, vol. 7, p. 100198.
[4] DEVGON, Shivin, ICHNOWSKI, Jeffrey, BALAKRISHNA, Ashwin, et al. Orienting novel 3D objects using self-supervised learning of rotation transforms. In : 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE). IEEE, 2020. p. 1453-1460.