
RoBERTa (Robustly Optimized BERT pre-training Approach) is a NLP model and is the modified version (by Facebook) of the popular NLP model, BERT. It is more like an approach better train and optimize BERT (Bidirectional Encoder Representations from Transformers).
Introduction of BERT led to the state-of-the-art results in the range of NLP tasks. BERT uses a robust method of training the model which first pre-trains it on a very large dataset as opposed to training it directly on specific labelled dataset for that task. If you want to know about BERT in-depth, do check out this article.
RoBERTa was introduced by Facebook, which builds up on BERT. It modifies certain aspects of BERT which are:
- Training size
- Dynamic Masking Pattern
- Replacing Next Sentence Prediction Objective
- Training sequences
Training Size
RoBERTa uses way bigger dataset than BERT. It uses CC-NEWS (76G), OpenWebText (38G), Stories (31G) and BookCorpus (16G) data which amounts to a total of 160 GBs of data for pre-training. This enormous dataset was possible to be trained on the model due to 1024 V100 Tesla GPU’s which ran for a day. While BERT only uses BookCorpus dataset for pre-training (16GB).
Dynamic Masking Pattern
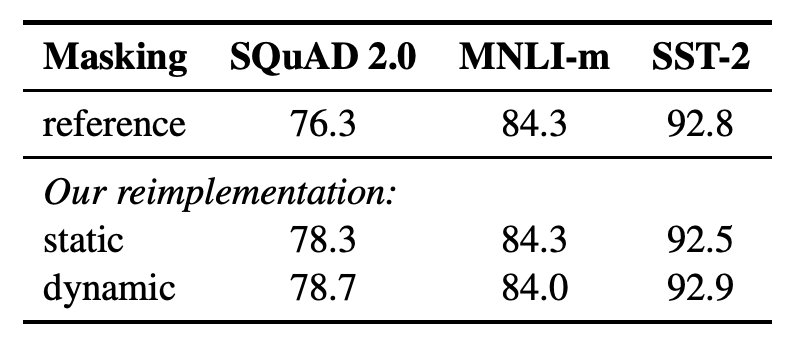
BERT during pre-training masks the token for Masked Language Models (MLM) objective. This masking is done in a random fashion which is done at the pre-precessing step once which results in single static mask. RoBERTa avoids same training mask for each training instance by duplicating training data 10 times which results in masking each sequence 10 different ways. The result of dynamic is shown in the figure below which shows it performs better than static mask.
Replacing Next Sentence Prediction (NSP) Objective
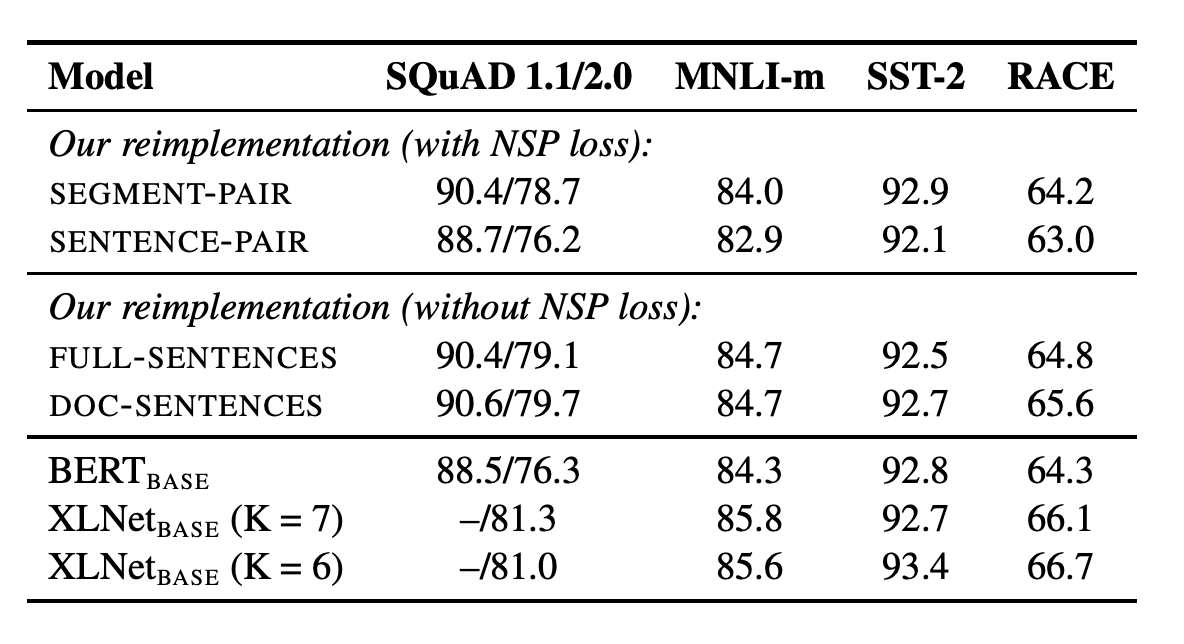
BERT was trained via a loss called NSP which given two pieces of documents, whether they belong to same or different documents. When this is removed, BERT performance degraded. RoBERTa showed that NSP loss wasen't a necessity. To better understand this, let us look at the other training alternatives.
-
SEGMENT-PAIR with NSP loss: This is what is used in BERT. Each input has a pair of segments which contains multiple sentences. Constraint was that the total length was less than 512 tokens.
-
SENTENCE-PAIR with NSP loss: Every input in this is a pair of two sentences. These can be from contiguous portion of the same or different documents. It is little different from original method used in BERT and the number of tokens is considerably less than 512.
-
FULL-SENTENCES without NSP loss: Each input is packed with full sentences sampled in a contiguous fashion from one or more documents. The total length of this is at most 512 tokens. Inputs may cross document boundaries.
-
DOC-SENTENCES without NSP: It is same as that of FULL-SENTENCES except particular input doesn't cross into other document.
Using all the above four settings, we see that without NSP training achieves better results than with NSP.
Training sequences
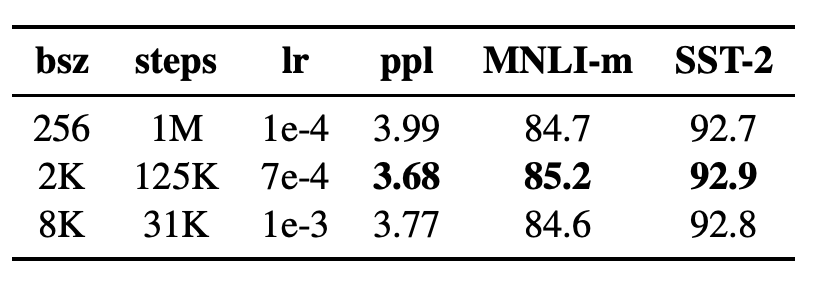
RoBERTa is trained on longer sequences than compared with BERT. BERT is trained via 1M steps with a batch size of 256 sequences. As Past work in Neural Machine Translation (NMT) has shown that training with very large mini-batches can both improve optimization speed and end-task performance. That is why RoBERTa is trained with 125k steps, 2k sequences and 31k steps, 8k sequences. The image of an experiment show that 125k steps with 2k sequences achieve a better result.
Conclusion
We can say that RoBERTa is a fine-tuned version of BERT which improves on certain areas and methodology. This is mainly done by increasing data-set size (10X) and tuning hyper-parameters. RoBERTa performs well in various benchmarks results such as GLUE, RACE and SQuAD in the original research.