
Wide and Deep Learning Model is a ML/ DL model that has two main components: Memorizing component (Linear model) and a Generalizing component (Neural Network) and a cross product of the previous two components. Wide and Deep Learning Model is used in recommendation systems.
Giving ratings and feedbacks must be considered as a do-gooding act now!
Introduction
What would you answer if the question is about your favorite mundane time? We are tend to watch movies, or listen podcasts as our past time things, isn't it? And this is very obvious that we don't always search for any movie or song, it's automatically recommended on our feed. Have you ever wondered how YouTube often suggests similar videos in our feed? What do we mean when we say the Instagram Algorithm has gone mad? How conspiratorially true is this, that Netflix traps us and make us create a whole watchlist!
These are quite common things which strikes our mind here and there. But we probably ignore these thoughts or pass it to think about it later.
These things are fun to know and if you're from Machine Learning background, I must say this topic would surely intrigue your thinking!
Wide and Deep Learning Model Explanation
The Wide and Deep Learning model is often used a recommender system for various platforms. This can be viewed as a searched ranking system where input is user and contextual features and output is a ranked list of items.
Let me isolate the above sentences into simple words.
Suppose we have a user A who listens to various Motivational Podcasts and likes to listen rock music genre. There's another new user B who enjoys listening to r&b but is new to podcasts. System has already been memorizing the pattern of rock music and motivational Podcasts as a regular input from user A, so it would suggests Motivational Podcasts to the User B. This is the basic gist of the above model.
But there might be a situation when we don't have a proper labeled input, in this situation we need to generalize the input to generate a proper output.
The process of generalising and memorising helps the model to predict the output in the far easier and accurate way.
- Generalising
- Memorising
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data. For memorising the input the Wide and Deep Learning model uses basic Linear model (in this case Logistic Regression Model) to predict the output when any particular dataset is provided to it.
Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past. For creating a Generalised model it uses complex neural network with various hidden layers to predict the output including heavy heterogeneity and mixed consequences.
Memorization tends to generate the output based on the previous user experience and Generelisation mostly tries to provide the diversity to the output model.
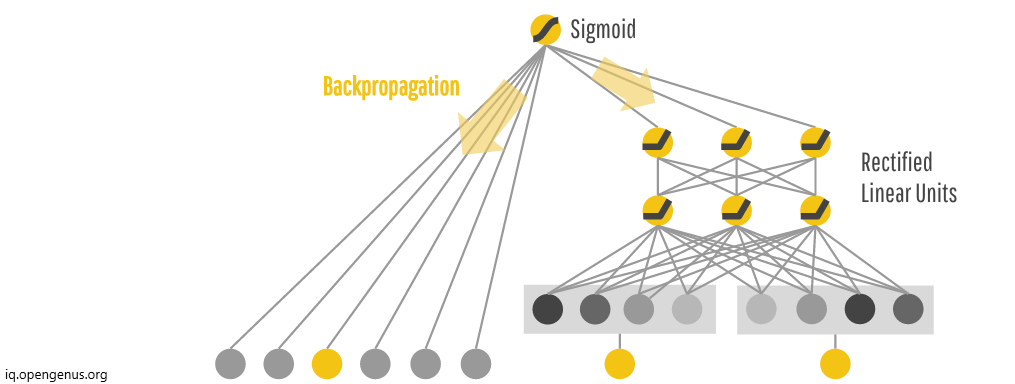
The cross-product of linear model and neural network is used to generate the output which tends to give user unique and diverse experience as much as possible.
For a particular input coming to the model such as user_watched_movie=Ironman labeled as 1, memorization can be easily achieved using the sparse matrix feature using cross-product transformations over sparse features, such as AND(user_watched_movie=Ironman, impression_movie=The Dark Knight) whose value is 1, so if user watches ironman, then the next movie suggested.
This could be strategize into more generalised format i.e (user_watch_genre=Action, impression_genre=Sci-fi). This shows how co-occurrence of the feature label pair correlates with the target label. But the feature label pair which has never occurred in the history would not be generalized even through this as everything works on pre-feeded dataset at the very ground level.
The above defined model could also over-generalise the model and might show the irrelevant recommendations, this works as a limitation of the model!
Model Training
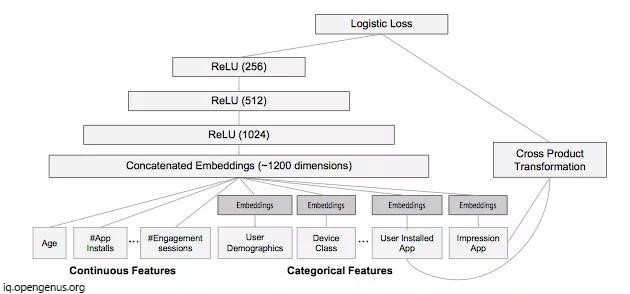
- While training the model, the input layer takes the training data and generate sparse and dense features together with a label.
- The wide component consists of the cross-product transformation of user installed apps and impression apps.
- For deep part, A 32-dimensional embedding vector is learned for each categorical feature.
- Then all the embeddings together are concatenated with the dense feature, resulting in a dense vector of approximately 1200 dimensions. The concatenated vector is then fed into 3 ReLU layers, and finally the logistic output unit.
- After that Wide & Deep models are trained on over 500 billion examples. Every time a new set of training data arrives, the model needs to be re-trained.
- However, retraining from scratch every time is computationally expensive and delays the time from data arrival to serving an updated model.
- To tackle this challenge, a warm-starting system is implemented which initializes a new model with the embeddings and the linear model weights from the previous model.
- Before loading the models into the model servers, a dry
run of the model is done to make sure that it does not cause problems in serving live traffic. Model is empirically validated and quality check is done against the previous model as a sanity check.
Applications of Wide and Deep Model
As we've already seen above some of the example which uses wide and deep model for the recommendation.
- The main application of wide and deep model comes under Recommendation System.
- Personalized Profile on various social sites and OTT platforms is achieved with the help of Wide and Deep Models.
- It has huge application in Data Science Field. The prediction of output whether a customer would like the product and showing the relevant choices is done with the help of same.
Above application is very common example of Recommender System. Some of the live examples which you might come across in your daily life is
- Customer who bought this item also bought (Shopping websites)
- Based on the accounts you follow (Instagram)
- XYZ channel viewers also watch this channel (YouTube)
- Based on the photos you like (Instgram)
- Because you watched this show (Netflix)
- Made for you (Spotify)
The above system works on basic Machine Learning models. It looks at demographic data, behavioural data, and item attributes to predict which items a user will find most relevant. These datasets come from nowhere but from our everyday action of rating or like system. Recommender systems help drive user engagement on these platforms by generating personalized recommendations based on a user’s past behaviour.
Note: Recommender System works on Implicit Feedback and Explicit Feedback given by the user which in turn is filtered on the basis of Content-Based Filtering and Collaborative Filtering.
Working of Recommender System
The best approach to evaluate a recommender system is to test it using wild strategy of A/B Testing.
In this testing, two recommendation systems are considered A and B. The group that exhibits more user engagement is assumed to have higher quality recommendations. So if users in group A watch more movies and give higher ratings than those in group B, we can conclude that Recommender System A is more effective than Recommender B.
Limitations of Wide and Deep Model
- This model works on the basis of user's experience dataset. So if any joint set is there which has never occurred in history cross-product dataset, it's more likely to never happen in future also.
- Sometimes the model might get converted into over-generalised model and which leads to show irrelevant recommendations to the user.
- The model doesn't have its own judgement and therefore might require manual work if any drastic change is needed.
Wide and Deep Model is emerging more and getting better with the span of time.