
Scope of a variable defines how a specific variable is accessible within the program or across classes. An assigned value to a variable makes sense and becomes usable only when the variable lies within the scope of the part of the program that executes or accesses that variable.
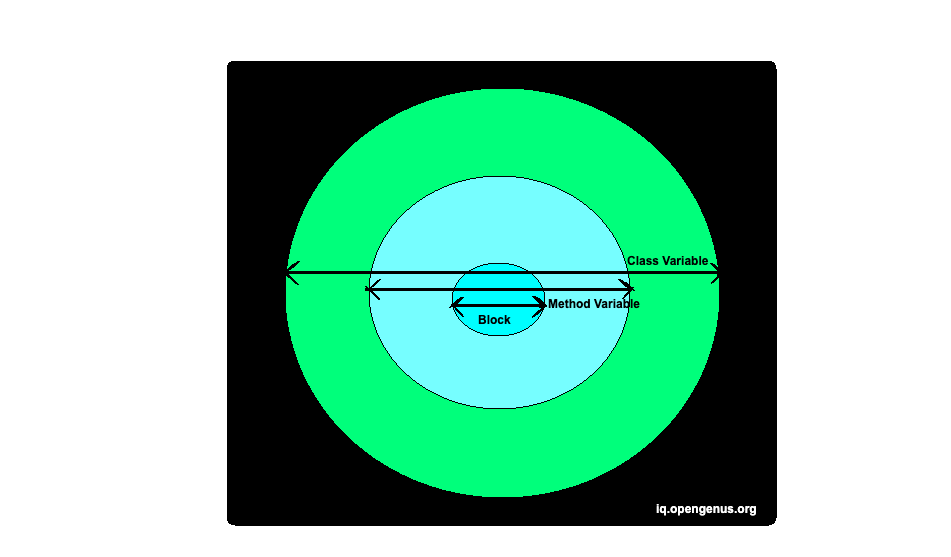
Variables are mainly of the following types:
- Static Variables
- Non-Static Varaiables
Reference: Oracle Official Documentation
The non-static variables are further classified into:
- Block Variables
- Local Variables
- Class Variables (non-static)
Static Variables:
Static variables are global variables and are variables declared inside the class but outside of all methods and loops. These variables have scope within the class such that the methods and blocks can access these.
package scope_ariables;
public class area_calculation {
static int b=5; //class variable
public static void main(String[] args) {
double a=5.7;
double RectangleArea=area_of_rectangle(a,b);
System.out.println(RectangleArea);
}
public static double area_of_rectangle(double length, double breadth) {
double area= length * b;
return area;
}
}
Here the variable declared outside the main method and within the scope of the class, is accessed by both the loops inside the class and the methods.
- Static variables can be accessed by both static and non static methods. All the instances of the class can access these static variables by just using the class name.
- Static variables are common for all the instances of the class. This is similar to a chocolate cake shared among friends. Any addition made to the variable affects the other instances using the variable.
Non-Static Variables:
Non static variables of a class, in case of a class variable
are accessed only within the class. This is subject to the presence of access modifiers which is discussed later in this article.
-
Block Variables:
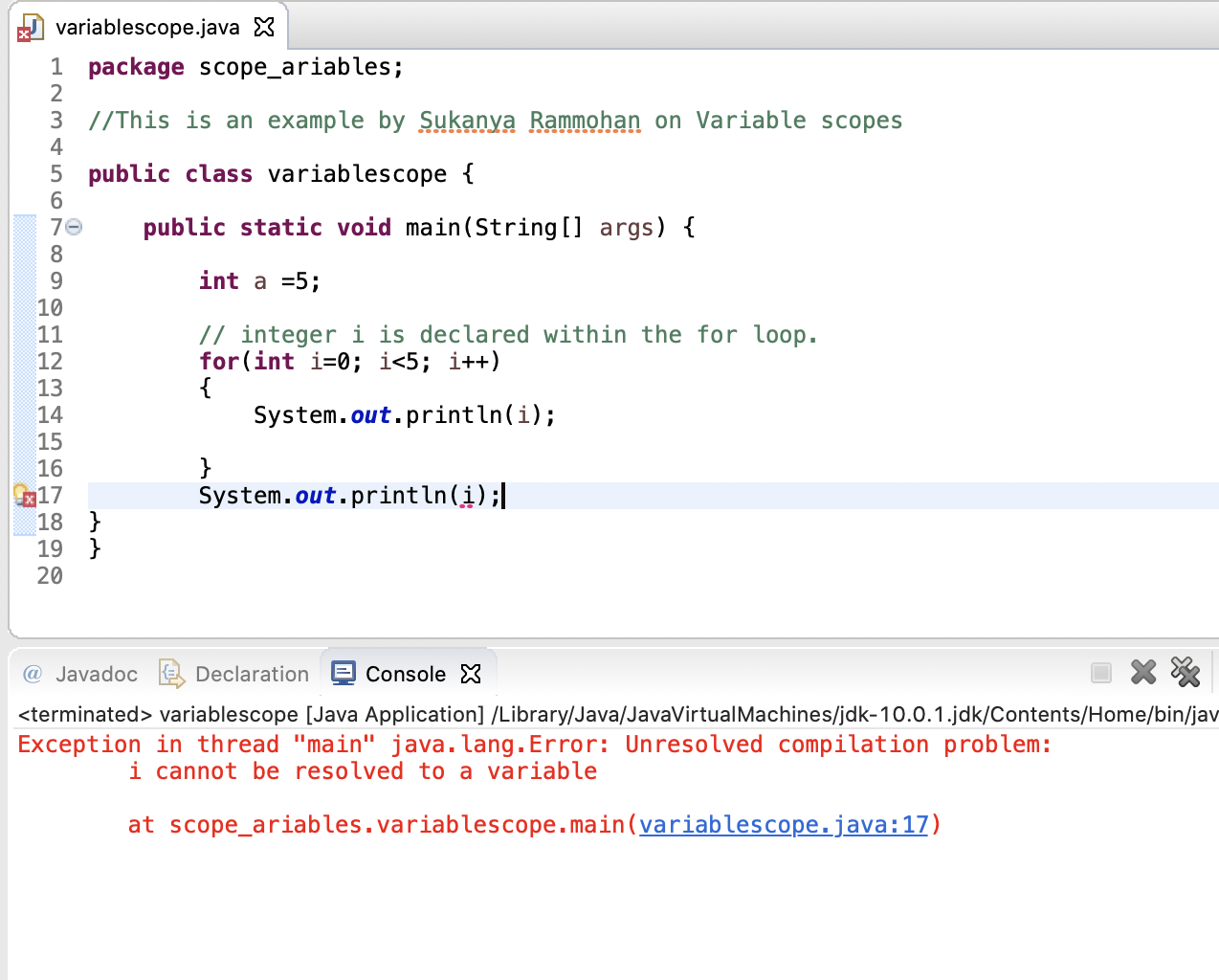
These are variables used specifically within a bracket such as within loops. A good example is the variable declared within a for loop. In the example below, the variable i is only accessible within the for loop, which means that the scope of the variable i ends outside the loop. Only the variables declared outside the for loop such as the variable int a, can be called either inside or outside the loop.
package scope_variables;
public class variablescope{
public static void main(String[] args) {
int a =5;
// integer i is declared within the for loop.
for(int i=0; i<5; i++)
{
System.out.println(i);
}
System.out.println(a);
}
}
What happens when a block variable is called outside the loop? An error is thrown
-
Local Variables:
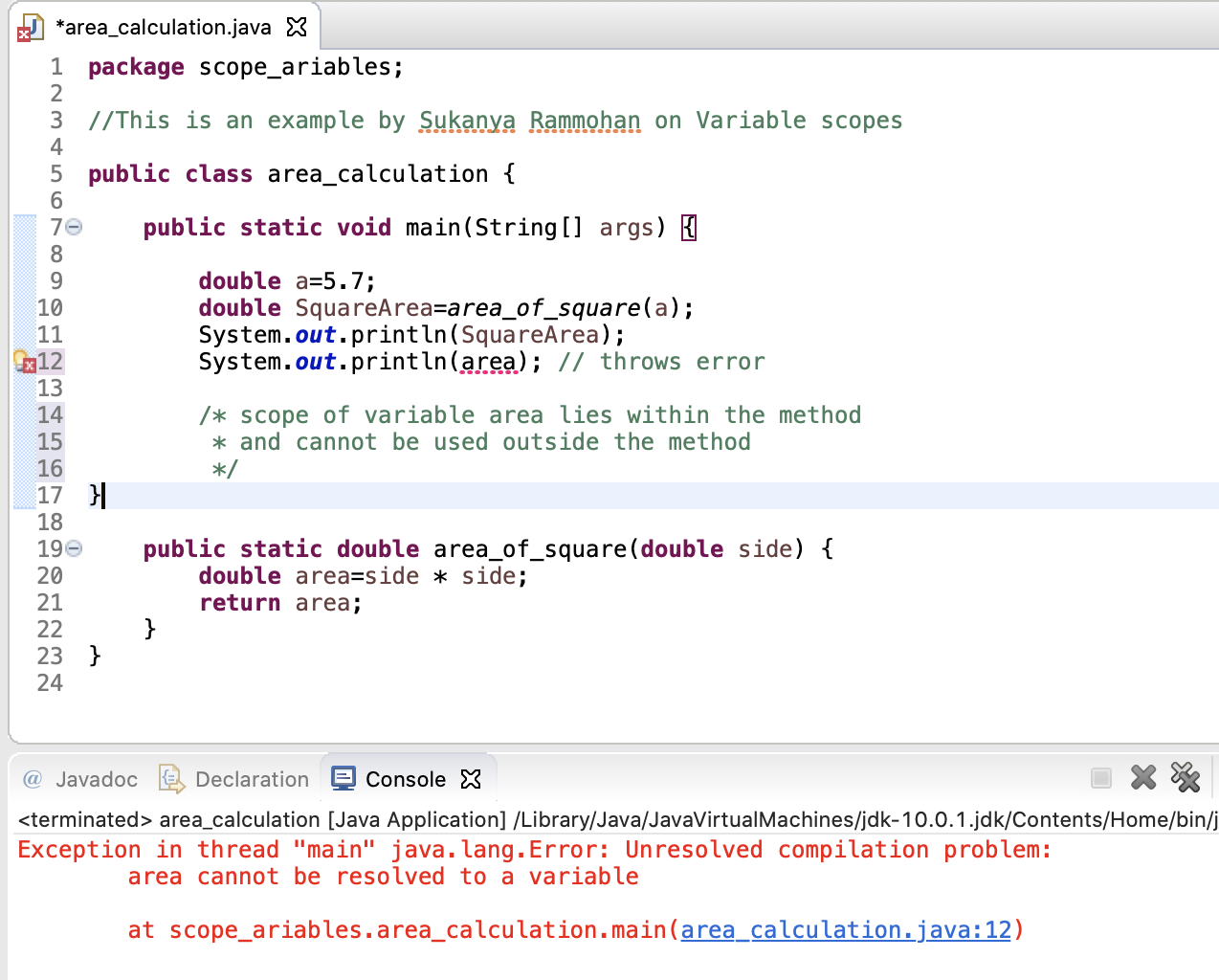
Local variables are also called as method variables. These variables are accessed only within the methods they are declared and the scope ends once the method is finished executing.
package scope_variables;
public class area_calculation {
public static void main(String[] args) {
double a = 5.7;
double SquareArea=area_of_square(a);
}
public static double area_of_square(double side) {
double area=side * side;
return area;
// scope of variable area is limited to this method
}
}
What happens to a local variable outside the method?
An error is thrown due to unresolved compilation problem
-
Class Variables (Non-Static):
The non-static class variables, which are also knows as member variables, can be accessed by only by creating the instance of the class. Unlike static variables where the variable is shared among the instances, here each instance has its unique copy of the variable. Hence the changes made by these instances do not affect the value of variables in other instances.
public class area_calculation {
int side = 10; // non-static variable
public static void main(String[] args)
{
// need an instance to access the non-static variable
area_calculation AreaCalc = new area_calculation();
System.out.println("The class variable is "
+ AreaCalc.side);
}
}
Scope based on access modifiers
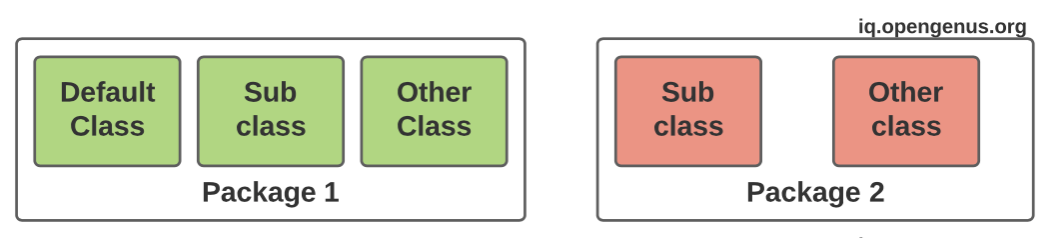
Sometimes, the scope of the declared class variables depends on the access modifier of the class. There are four types of access modifiers:
- Default
- Private
- Protected
- Public
- A default class, which has no specified modifier has its member variables easily accessible by the same class, its subclass in the same package, and different class in both same package. This is a package only access scope. For a good analogy to understand this concept, consider an on line class, where only specific students enrolled in the course can access the link.
-
The member variable of a private class can not be accessed by another other class irrespective of its package or sub-class status.To understand this, consider the example of your personal bank account, where only you can access the account.
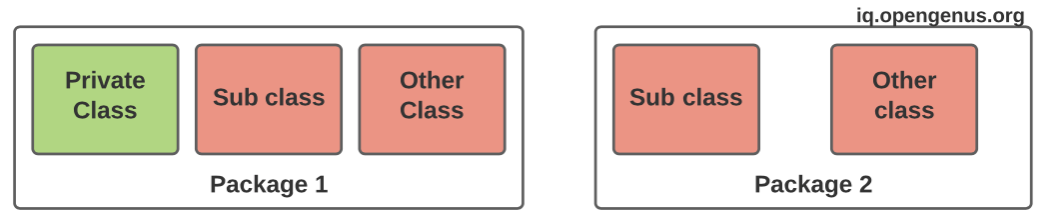
-
The class variable of protected class is accessed by both its subclass and non-subclass within the same package.Here, access is denied to only non-subclass in a different package. An example for protected class is your home. Whoever stays there including guests can stay. When a child from the house stays in a far away place, he or she can still keep his or her things at home.
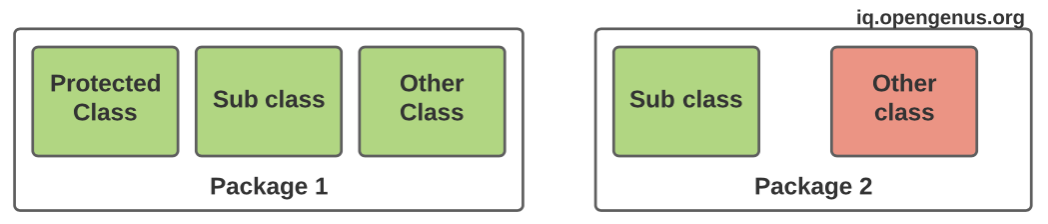
-
The member variables of public class has universal scope, which means that the variables declared as global variables are accessed by all the subclasses and non-subclasses that may be within or not within the package. Public classes are similar to public libraries, where anyone can access the materials with no restrictions.
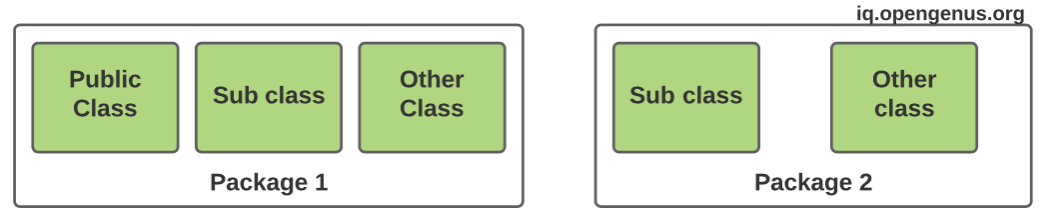
The following table shows the scope of variables based on access modifiers:
| Access Modifier | Default | Private | Protected | Public |
|---|---|---|---|---|
| Within Same Class | Yes | Yes | Yes | Yes |
| Sub class in the same package | Yes | No | Yes | Yes |
| Sub class in the different package | Yes | No | Yes | Yes |
| Non Sub class in the same package | No | No | Yes | Yes |
| Non Sub class in the same package | No | No | No | Yes |