
SSD has been defined as “a method for detecting objects in images using a single deep neural network”. But before we get into that let us first understand what object detection means. Object detection is a computer vision technique for locating and identifying objects in an image or video. For example, if an image contains a dog, a cat and a car, object detection helps us to classify the types of things in the image and also to locate them within the image.
Table of contents:
- How Is SSD Different?
- Multibox Concept
- SSD Architecture
- SSD vs YOLO
- Which Algorithm To Choose?
- Conclusion
Prerequisite: SSD MobileNetV1 architecture
We will be discussing about Single Shot Multibox Detector and also see how it fairs against YOLO, another single shot detector.
How Is SSD Different?
Single Shot Detection means that object localization and object classification are done in a single forward pass. SSD predicts category scores and box offsets for fixed default bounding boxes using filters that are applied to feature maps. In order to achieve high accuracy, different scale predictions are produced from the feature maps which are then separated by aspect ratio. As a result even on images with low resolution, high accuracy is achieved.
Other algorithms like R-CNN and Fast(er) R-CNN use object proposal methodology where the image is first broken down into different parts and suggests where the object could be potentially located. This leads to longer time for training and compromises with accuracy. YOLO and SSD were introduced to address the shortcomings of R-CNN and its successors. They speed up the process by removing the concept of object proposal method.
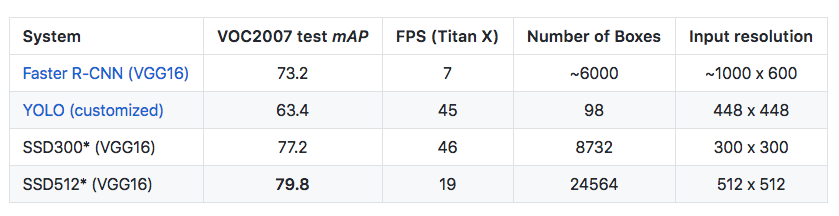
Multibox Concept
Ground truth means checking the oberved results against the actual results. In SSD, the image is broken into several segments and for every segment bounding boxes are created. Then each of the boxes are checked on the image for the classes the network has been trained on. Finally the predictions are compared with the ground truth. If any error is found then the weights are updated after back propagating through the network.
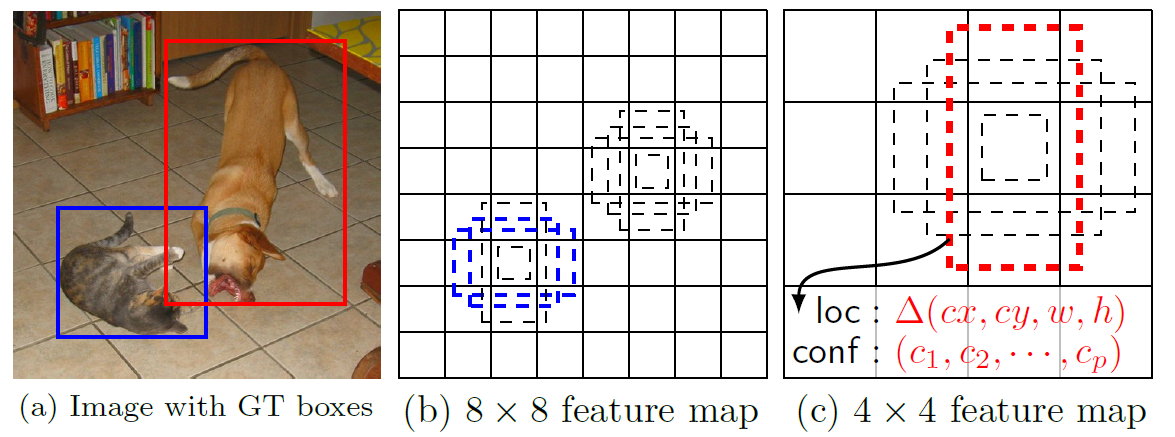
SSD Architecture
The paper about "SSD: Single Shot MultiBox Detector" (by C. Szegedy et al.) was publshed at the end of November, 2016.
SSD starts with a VGG-16 architecture but with the fully connected networks removed. Some extra convolutional layers are attached for handling bigger objects.
In the paper, VGG-16 has been used as the base network. With a faster and equally accurate network, the performance of SSD can be further improved.
The conv4_3 detects the smallest objects while the conv11_2 detects the biggest objects.
The SSD model is based on feed-forward convolutional network. It produces fixed-sized bounding boxes and scores if an object class instance is present in those boxes. During final predictions, a Non-maxima suppression algorithm is used.
SSD consists of two parts - a backbone model and SSD head. Backbone is a standard pre-trained image classification architecture which acts as a feature extractor. SSD head is an additional layer on top the backbone model.
Object detection in SSD takes place with the following features:
- Multi-scale feature maps - Convolutional layers are added to the end of the base network. SSD uses lower resolution layers for detecting larger objects.
- Convolutional predictors - After going through certain convolutions a feature size of
m x nis obtained with p channels. A3 x 3convolution is applied on thism x n x player. - Default boxes and aspect ratios - There are k bounding boxes of different size and aspect ratios for each location. For each box
cclass scores and4offsets relative to the original default bounding box shape are computed. Thus we get(c+4)kmnoutputs for a feature map ofm x n.
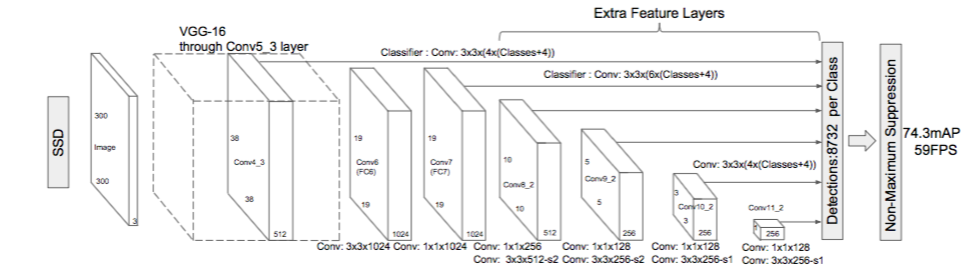
SSD vs YOLO
YOLO(You Only Look Once) is an object detection algorithm where the image is looked at only once to sight multiple objects. In YOLO every image is divided into a grid of size s x s and for every grid N bounding boxes and confidence are predicted. The confidence gives accuracy of the bounding box and tells whether any object is present in the bounding box. So a total of s x s x N boxes are predicted.
SSD looks at the image only once and develops a multiscale feature map which helps in detection of objects at different scales. SSD adds custom convolution layers at the end and convolution filters to make predictions. SSD also uses anchor boxes which are a collection of boxes at different spatial locations and aspect ratios. During training appropriate anchor boxes are matched with bounding boxes of each ground truth. Any box which has a Jaccard Index greater than 0.5 is considered as a match.
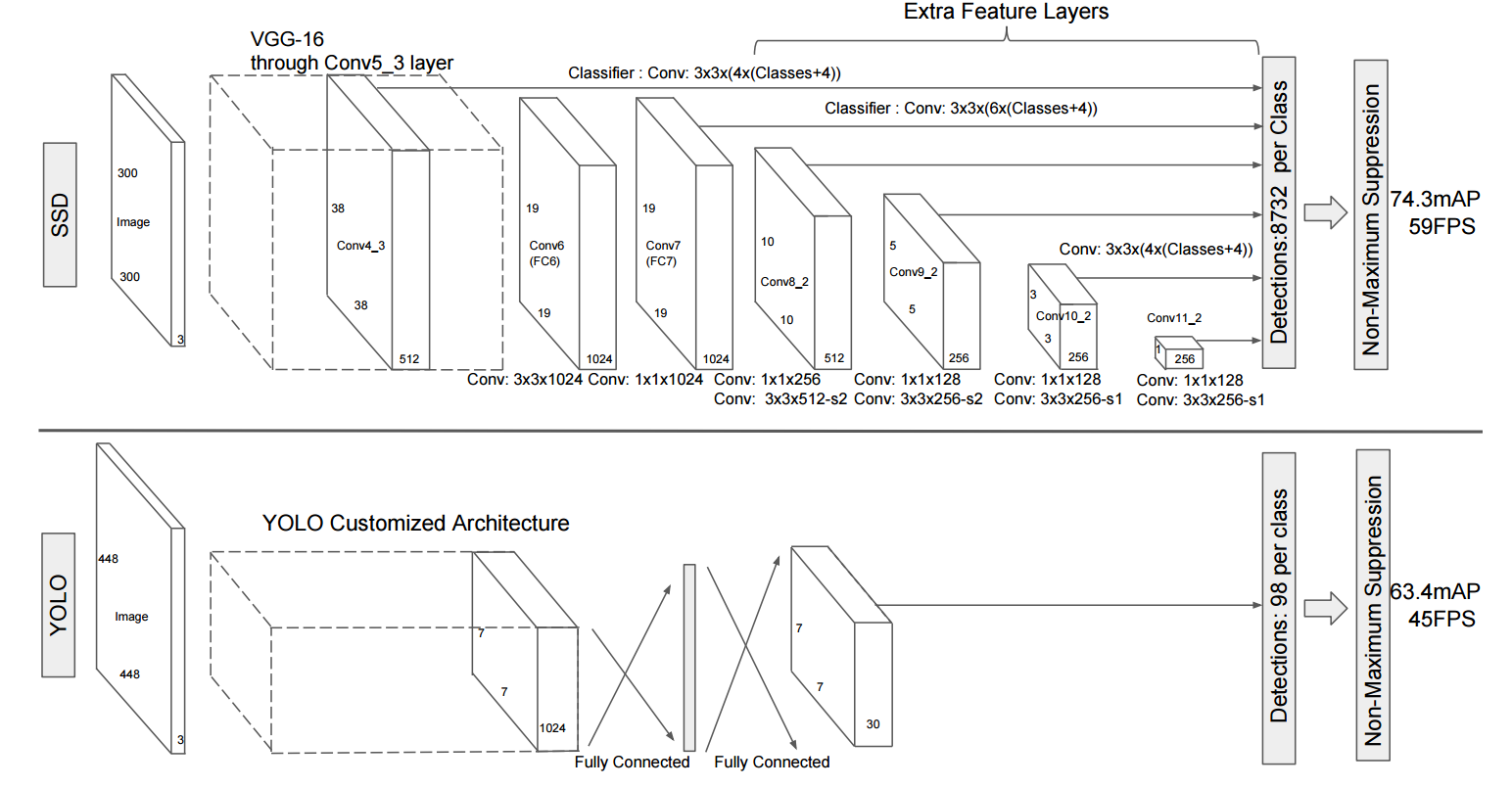
In SSD 8732 boxes are developed in comparison to 98 boxes in YOLO. As a result SSD outperforms YOLO in terms of accuracy but there is an impact on speed. YOLO is faster than SSD. Though SSD may have some problem in detecting smaller objects that are hard to detect in low resolution. In that case, the resolution of the input image has to be increases.
Which Algorithm To Choose?
If accuracy is the main priority then Faster R-CNN is the best option but if there is a bottleneck in computation power, then SSD is the go to option. SSD has a better speed-accuracy trade off and can also be run on videos. However, if accuracy is not much of a concern and there is a time crunch then YOLO should the choice.
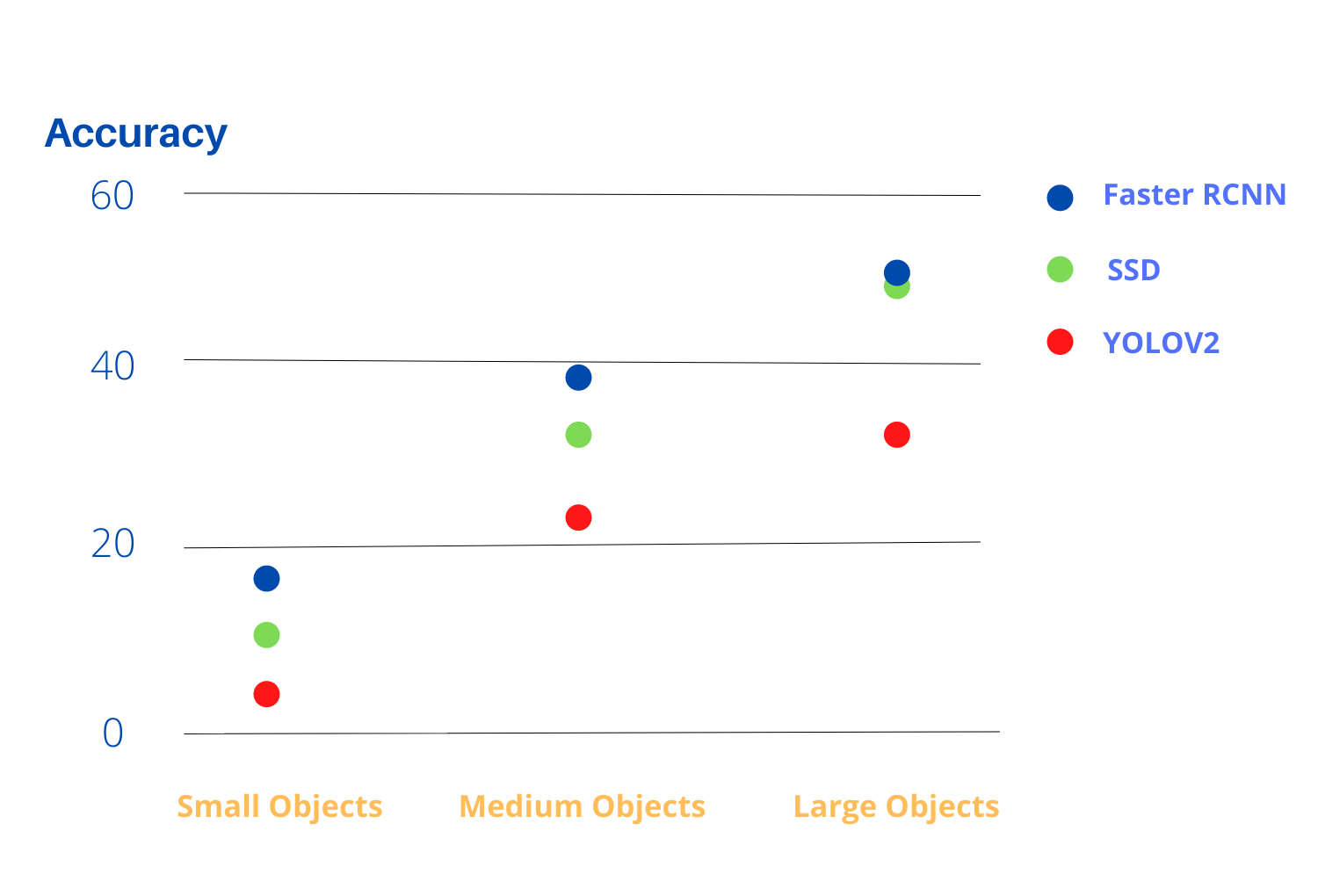
The above figure gives a comparison of accuracy for objects of different sizes.
At the end of the day, choosing the proper method is important and largely depends on the problem that is being solved.
Conclusion
This article at OpenGenus gives an overview of the SSD model architecture and also shows how it compares against YOLO.