
Today we cover Transformer Networks. These are all the rage nowadays in the machine learning world, especially in fields like Natural Language Processing where they have broken numerous records. Some of the most famous transformer networks are BERT and GPT, and you must have seen these abbreviations somewhere.
This post is a follow up to a previous post that introduced us to Generative Adversarial Networks (GANs), so do check that out first. After an introduction to how transformers work, and a brief look at how they process text data, we see how they can also generate images and audio data just like GANs.
A Brief Introduction to Transformers
It all started in 2017 with the well titled research paper "Attention Is All You Need". The researchers at Stanford University proposed a new architecture they called "the Transformer". To understand what they are all about, we need to first see what the researchers meant by attention.
Sequence-to-Sequence Learning (Seq2Seq)
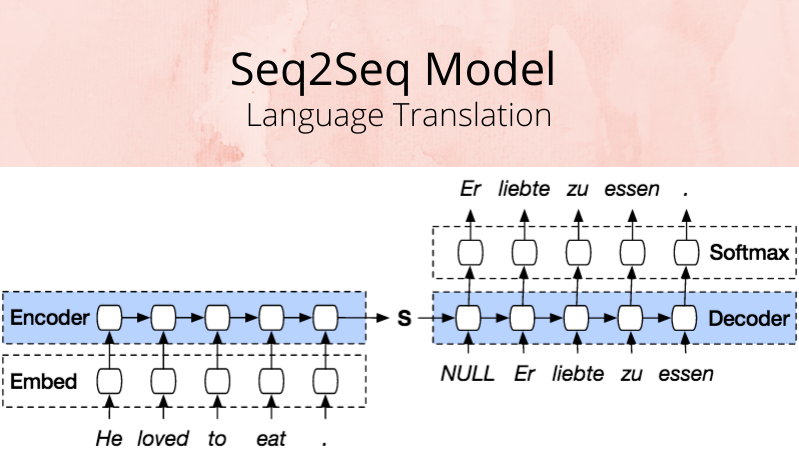
Transformer Networks are neural nets that transform a given sequence of elements, such as a sentence (a sequence of words), into another sequence. Naturally, an application of such a Seq2Seq model would be in language translation. LSTM-based models were used for these problems before, since they are good at handling sequence-dependent data (such as sentences, where a word in a sentence depends on the words that came before it, along with grammar rules).
Seq2Seq models consist of two separate parts that work together: an Encoder and a Decoder. The Encoder takes the input sequence and then it maps it into a higher dimensional space (this is a n-dimensional vector, which is fed to the Decoder). The Decoder which turns this vector into an output sequence. In the case of language translation, this output sequence will be in the desired language we wanted to translate to. Both of these parts - the Encoder and Decoder, can be built using LSTM models.
But what does attention mean?
The Seq2Seq model, in the case of language translation, will generate sentences word by word. The Attention Mechanism is the ability to focus on words that are important that came before the current word - a much more long-term memory. This is similar to how our memory keeps track of the words we read in a sentence to provide us context, while we read the words one by one. Thus - a transformer can pay attention to previous tokens that have been generated. These tokens will be parts of the sentence that are important and will be key terms that give the sentence context. During backpropagation the model learns how to identify these key terms.
The Transformer Architecture
As mentioned before, this novel architecture proposed by the researchers uses the Attention Mechanism. While RNNs (Recurrent Neural Networks such as LSTMs and GRUs) are also able to look back at dependencies in sequence-dependent data, their short term memory is what makes them different from transformers.
In the paper, the researchers proved that an architecture with only attention-mechanisms can beat previous results in the translation problem (and on other tasks). Here is what the architecture looked like:
- Encoder (pictured below as the left rectangle) - Maps an input sequence into an abstract continuous representation that holds all the learned information of that input
- Decoder (the right rectangle) - Generates a single output while also being fed the previous output using the output of the Encoder
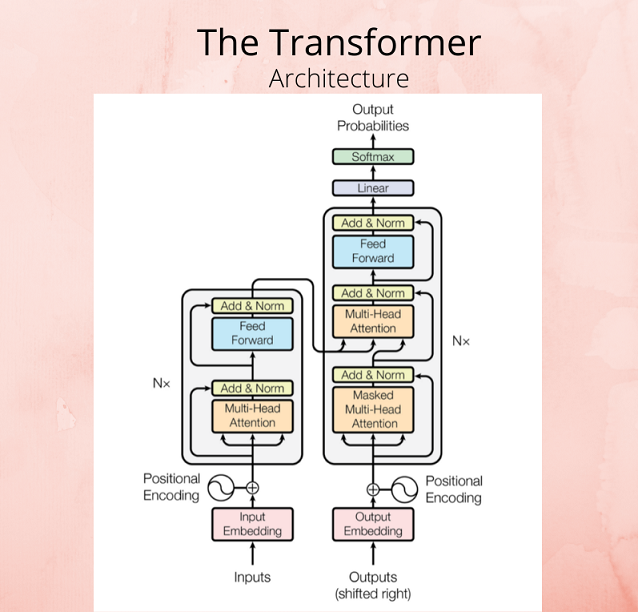
Now, for the translation problem, the sentence is first encoded as a vector where each word is mapped to a continuous value, and the position of each word is also embedded. This is the input fed to the Transformer. For an illustrated breakdown of how a sentence is translated, check this article by Michael Phi.
Instead of going through the architecture in detail, we shall first understand the concept of self-attention and how Transformers use this attention mechanism to generate data.
Self-Attention and Generative Models
Self-attention allows the Transformer to associate each word in the input to other words. So in our example ("He loved to eat."), it is possible that it learns to associate the word “eat”, with “food” and “lunch”. Each word is treated as a query and find some keys that correspond to other words, and produce a better embedding.
So far, we have seen how transformers work with text and are useful in NLP tasks such as translation. But how does the self-attention mechanism work for generative models in the case of other data, like images or audio?
Images and music often have repeating structures or "motifs" and these form the perfect inductive biases for transformers to work with - this is known as self-similarity. The same researchers at Stanford decided to use this fact to generate images based on probability. Self-similarity for images as a concept has been used even before however, such as for texture synthesis (Efros and Leung, 1999) and for image denoising by non-local means (Buades and Morel, 2005). Here is an example in one of the most iconic paintings of all time - the recurring stars in the sky:

Using probabilistic image generation, one can model the joint distribution of pixels and measure generalizations. In 2018, the researchers took the word embeddings for the text transformer, and replaced them with patches (small portions of the images), and it worked - the transformer computes associations based on similarity. With these architectural adjustments for pixels instead of words, transformers generated images as well. The computational cost for transformers rises linearly with an increase in the dimension of your data - so the attention windows had to be restricted to local neighbourhoods. While I am greatly simplifying, you can learn more in detail by reading the Image Transformer paper and checking out the references below. The transformer performed well on the CIFAR-10 dataset, and was used for conditional and unconditional image generation.
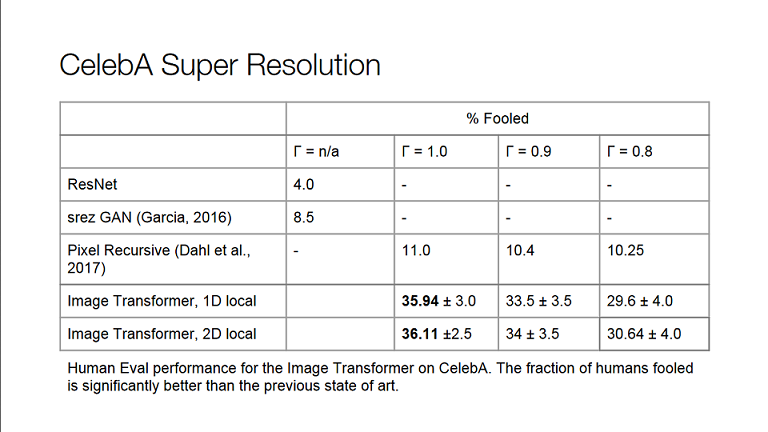
Another task their transformer performed well on was Super Resolution (the process of improving the detail in an image, upscaling). They worked on the CelebA dataset of celebrity images and fooled humans, outperforming the state of the art at the time and proving that Transformers could work with higher dimension data apart from text.
When it comes to audio generation, the architecture for the original transformer was tweaked yet again. The music we listen to undergoes a transformation from the score that a music composer writes, similar to how language we hear as speech is converted from text. The self-similarity concept comes to use here as well, because repetition is key to most music pieces.
Hopefully, this blog introduced you to transformers and how they can be used for applications other than in the field of Natural Language Processing - and potentially replace GANs when it comes to generating data. Thanks for reading.
References and Further Reading
An Illustrated Guide to TransformersGenerating the Future With Adversarial Transformers
Medium: What is a transformer?