
Xception is a deep convolutional neural network architecture that involves Depthwise Separable Convolutions. This network was introduced Francois Chollet who works at Google, Inc. (Fun-Fact: He is the creator of keras).
Xception is also known as “extreme” version of an Inception module. Hence, let us look at the Inception module before delving into Xception.
Inception Network
An inception network is a deep neural network (DNN) with a design that consists of repeating modules referred to as inception modules.
The name Inceptions probably sounds familiar to some readers, especially if you are a fan of the actor Leonardo DiCaprio or movie director, Christopher Nolan.
Inception (directed by Christopher Nolan) is a movie released in 2010, and the concepts of embedded dream state were the central premise of the film. This is where the name of the model was taken from.
In general, each layer if DNN is considered to extract some feature, then stacking these layers one abovee each other is not a great idea. Deep networks are prone to overfitting, and chaining multiple convolutional operations together increases the cost to train the network. Another issue is as each layer type extracts a different kind of information, how do we know which transformation (kernels) provides the most useful information to the DNN?
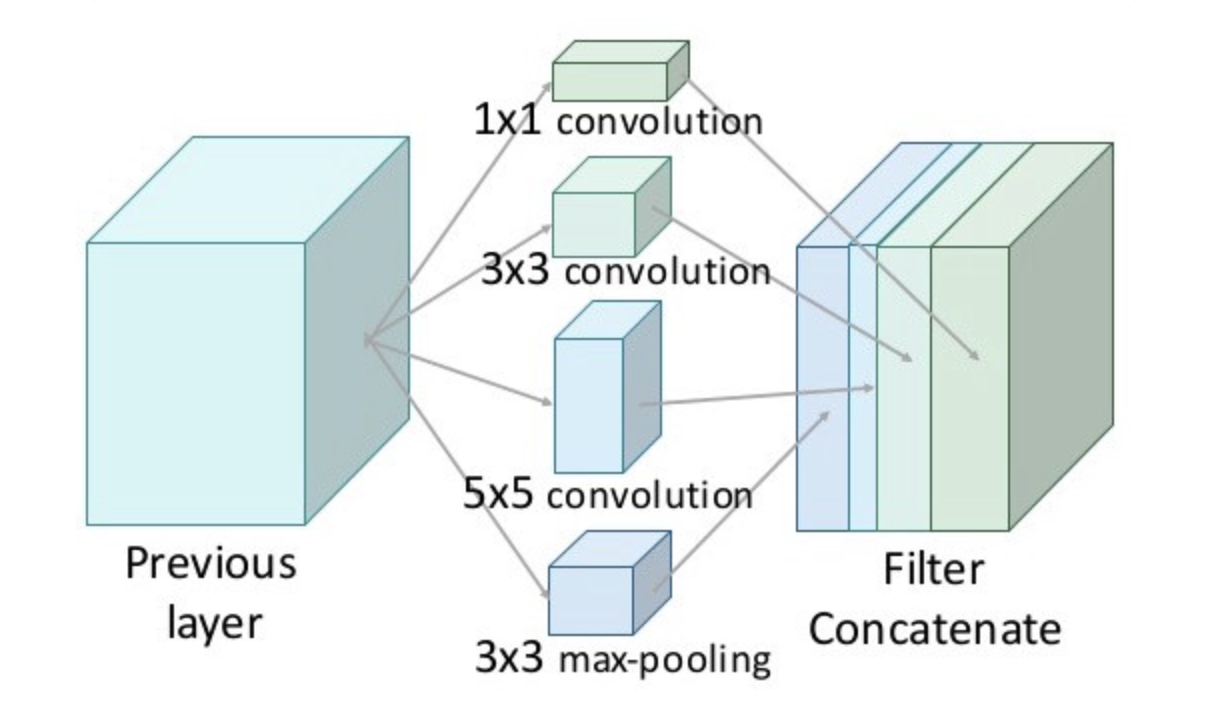
An Inception module computes multiple different transformations (as shown in the figure above) over the same input and then finally combining all the output which lets the model decide what features to take and by how much.
There is one problem. It is still computationally inefficient because of convolutions. These convolutions not only happens spatially, but also across the depth. So, for each additional filter, we have to perform convolution over the input depth to calculate just a single output map, and because of this, the depth becomes a huge bottleneck in the DNN.
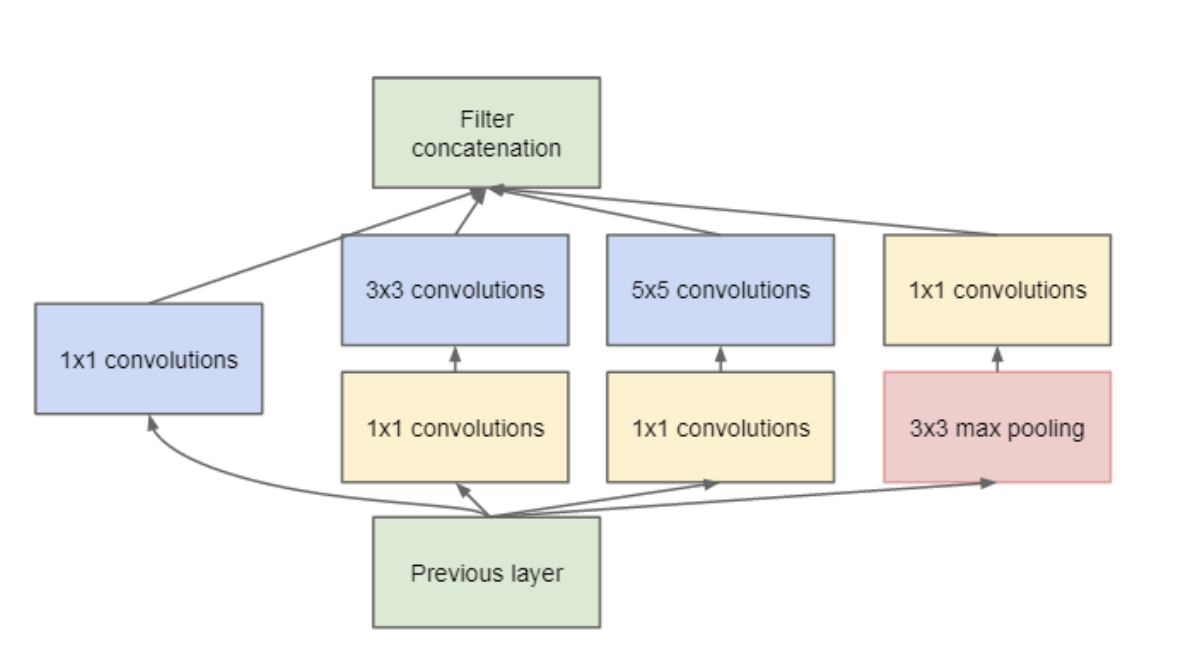
How about reduce the depth? This depth can be reeduced by doing 1X1 convolution acroos the depth. This convolution looks acrosss multiple channel's spatial information and compress it down to a lower dimension. For example, using 30 1x1 filters, input of size 128x128x100 (with 100 feature maps) can be compressed down to 128x128x30.
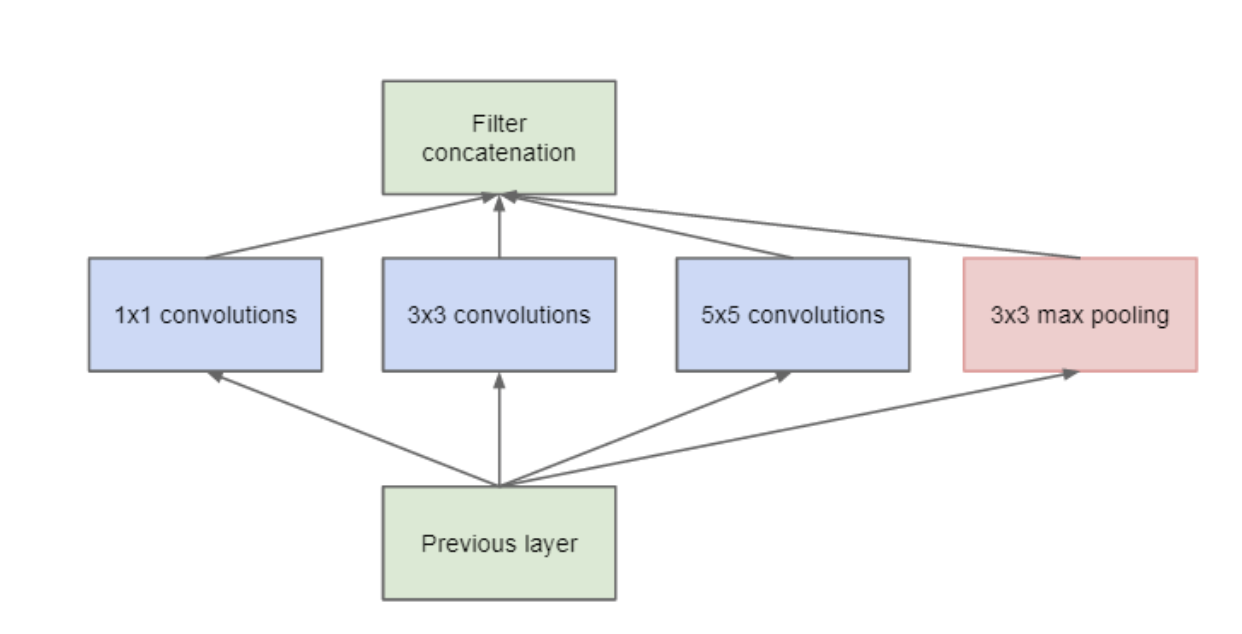
Due to this reduction, the researchers of Inception module were able to concatenate different layer transformations in parallel, resulting in DNN that was wide and deep. The images below shows difference between Inception module without 1X1 filters and one with 1X1 filters.
Xception
Xception stands for “extreme inception”, it takes the principles of Inception to an extreme. In Inception, 1x1 convolutions were used to compress the original input, and from each of those input spaces we used different type of filters on each of the depth space. Xception just reverses this step. Instead, it first applies the filters on each of the depth map and then finally compresses the input space using 1X1 convolution by applying it across the depth. This method is almost identical to a depthwise sepa- rable convolution, an operation that has been used in neural network design as early as 2014. There is one more difference between Inception and Xception. The presence or absence of a non-linearity after the first operation. In Inception model, both operations are followed by a ReLU non-linearity, however Xception doen't introduce any non-linearity.
What does Xception look like?
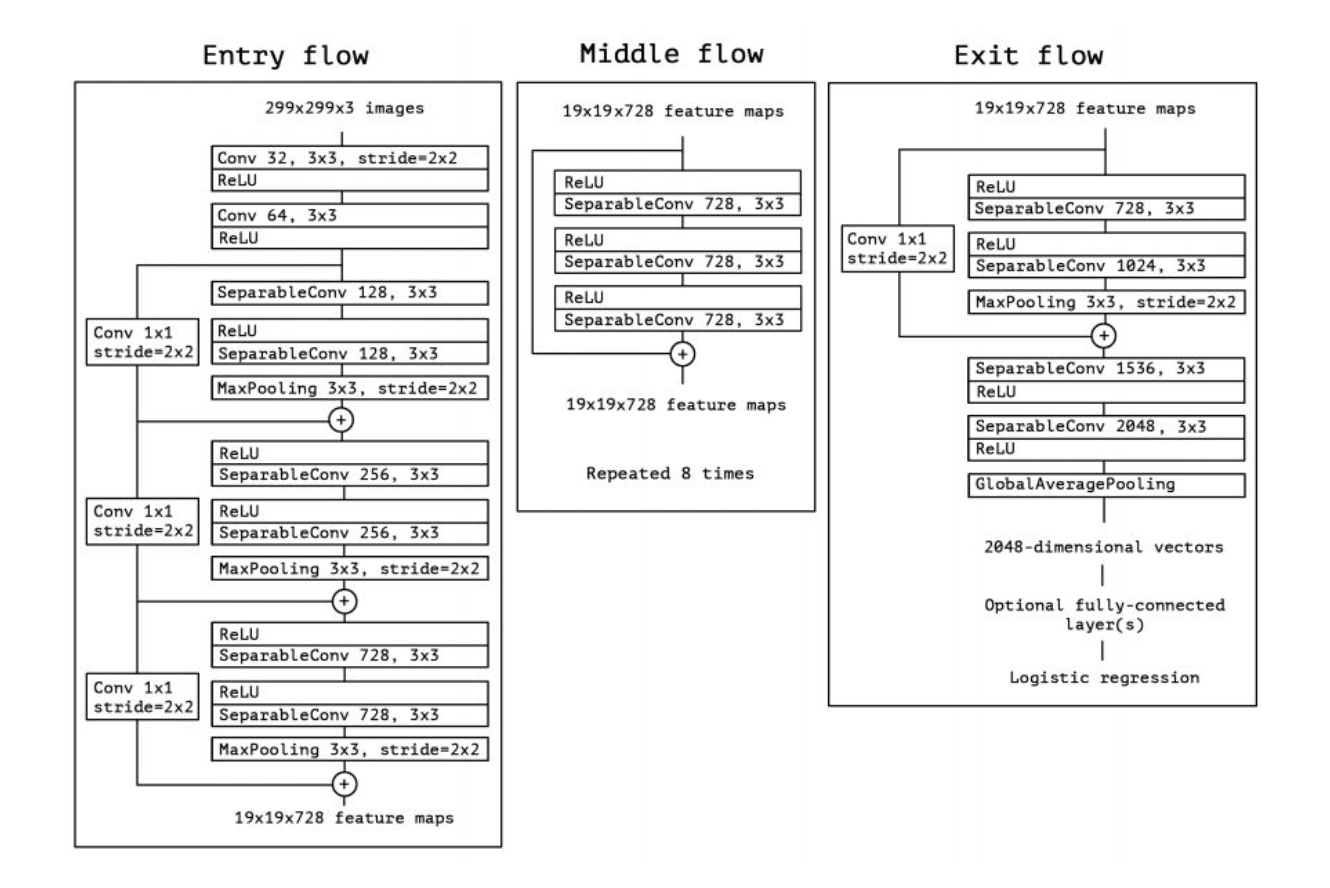
The data first goes through the entry flow, then after than it. goes through the middle flow (repeating itself 8 times in this middle flow), and finally through the exit flow.
Xception implemented using the TensorFlow framework by Google and trained on 60 NVIDIA K80 GPUs each.
Results
Table below shows that Xception outperforms every model in ImageNet dataset.
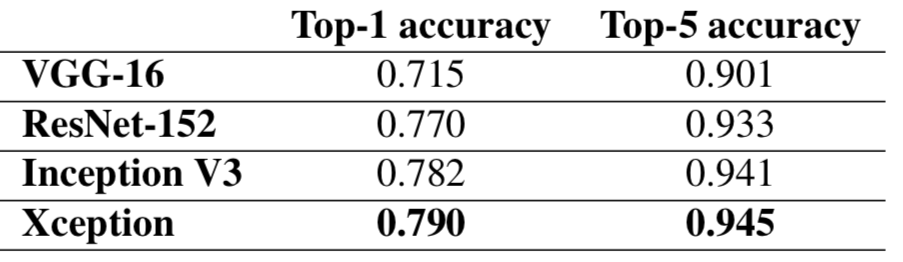
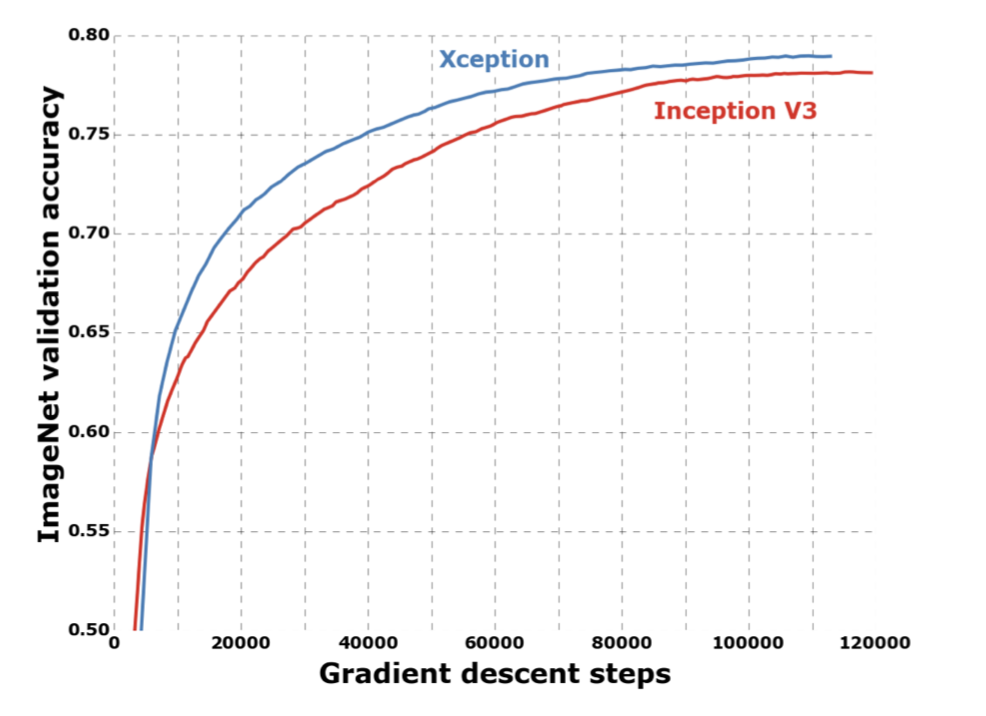
Validation accuracy is also higher for Xception than inception model shown below.
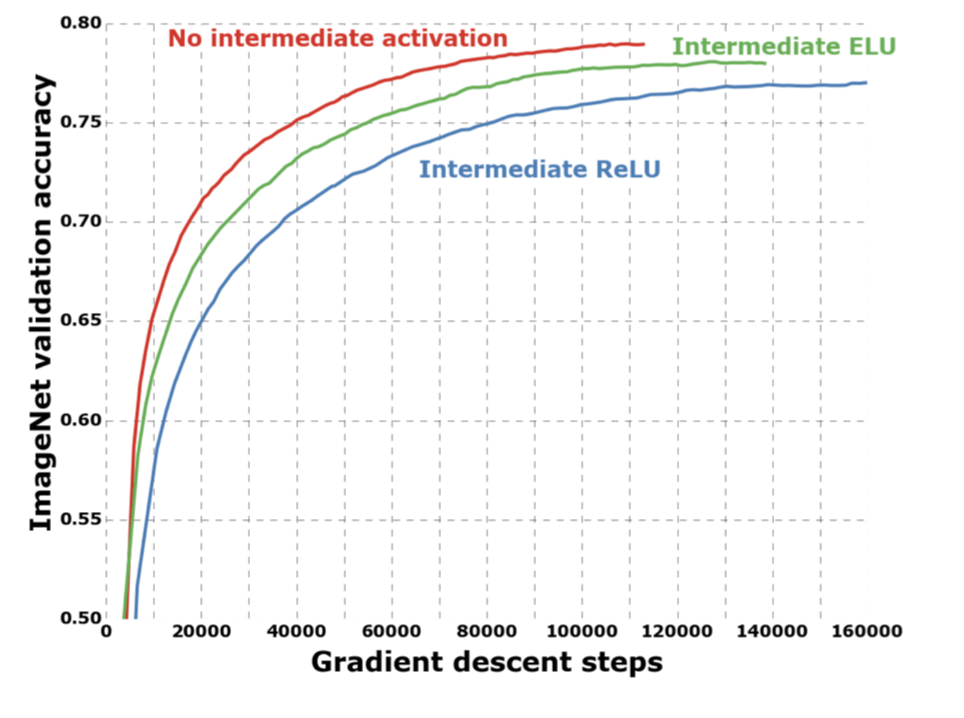
The graph below shows that having no non-linearity in between Xception performs better than having any kind on non-linearity.
Do check out the original research paper Xception: Deep Learning with Depthwise Separable Convolutions by Francois Chollet on ArXiv.