
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we have covered YOLOR model architecture in depth and compared it with other YOLO variants like YOLOv4.
Table of contents:
- Introduction to YOLOR
- YOLOR Architecture
- Implementation of YOLOR
- YOLOR vs other YOLO models
- Conclusion
Introduction to YOLOR
YOLOR- You Only Learn One Representation is a machine learning/deep learning algorithm used for computer vision tasks mainly object detection. Object detection can be defined as finding the boundary box of the object and classifying what object it is.
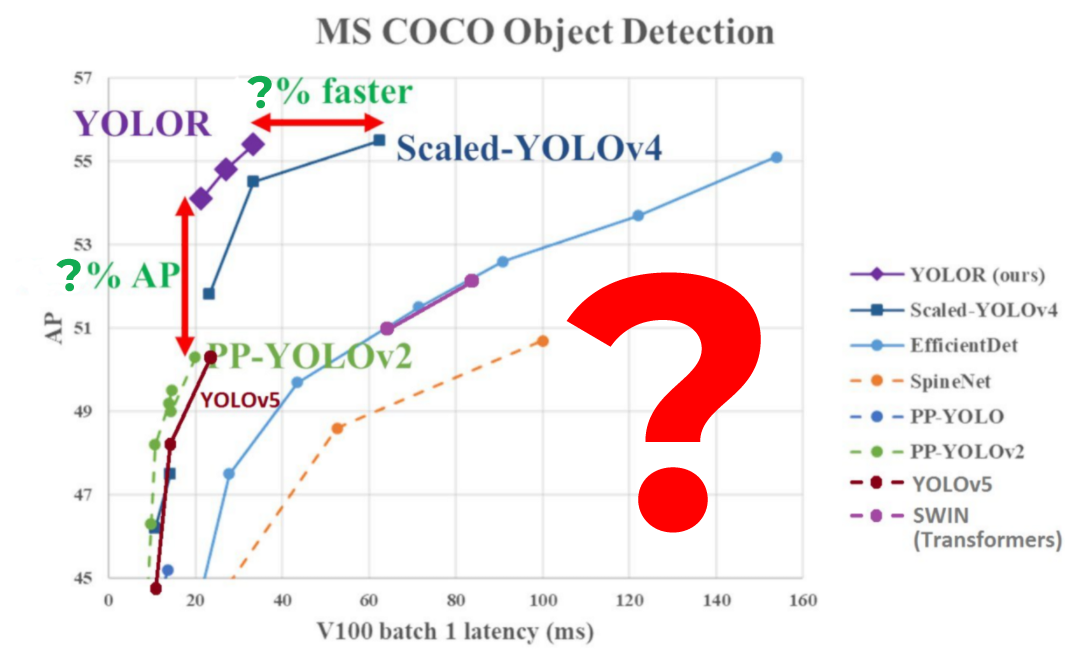
The YOLOR is a model that is faster and has higher accuracy when compared to that of the previously proposed models such as YOLOv4, Scaled YOLOv4 , Yolov5 , etc. All these models are proposed by the same author and are trained on the same dataset that is , the coco dataset. YOLOR is approximately 88% faster than the Scaled-YOLOv4 models.
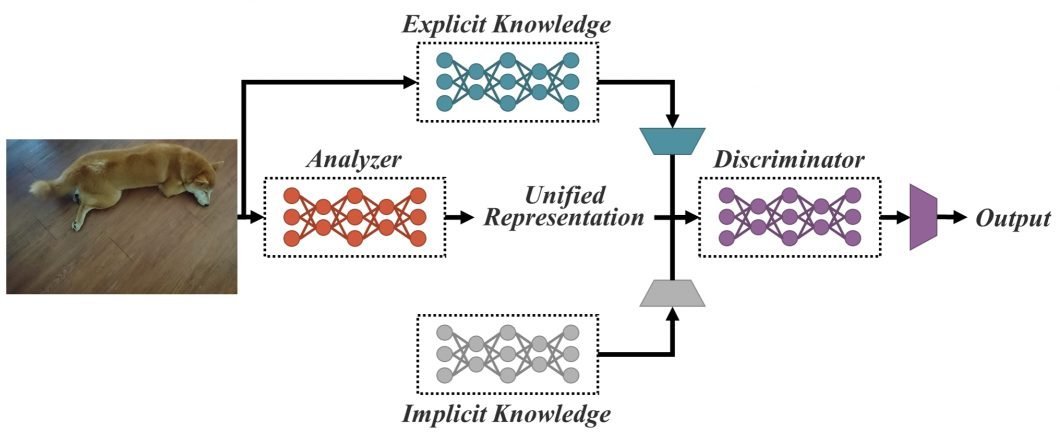
This model also aims to make use of implicit and explicit knowledge and encode them as one.
What is Explicit Knowledge?
Explicit knowledge can be termed as any data that can be expressed in the written form and be understood in away such that certain conclusions could be drawn. These data are fact based and could be obtained using shallow neural networks.Conscious learning generates explicit knowledge.
What is implicit knowledge?
Implicit knowledge can be defined as the detailed feature extraction from given data whereas explicit is rough feature extraction. Implicit knowledge can be obtained using deep neural networks.Subconscious learning generates implicit learning.
The introduction of implicit knowledge along with explicit knowledge results in better performance in various tasks like kernel space allignment, prediction refinement and multi task learning.
Generally ,a neural network fulfills only a single objective and hence to perform different tasks different neural networks need to be designed.YOLOR overcomes this shortcoming and serves the purpose of multi tasking and fulfilling multiple objectives all at once by using the implicit knowledge as well as the explicit knowledge.
Implicit knowledge formulation:
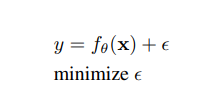
Here ,in the above formula y represents the target of a certain task , x represents observation , θ(theta) represents set of parameters in neural networks, whereas f represent the function performing given operation. ɛ (Epsilon) on the other hand represents the error rate.
The error rate needs to be constantly reduced.
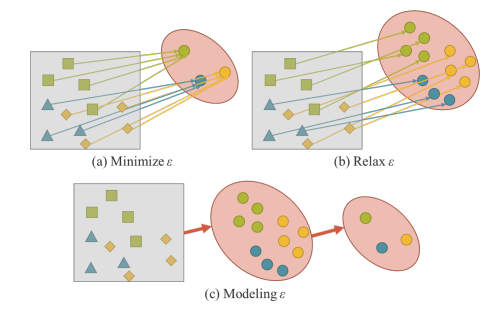
The error rate (ɛ) needs to be minimized as in to achieve the given target . To achieve the generalization of model being able to solve all problems in domain T , the relaxation of ɛ is done , and finally to achieve ti the modelling of error rate is done.
General formulation of both implicit and explicit:
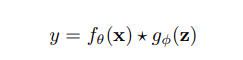
The formulation of implicit is combined with that of explicit knowledge with the use of combining operator. Combining operator is either addition or concatenation operator.
Modeling Implicit knowledge:
Implicit knowledge could be modelled in three formats:
- Vector
- Neural Network
- Matrix Factorization
Vector is used as direct implicit representation.
Neural network uses the above vector and adds weight to it and further performs linear combination or non linearization to represent implicit knowledge.
As for the matrix factorization multiple vectors are taken with prior basis of knowledge and a coefficient and are represented to gether as implicit representation of knowledge.
The modeling of implicit knowledge highly depends on the complexity of the implicit knowledge present or to be gained.
YOLOR Architecture
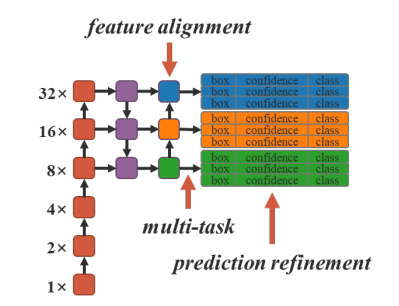
The architecture of this model YOLOR proposes a single neural network to perform multiple tasks like feature allignment, prediction refinement and multi-task learning.
Multi task learning includes performing tasks like detecting objects, multi label image classification , feature embedding.Feature embedding refers to the process of extracting features and classifying them based on the attributes of these features.Prediction refinement on the other hand enhances the model by performing correction using loss function.
All these features work with the help of 7 convolutional layers present within the YOLOR architecture along with maxpool layer.
Implementation of YOLOR
Training:
Yolor can be trained using a custom dataset by using the pytorch module.
python -m torch.distributed.launch --nproc_per_node 2 --master_port 9527 train.py --batch-size 16 --img 1280 1280 --data coco.yaml --cfg cfg/yolor_p6.cfg --weights '' --device 0,1 --sync-bn --name yolor_p6 --hyp hyp.scratch.1280.yaml --epochs 300
Inference:
Object is detected and the boundary box for each object is displayed along with the object name and there confidence score.
python detect.py --source inference/images/horses.jpg --cfg cfg/yolor_p6.cfg --weights yolor_p6.pt --conf 0.25 --img-size 1280 --device 0

YOLOR vs other YOLO models
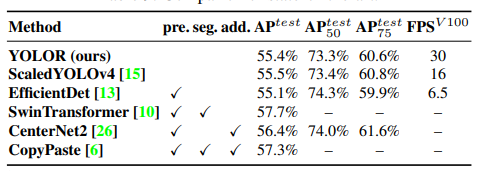
pre - large dataset image classification pre training
seg - training with segmentation ground truth
add - training with additional images
In the above table as you can see ,the FPS of ScaledYOLOv4 is half of that of YOLOR , meaning that 30FPS can be processed in YOLOR. The average precision of YOLOR is almost similar to that of ScaledYOLOv4.
YOLOR vs YOLOV4:
As I have mentioned befor the YOLOR is faster and more accurate than YOLOv4. The accuracy precision of YOLOR model when compared to that of the YOLOv4 is approximately 2-3% better whereas the processing of frames per second is approximately 300% better than that of YOLOv4.
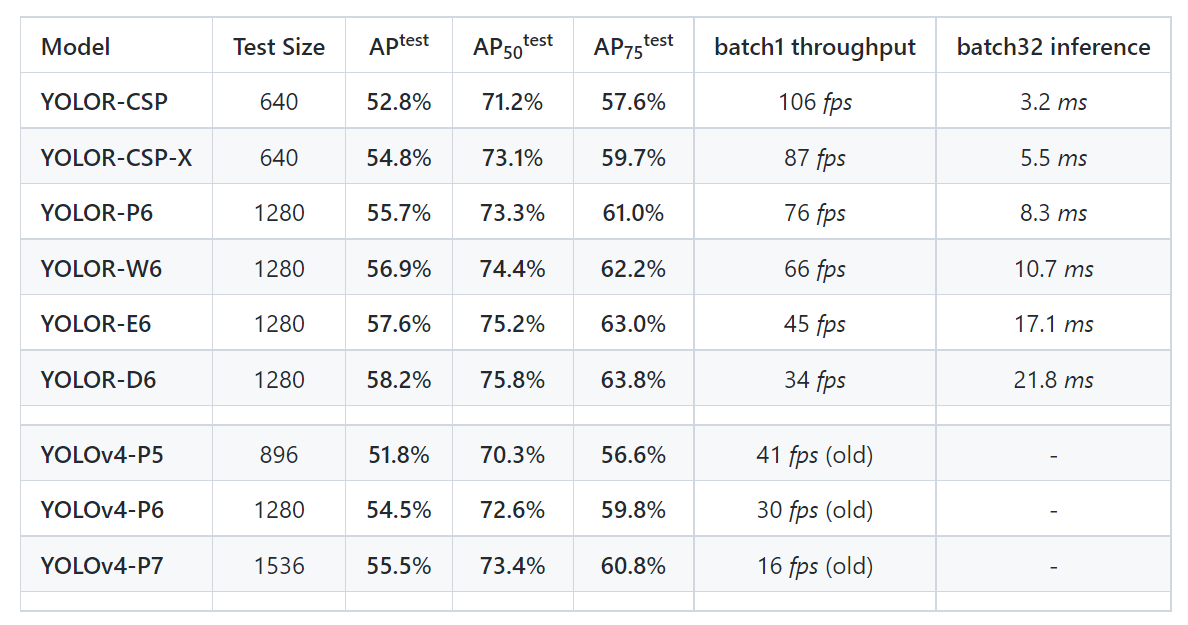
The mean average precision of YOLOR is nearly 58% whereas of YOLOv4 is 55%. Considering all these factors it would be quite relevant to say that YOLOR has a better functionality when compared to that of YOLOv4.
FAQs:
What is meant by tacit knowledge?
-> Soln: Tacit knowledge are knowledge gained by experience and they are quite hard to be explained.
Example - Riding a bike.
How does the YOLOR model visualize the input images?
->Soln: Yolor creates augmented images to better detect objects present in the input. YOLOR can visualize both augmented as well as the original image.
Conclusion
The performance and accuracy of YOLOR is better than that of YOLOv4,Scaled YOLOv4 and lower versions. The object detection functioning is provided with feature alignment,multi tasking and prediction refinement.
The output of this model is provided with boundary box of object along with the confidence score and the class of the object that it belongs to. In short, this models highly enables the ability of the machine to detect objects with high accuracy.
With this article at OpenGenus, you must have the complete idea of YOLOR model.