
In this article, we have covered common ML tasks/ applications with respect to image and textual data along with the models used and examples of its use in various domains.
Contents
The different Machine Learning applications are:
- Applications using Image Analysis
- Image Correction, Sharpening, Resolution & Colour Correction
- Image Classification
- Object Detection
- Image Segmentation
- 3D Projection
- Pattern Recognition
- Frame Prediction
- Image/Video Summarization
- Applications using Text Analysis
- Text Classification
- Information Extraction & Retrieval
- Document Summarization
- Named Entity Recognition
Applications using Image Analysis
Image recognition, a subcategory of the domains of Artificial Intelligence (A.I.) and Computer vision (CV), is the ability of applications to detect and identify the content of an image such as people, objects, landmarks, etc by analysing the images.
The different tasks that are performed using image analysis are as follows: (The tasks given below can also be applied to videos as they are basically a sequence of images that are displayed at a rapid rate to create the illusion of continuity and motion.)
-
Image Correction, Sharpening, Resolution & Colour Correction: These tasks can be used to enhance input images that are unclear, blurred, etc for better processing. This is often applied by image editing software and in the medical domain to improve the diagnostics process.
-
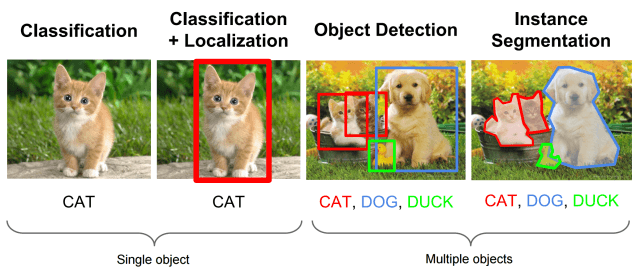
Image Classification: In this the category to which an image or an object within the image belongs to is identified. An example of this is Google Lens.
-
Object Detection: This helps in locating an object(s) within an image. It draws bounding boxes over the object which is especially helpful in videos to follow a particular object in a scene. This application is commonly used along with image classification to label the objects detected.
-
Image Segmentation: This is similar to detection, except it allows for a higher degree of precision when locating objects by delving to a granular or pixel level
-
3D Projection: Projection is a process which is used to transform a 3D object into a 2D plane. This is done by performing mathematical transfoRmations on the image vectors.
-
Pattern recognition: Image processing is used to detect any patterns (if present) in the image. This is used for handwriting analysis, computer-aided medical diagnosis and more
-
Frame prediction: In this application, future frames of the video can be sampled based on a single input image
-
Image/Video Summarization: In this process, the important or relevant features or frames in an image or video respectively are identified and summarized.
Input
Popular image datasets include the Intel Image Dataset for Classification, MNIST, Blood Cell images, ImageNet and more. Images are formed of pixels which are varying combinations of red, blue & green. Each image is represented by a 2 dimensional (for gray scale images) or a 3 dimensional (for colour images) rectangular array of numerical values (for each pixel) for each of the RGB channels to enable image processing by machines.
Models
The encoded representations are typically passed to a deep learning model such as a CNN, to allow for feature extraction. Some of the top pre-trained CNN models for each task are listed below:
- Classification- VGG-16, ResNet50, Inceptionv3, EfficientNet
- Object Detection- R-CNN, SSD, SPP-net, YOLO
- Segmentation- Mask R-CNN, HOG
These models are used to transfer knowledge and can be modified as per the requirements of the suer, by tuning the parameters, adding or removing layers and so on.
Output
Depending on the task performed by the model, the output of the model can be a label (s) or tags (think Facebook's auto tagging feature!), text (for applications such as image captioning), etc, depending on the application.
Applications using Text Analysis
Various forms of textual information such a social media posts, documents, emails, etc can be analyzed using a combination of NLP (text preprocessing, parts-of-speech tagging, sentence encoding, etc) & ML (deep learning models such as LSTMs & GRUs) to gain valuable insights. Text analysis is performed for the following tasks:
-
Text Classification: This is the process by which text is assigned predefined tags or categories depending on the contents of the text. This is commonly for tasks such as sentiment analysis, topic analysis, identifying spam mail, etc
-
Information extraction & retrieval: It is a process in which entities and relationships are examined to identify useful information. This technique is commonly used for applications such as document summarization. A real-world example of this is the Google Search Engine which uses this technique to suggest autofills for the search query and derive relevant documents from across the web.
-
Document summarization: It is the process of generating a summary that provided the most important or relevant information from the original text.
-
Named entity recognition: In this, named entities within the text are located and categorized. The categories include locations, person names, organization, etc. For examples, "New York" would be classified as a 'Location'.
Input
The raw textual data often requires to be preprocessed before it can be fed to the model. This is achieved by applying Natural Language Preprocessing techniques on the data. Some of the common task involved in this process include:
-
Tokenization: This breaks up text into its individual units or tokens, i.e. words. E.g. "The cat sat on the mat" becomes ["The", "cat", "sat", "on", "the", "mat"]
-
Part-of-Speech (POS) tagging: This refers to the process of assigning a grammatical category, such as noun, verb, etc. to the tokens
-
Lemmatization: This converts words to their root forms or 'lemma', depending on their context. E.g. "to meet", "meeting", "meets" are converted to "meet"
-
Stopword Removal: Stopwords are words that do not provide any relavant information such as, "and", "or", "the", etc. However, the list of stopwords varies depending on text and language being analysed
Some famous textual datasets are IMDB Dataset, Amazon Reviews and Sentiment140 Project
Models
The preprocessed data needs to be transformed into vectors which are numerical representation of the data so that a machine can understand and anaylse it easily. Commonly used text encoding methods are Bag-of-Words (BOW), TF-IDF, BERT, Word2Vector, etc. The encoded representations are then fed into ML-based text analysing models such as Recurrent Neural Networks (RNNs) or if, the application requires context to be remembered for longer periods of time, LSTMs or GRUs are used.
Output
Depending on the task at hand, the models output labels or tags, generate sentences, provide similarity scores and more.
An in-depth overview of the applications of NLP can be found here and here.
Conclusion
The above models mentioned can also be coupled depending on the application requirements. For example, for an image captioning task, an encoder-decoder architecture is used in which an image is fed to a CNN (encoder), which performs feature extraction and that is then given as input to a RNN (decoder), which is responsible for translating the features into a semantically and syntactically correct caption for the image.

We hope this article at OpenGenus proved useful to you in learning about the use of ML across various tasks and encourages you to explore and apply them in your own applications as well!:)