
BERT large model is a pretrained model on English language which uses a Masked Language Modeling (MLM for short). It has 24 encoder layers. The model was first introduced in this paper and subsequently released in this repository.
Pre-requisite: BERT model, BERT for text summarization
Table of content:
- What is BERT Large?
- A world before BERT: Word2Vec and GloVe
2.1 Elimination of Polysemy: ELMo and ULMFiT
2.2 And now BERT - A look under BERT Large's architecture
3.1 Text pre-processing
3.2 Pre-training
3.2.1 Masked Language Modelling
3.2.2 Next Sentence Prediction - Conclusion
Let us get started with BERT Large Model.
1. What is BERT Large?
BERT stands for Bidirectional Encoder Representations from Transformers. That sounds a lot to take in just one go. Let's take each word step by step.
Firstly, BERT is based on the Transformer architecture. Transformer, not the movie one, is a model which uses the mechanism of attention which weighs the significane of each part of the input. Used primarily in Natural Language Processing, it aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease
Second, the BERT model is pre-trained. And by saying pre-trained, I mean it. It is trained on a very large corpus of unlabelled text which includes the entire Wikipedia (2,500 million words!) and the Book Corpus (800 million words). The amount of pre-training done is crucial for any NLP task. Having a large text corpus enables the model to pick deeper meaning in the connections of sentences and how the language works.
Third, the B in BERT stands for "Bidirectional". This means that BERT can learn information from both directions: left and right side of a token during its training. Take a look at the following example:
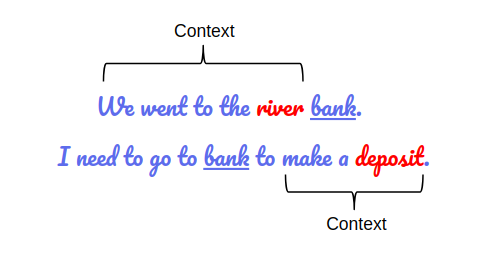
In both the sentences, there is the use of the word "bank". If we only consider a unidirectional nature of the word by choosing either left or right context, we will fail to retrieve information in at least one of the two sentences. The model will generate an error. BERT eliminates this problem by being deeply bidirectional.
Finally, just by adding your own set of output layers, we can create state-of-the-art models for a variety of NLP tasks.
BERT Large is a variant of BERT model.
2. A world before BERT: Word2Vec and GloVe
The following is an excerpt from Google AI:
"One of the biggest challenges in natural language processing is the shortage of training data. Because NLP is a diversified field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-labelled training examples."
Learning language representations using pre-trained models on large set of data (mostly unlabelled text data) made the way for word embeddings like Word2Vec and GloVe. These word embeddings made a change in which we performed NLP tasks previously. With the help of word embeddings, we were able to capture the relationship between words and with this learning, we trained models on various NLP tasks to make better predictions. However, there were two major limitations.
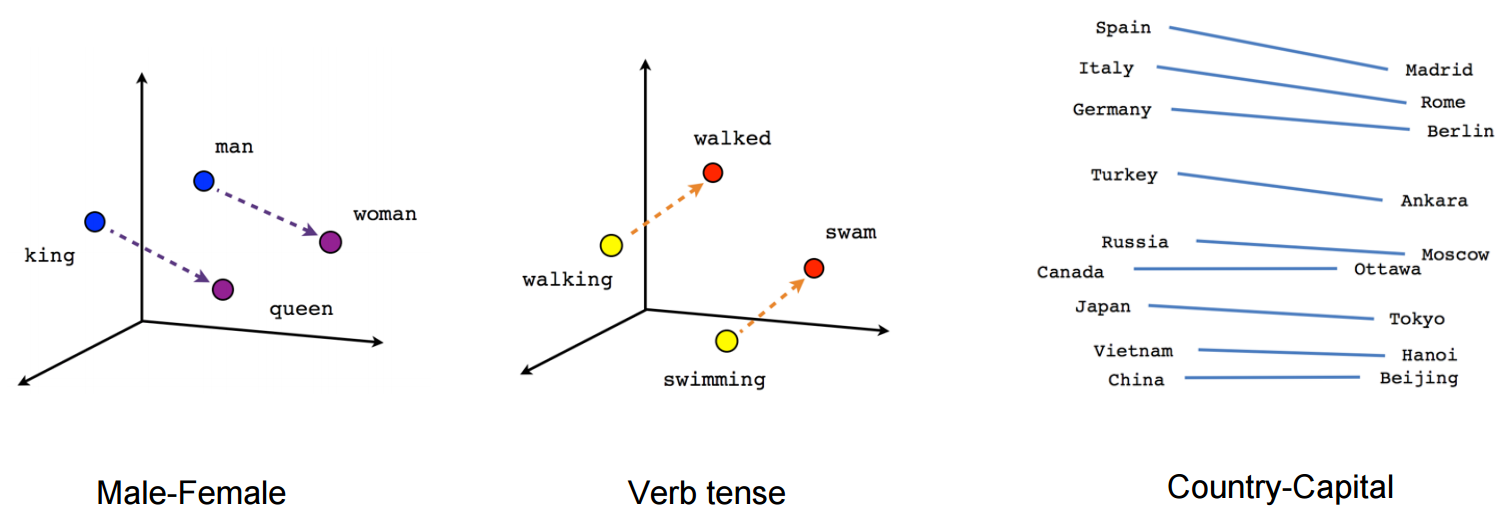
First, these word embeddings used very shallow Language Models. A Language Model is used to learn the probability of a sequence of words. Since they were shallow (not having a deep neural network), there was an extent to which these models could capture the information. The use of LSTMs and GRUs were implemented to prepare a deep and complex language model.
Second, these models did not take the context into account. Recall the "bank" example above. With no such information about the context, these word embeddings will give the same vector in both cases. This results in useful information being lost. This limitation got its own name, Polysemy: Same word, different meaning (based on context).
2.1 Elimination of Polysemy: ELMo and ULMFiT
ELMo, or Embeddings from Language Models, used complex Bi-directional LSTM layers to eliminate polysemy. Relying on the context, a same word can have multiple ELMo embeddings. It was also the time when we realised the power of pre-training in NLP.
ULMFiT, or Universal Language Model Fine-tuning, was even better! It used transfer learning to provide exceptional results on various document classification tasks.
2.2 And now BERT
With previous knowledge, a new approach in solving NLP tasks was formed. It became a two-step process which comprised of:
- Training a language mode on large, unlabelled data and,
- Fine-tuning this large model to application-specific NLP tasks.
3. A look under BERT Large's architecture
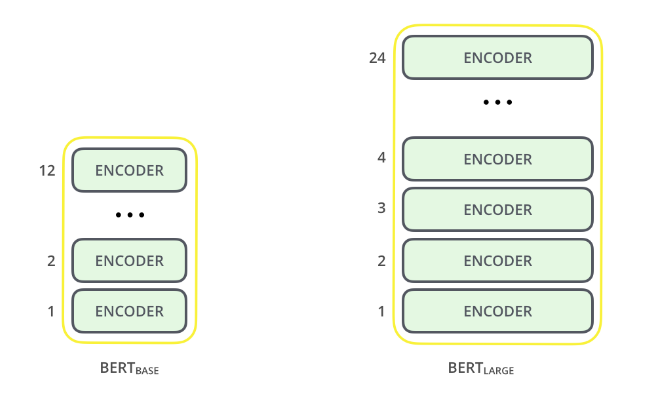
Right at the beginning, I told you that BERT Large is a transformer. The entire architecture of BERT is built on top of a transformer. There are two types of BERT (or I should say two variants):
- BERT Base, which has 12 layers of transformer blocks, 12 attention heads, and 110 million parameters and,
- BERT Large, which has 24 layers of transformer blocks, 16 attention heads and, 340 million parameters
3.1 Text pre-processing
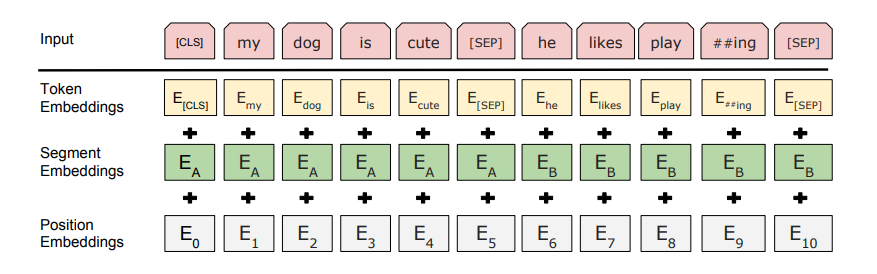
Moving onto pre-processing, every input embedding is an amalgamation of 3 embeddings governed by certain rules:
- Position Embeddings: Expresses the position of words in a sentence. Overcomes the limitation of capturing the "sequence" or "order" of information.
- Segment Embeddings: Enables BERT to take sentence pairs as inputs (like Q/A). It learns a unique embedding for the first and the second sentences which helps the model distinguish between sentences. Looking at the example above, all the tokens marked as EA belong to sentence A (and similarly for EB).
- Token Embeddings: Learned for specific tokens from the WordPiece token vocabulary.
To form the input for any given token, a sum of its corressponding position, segment and token embeddings is taken. This provides a lot of information to the user making BERT so versatile. We do not have to change the architecture of the model to make it useful for different NLP tasks; we can use the same model albeit with some tweaks necessary to meet the needs of the task in hand.
3.2 Pre-training
I have mentioned earlier in the article that BERT performs pre-training. BERT performs pre-training on two tasks:
- Masked Language Modelling
- Next Sentence Prediction
We shall see the above mentioned tasks in a little more detail.
3.2.1 Masked Language Modelling
We know that BERT is a deep bidirectional model. This means that it takes meaning of a word by taking both left and right context into account.
Traditionally, we were restricted to gather information in only one direction (unidirectional). GPTs (Generative Pre-trained Transformer) is an example of gathering information in right-to-left context only. There were other which did in left-to-right context. This made the models susceptible to errors and in valuable information getting lost. Predicting next word in a sequence will be difficult in a unidirectional model.
ELMo solved this issue by training two LSTM language models with one working on left-to-right context and the other on right-to-left context. The output of those were concatenated. It was different from other models at that time, but still had a major limitation: the network was still shallow. Take a look at the image below:
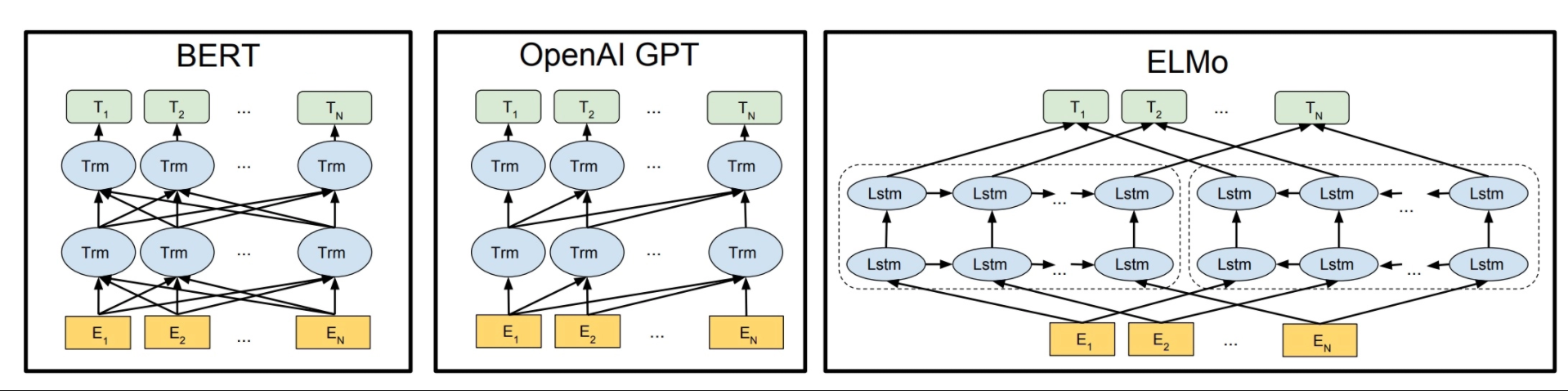
It is evident from the fact that BERT is the most densely and deeply connected network. The arrows show the information being passed from one layer to the another. The boxes at the top, the green boxes, shows the final representation of the of each input word.
Now you must wonder, bidirectionality has to do with masked language model? Let us take an input sentence: "I like reading Machine Learning articles on OpenGenus". Let's try to train a bidirectional language model on this sentence but instead of predicting what the next word would be, let's try to predict a missing word from the sentence sequence.
We replace the word "Learning" with "[MASK]". Writing "[MASK]" denotes a missing token. We then train the model to predict "Learning" as the missing token in the new sentence: "I like reading Machine [MASK] articles on OpenGenus".
That is what Masked Language Model is all about! BERT uses a set of rules created by its authors to further improve on the technique:
- 15% of the words are randomly masked. This is done to prevent the model from focussing on a particular token's position that is being masked.
- The researchers also do not use the word [MASK] as the masked word 100% of the time. Instead,
- in 80% of the time, masked token [MASK] was used to replace the words
- in 10% of the time, random words were used to replace the words
- in 10% of the time, nothing was done
3.2.2 Next Sentence Prediction
Apart from Masked Language Models, BERT is also trained on the task of Next Sentence Prediction. The task speaks for itself: Understand the relationship between sentences. We can understand the logic by a simple example.
Suppose there are two sentences: Sentence A and Sentence B. Now, given these two sentences, does sentence B comes after sentence A in the given corpus or is sentence B just a random sentence?
Keen machine learning enthusiasts would immediately recognize this task as a binary classification problem. Just split the sentences into sentence pairs. However, it is not so simple in the case of how BERT implements it. There are, once again, certain rules that the authors have implemented to improve upon the task of Next Sentence Prediction:
- 50% of the time, the sentence B would be a random sentence.
- The remaning 50% of the sentences would actually be the next sentence to sentence A.
- These would be labelled as 'NotNext' for the random sentence and 'IsNext' for the actual next sentence.
And this is how BERT is a truly monster of a model when it comes to NLP tasks. It performs the task of Masked Language Modelling and Next Sentence Prediction at the time of pre-training.
4. Conclusion
This wraps up the article at OpenGenus on BERT large model. I hope you like it. Do read my other articles on Algorithms and Machine Learning. Happy learning!