
Let's recall...
As discussed in depth in Part 1 of this series, born in 2017, ShuffleNet is a powerful CNN architecture for object detection in small devices that works on low computing as well as storage power. It is based on 3 famous architectures; GoogleNet, Xception and ResNet. The primary operation that does all the magic is the Channel Shuffle operation. ShuffleNet has been improved and released as ShuffleNet V2. It highlights 4 guidelines and also implements the same to give a better, faster and less memory and computationally inexpensive algorithm. ShuffleNet V2 with Sqeeze and Excitation modules forms ShuffleNet V2+. The later versions, ShuffleNet Large & Ex-Large are for devices with higher MFLOP's and hence are more dense.
Table of Contents
This article consists of the following sections that highlights the capabilities of the ShuffleNet Family's 3 members namely - ShuffleNet V1, V2 and V2*. ShuffleNet Large and Ex-Large are used for bigger devices which ShuffleNet doesn't specialize in.
- ShuffleNet V/S MobileNet
- ShuffleNet V/S other popular architectures
- SHuffleNet V/S ShuffleNet
- Additional Notes
ShuffleNet V/S MobileNet
MobileNet is a family of computer vision architectures which specialize in mobile and embedded devices focusing on light weight architecture. They work in the same MFLOP's range and with same constraints as ShuffleNet. Hence, comparing our ShuffleNet with MobileNet separately will give us an insight on ShuffleNet's capability. We will cover the performance of ShuffleNet siblings V1 and V2 with MobileNet.
Starting with ShuffleNet V1, the table 1 covers classification error on ImageNet dataset under different architectural complexities. The fourth column gives a difference between MobileNet score and ShuffleNet score grouped for each complexity range. In all the complexity variations, Though ShuffleNet was created for smaller devices (<150 MFLOPs) , it still performs better than MobileNet for higher computation costs (marked as BLUE in Table 1). For smaller devices (~ 40 MFLOPs) (marked as RED in Table 1), ShuffleNet performs significantly better than MobileNet by a factor of 7.8%. The ShuffleNet's performance is due to its efficient architecture and not depth, this can be proven by looking into shallower ShuffleNet versions ( 0.5X ) which still perform better than its MobileNet counterparts. Also, ShuffleNet shows its generalization capability due to its evaluation on COCO dataset.
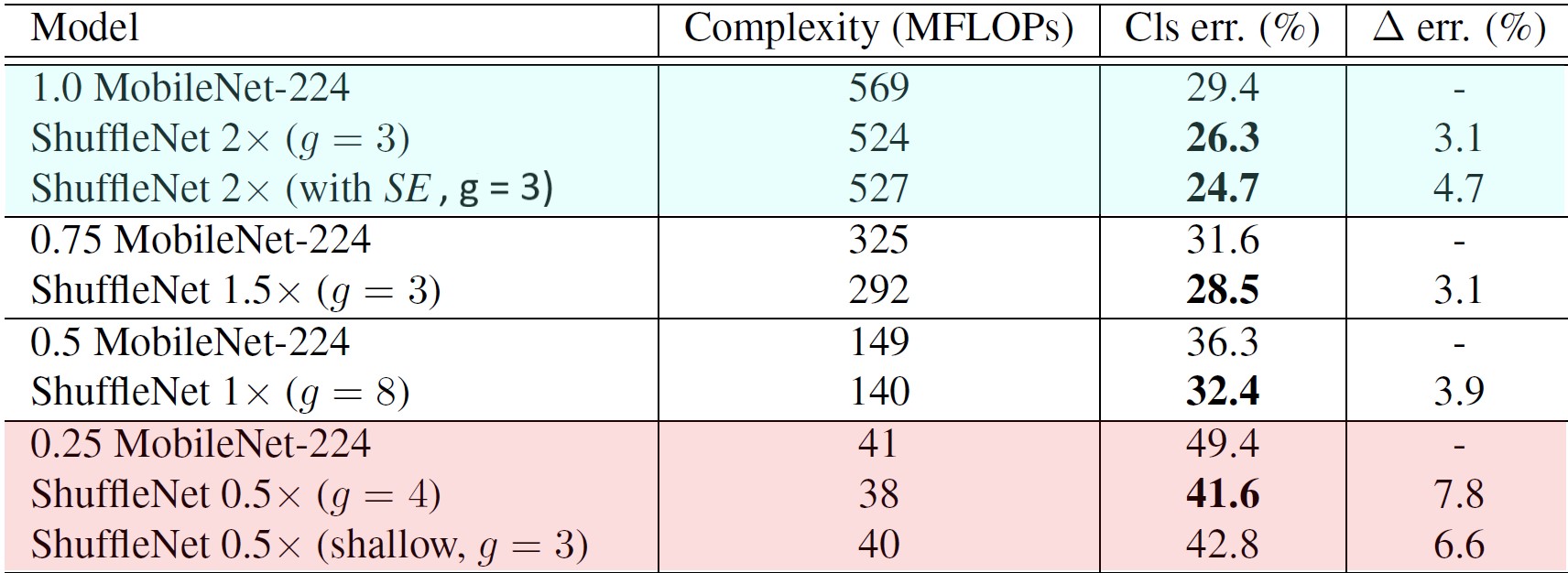
Image Courtesy: Official ShuffleNet paper
Additionally, actual inference time on mobile device with single Qualcomm Snapdragon 820 processor using a single thread is also observed. Observations (Table 2) show that ShuffleNet 0.5X is ~7 times faster as compared to MobileNet 1.0. More dense versions of ShuffleNet 1X also give inference faster than MobileNet.
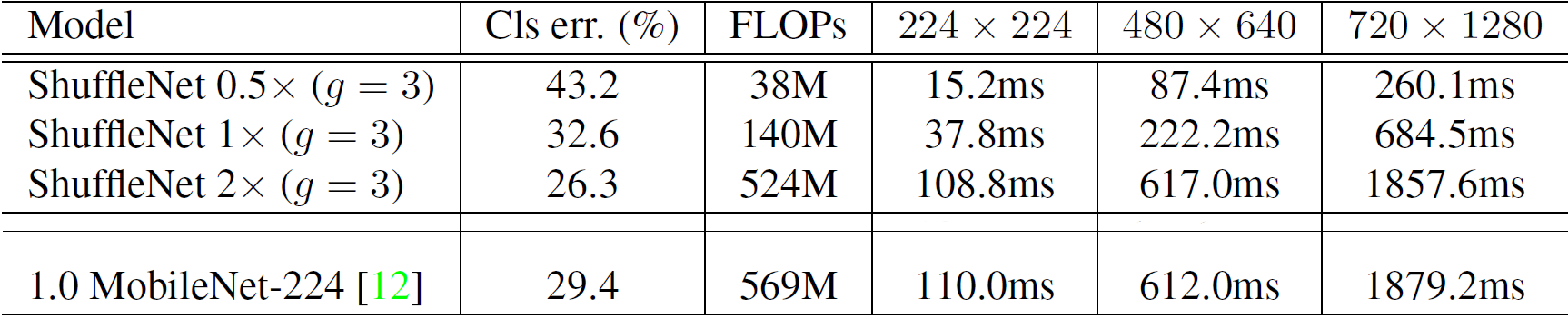
Image Courtesy: Official ShuffleNet paper
Coming to ShuffleNet V2, the experiments are done in different aspects - Accuracy vs. FLOPs and Inference Speed vs. FLOPs/Accuracy. It is worth noticing that MobileNet V2 performs poorly at 40 MFLOPs level. This is mostly caused by very few channels. In contrast, ShuffleNet V2 doesn't suffer from this drawback as the design allows using more channels. Coming to speed, ShuffleNet V2 is 58% faster than MobileNet V2. Although the accuracy of MobileNet V1 is average, its speed on GPU is faster than all the counterparts, including ShuffleNet V2.
Looking at Table 2, one can say that ShuffleNet is mostly better and sometimes performs at par with MobileNet for all complexities (shown with seperated lines).
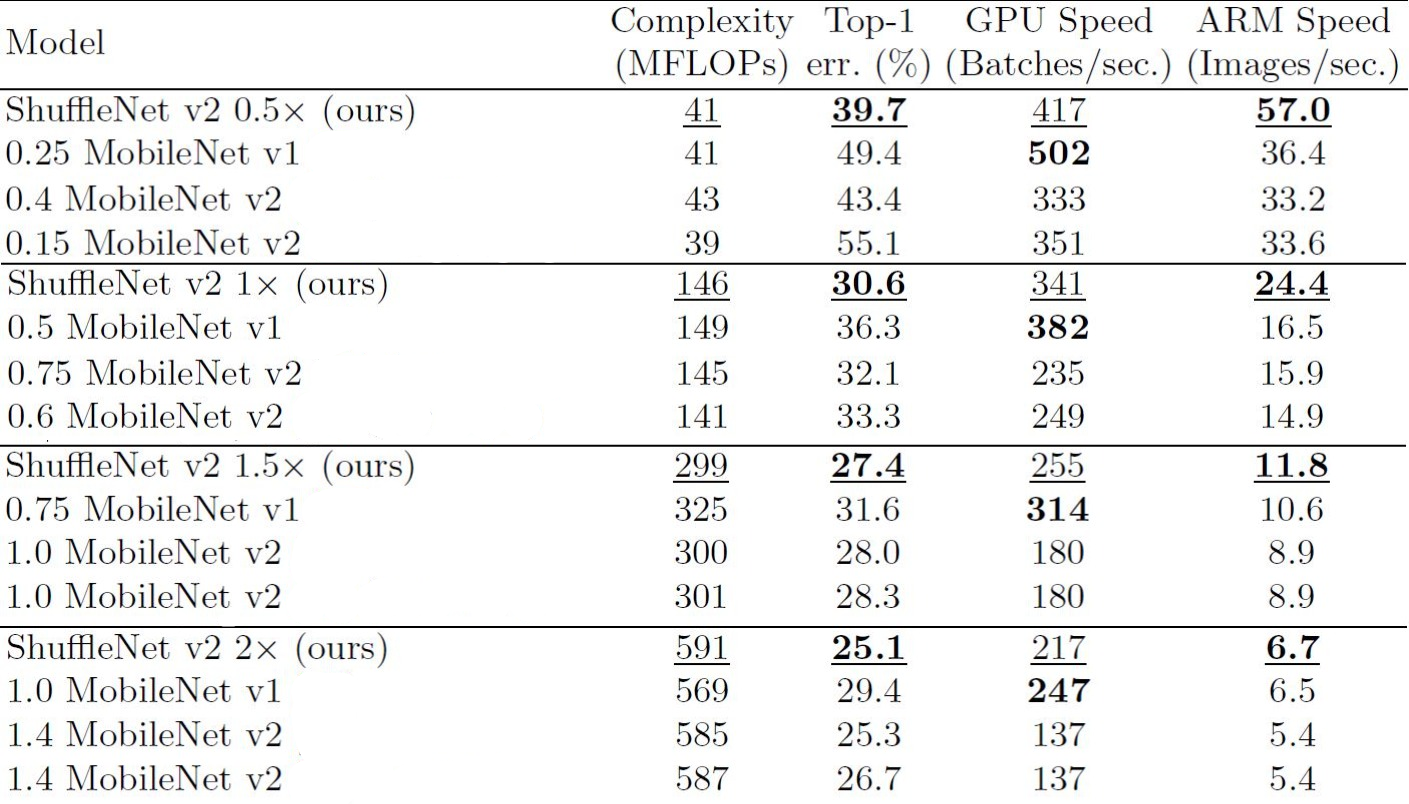
Image Courtesy: Official ShuffleNet V2 paper
To conclude, both V1 and V2 versions of ShuffleNet are better than MobileNet in terms of speed, accuracy and generalization property.
ShuffleNet V/S other popular architectures
We are going to look into performace of ShuffleNet by observing how well it classifies as compared to VGG-like, ResNet, Xception-like, AlexNet and ResNeXt. Next, ShuffleNet V2's capability can be seen by how it outsmarts Xception, DenseNet, ResNet, NASNet and CondenseNet.
Starting with ShuffleNet V1, a particular accuracy (shown by classification error in Table 4) can be achieved in as much as 30 times less dense structures as compared to all other architectures. Compared to its parent GoogleNet, ShuffleNet is 10X faster. Due to memory access and other overheads, we find every 4X theoretical complexity reduction usually results in ~2.6X actual speedup in ShuffleNet's implementation on ARM platforms.
Quoting ShuffleNet authors, empirically g = 3 usually has a proper trade-off between accuracy and actual inference time. This makes it the most used version of ShuffleNet.
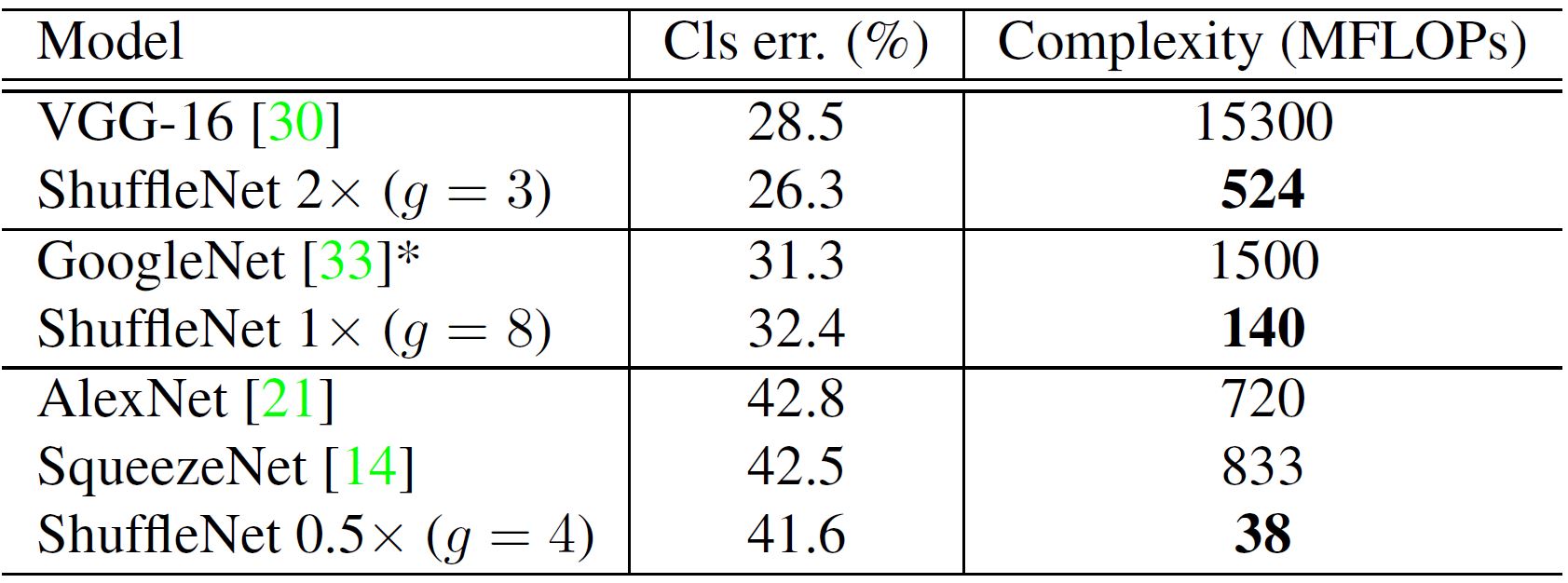
Image Courtesy: Official ShuffleNet V1 paper
For ShuffleNet V2, the following table presents a clear picture on its capabilities. For each complexity range, ShuffleNet V2 proves to give the best scores. This holds true for speed in both ARM as well as GPU based systems.
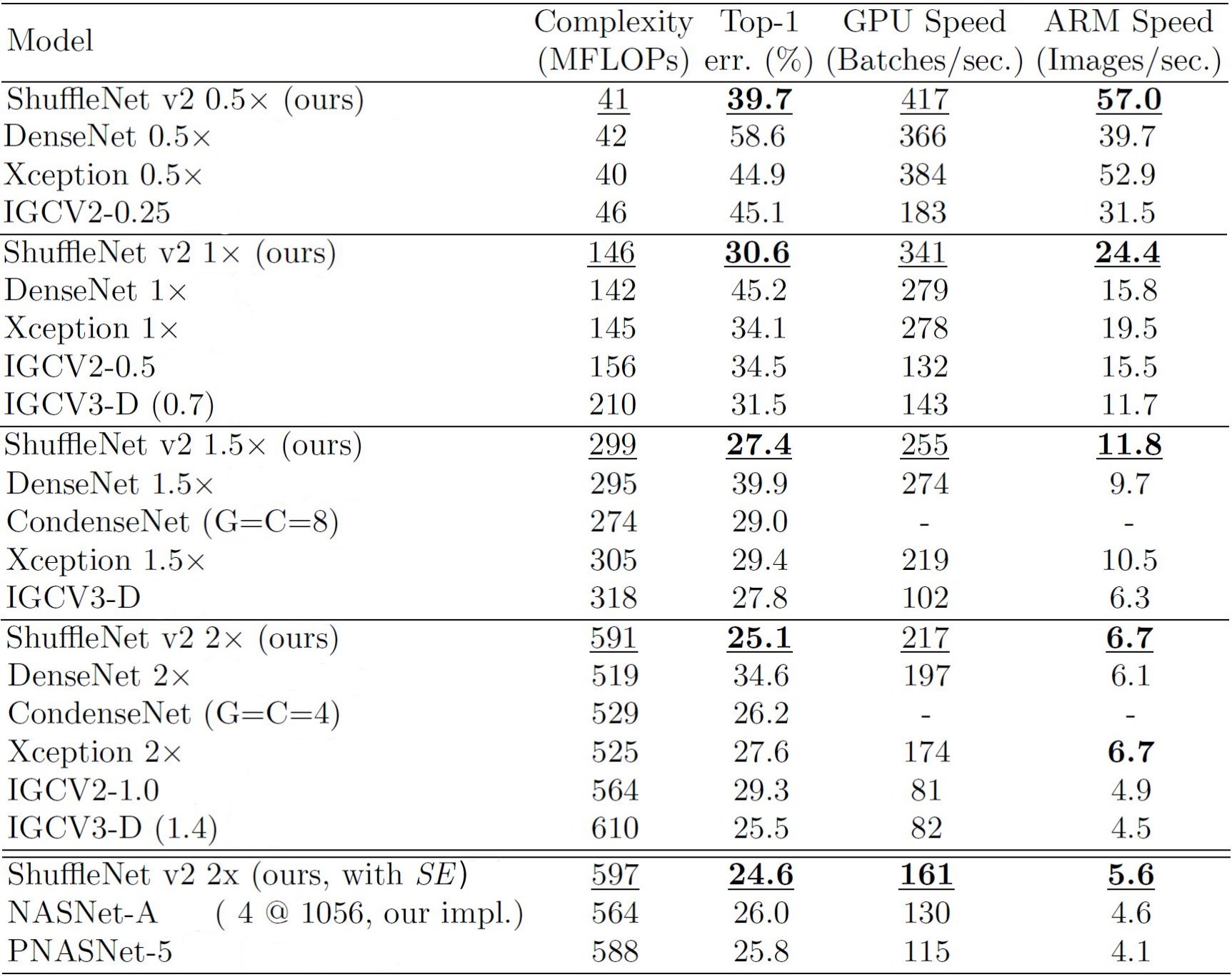
Image Courtesy: Official ShuffleNet V1 paper
Looking at the observations in both Table 3 and 5, one can conclude the following for classification task:
ShuffleNet V2 >= MobileNet V2 > ShuffleNet V1 > Xception
And for the object detection task:
ShuffleeNet V2 > Xception >= ShuffleNet v1 >= MobileNet v2
ShuffleNet V/S ShuffleNet

The newer versions of ShuffleNet are better than their older counterparts. The following results prove this stand. Here, we are going to cover how ShuffleNet V1, V2 and V2+ are better than their predecessors in ShuffleNet family.
We have chosen ShuffleNet V1 with group count = 3 as mentioned previously by the creators that it has a good balance between accuracy and speed . Table 6 proves that ShuffleNet V2 is better in terms of speed and classification errors for different complexities (here measured using MFLOPs). It is 63% faster than ShuffeNet v1 for GPU and comparable speeds in ARM based devices. Also, ShuffeNet v2 outperforms ShuffeNet v1 at 2.3GFLOPs.
To conclude, ShuffleNet V2 performs better than its predecessor, ShuffleNet V1 significantly in terms of speed and accuracy for both ARM as well as GPU based systems.
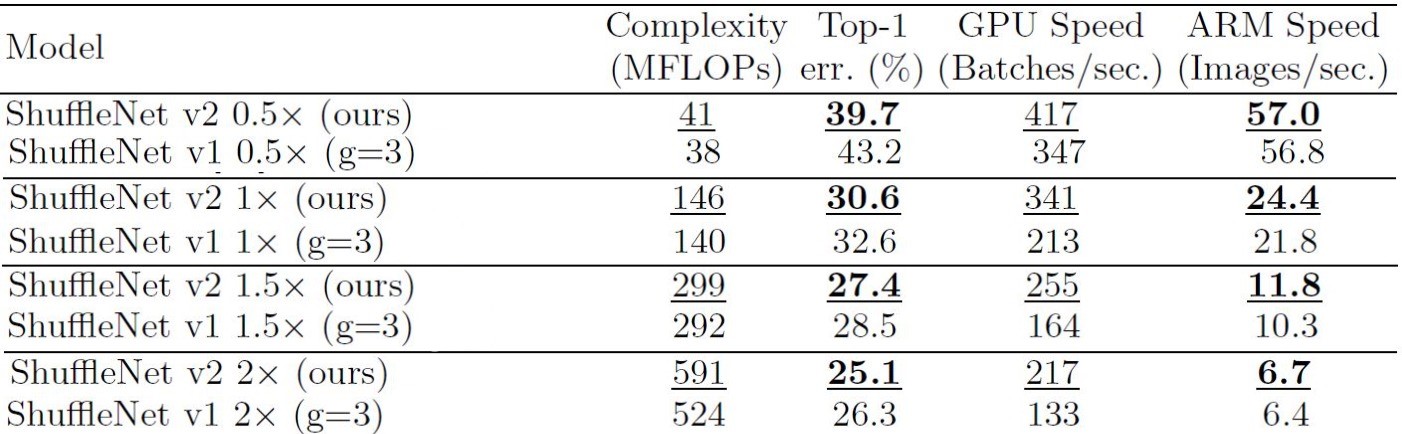
Image Courtesy: Official ShuffleNet V2 paper
When looked into V2+ variant of ShuffleNet, it includes Squeeze and Excitation module that is proved to work best for tiny edge devices. The additional section covers this deeply. ShuffleNet V2+'s accuracy is the best among ShuffleNet V1, ShuffleNet V2 and ShuffleNet V2+.
Additional Notes
Another version of ShuffleNet V2, termed as ShuffleNet V2* has been introduced. It has an enlarged receptive field from ShuffleNet V2 by introducing an
additional 3X3 depthwise convolution before the first pointwise convolution in
each building block. With only a few additional FLOPs, it further improves accuracy. The results of this new variant as compared to other architectures as well as ShuffleNet itself are logged in Table 7. This also shows the generalizability of ShuffleNet family as it tackles varied types of images with great efficiency.
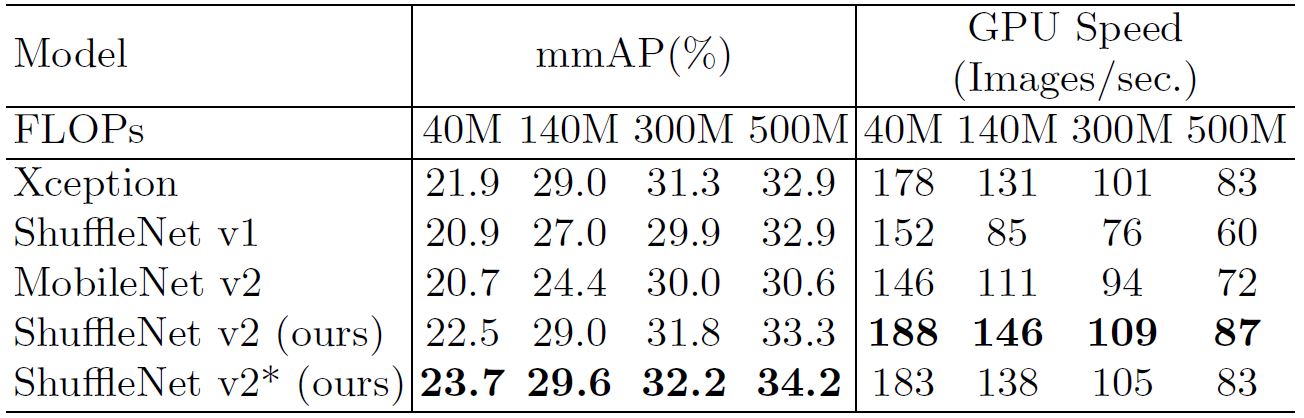
Image Courtesy: Official ShuffleNet V2 paper
Conclusion
In this article, we have covered the performance of ShuffleNet V1 and V2 in comparison to popular architectures including VGG-16, DenseNet, AlexNet, etc. We have also compared ShuffleNet with its predecessors in the same family. At last, we prove that ShuffleNet is one of the best architectures for small devices out of all the top and renowned architectures.
Coming up next...
The next and the last in the series is the implementation of ShuffleNet using Python.
References
- Pre-print of ShuffleNet research work by Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin & Jian Sun.
- Pre-print of ShuffleNet V2 : Practical Guidelines for Efficient CNN Architecture Design by Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng & Jian Sun1.
- Github Link of the whole ShuffleNet series.