
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we have explored the idea of Bigtable in System Design. It is an innovative database system developed by Google.
Table of contents:
- Introduction to Bigtable
- Goals
- Data Model
- Implementation / How to use Bigtable?
- Best uses of Bigtable
- Cloud Bigtable Pricing
Introduction to Bigtable
Bigtable is a revolutionary internal Google database system that helped to launch the NoSQL industry. Google had a problem in the mid-2000s. The web indexes behind its search engine had grown massive, and rebuilding them took a long time. The company desired to create a database capable of providing real-time access to petabytes of data. Bigtable was born as a result.
In 2006, Google published a research paper describing Bigtable, which inspired people outside of Google to create HBase, Cassandra, and other popular NoSQL databases. This paper received the SIGOPS Hall of Fame Award ten years later for being one of the most influential papers of the previous decade.
Bigtable was later used by Google to power many of its other core services, including Gmail and Google Maps. Finally, in 2015, Bigtable was made available as a service for its customers to use in their own applications.
Goals
Wide Applicability
It needs to support different requirements of different applications but not pertaining to one single application.
Scalability
The system should be able to handle storing more data by merely adding few commodity servers to the cluster
High Performance
Performance should be high even though processing large data sets
High Availability
Achieves almost zero downtime for the system
Data Model
A Bigtable cluster is a collection of processes that execute the Bigtable software. Each cluster caters to a specific set of tables. A table in Bigtable is sparse, distributed, persistent, multidimensional, and sorted map. The data is divided into four attributes: row, column-family, column key, and timestamps.
(row:string, column:string, time:int64) → string
A cell is the storage that is referenced by a specific row key, column key, and timestamp. Rows are grouped together to form the load balancing unit, while columns are grouped together to form the access control and resource accounting unit.
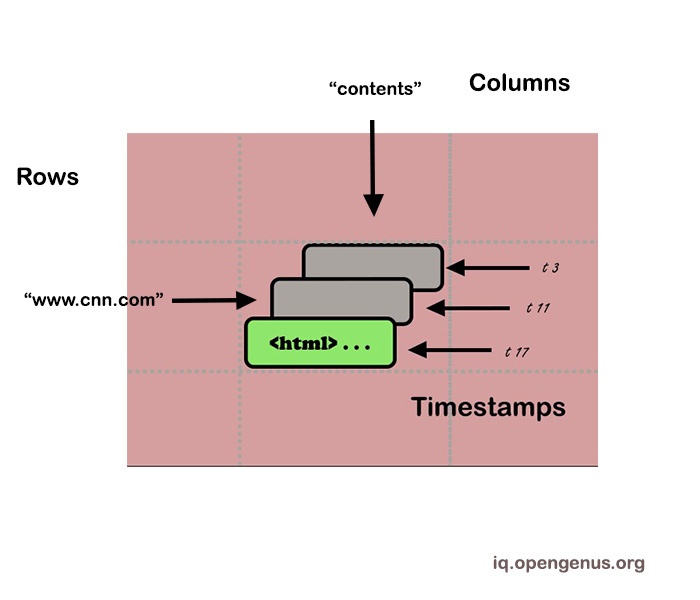
Rows. In Bigtable, which currently does not support transactions across rows, the row is the unit of transactional consistency. By row key, Bigtable keeps data in lexicographic order (currently up to 64KB in size).
Rows with consecutive keys are grouped together to form tablets, which serve as the distribution and load balancing unit. Clients can take advantage of this property by selecting row keys that provide good locality for their data accesses. Storing pages from the same domain close to each other improves the efficiency of some host and domain analyses.
Column. Column Keys are organized into Column Families. Typically, all data stored in a column family is of the same type. Column keys could be encoded using efficient compression techniques. A table should have a variety of distinct column keys. At the column family level, ACL, disk, and memory accounting are used.
TimeStamps. TimeStamps are integers with a size of 64 bits. BigTable stores timestamps as real time in microseconds by default. To avoid collisions, client applicants can generate their own timestamps. Data versions are stored in decreasing order, so that the most recent version is read first. Clients have the ability to limit the number of versions that can be stored in BigTable. The number of versions to be kept is controlled at the column-family level, with the rest being collected garbage.
Client API. Bigtable supports functions for creating and deleting tables and column families. The Bigtable API provides functions for changing cluster, table, and column family metadata, such as access control rights. Bigtable does not currently support general transactions across row keys, although it provides an interface for batching writes across rows at the clients.
Bigtable can be used with MapReduce a frame-work for running large-scale parallel computations developed at Google. Bigtable allows various forms of data transformation, filtering based on arbitrary expressions, and summarization. It also supports the execution of client-supplied scripts in the address spaces of the servers.
Building Blocks. Bigtable processes often share the same machines with processes from other applications. It uses a Google cluster management system for scheduling jobs, managing resources on shared machines and monitoring machine status.
GFS is used by Bigtable to store log and data files. GFS is a distributed file system that keeps multiple copies of each file for increased reliability and availability.
Chubby. Chubby, a highly available and persistent distributed lock service, is used by Bigtable. A Chubby service is made up of five active replicas, one of which is designated as the master and is responsible for actively serving requests. When the majority of the replicas are up and running and can communicate with one another, the service is considered live.
Chubby is used by Bigtable for a variety of purposes, including ensuring that only one active master is active at any given moment, storing the bootstrap location of Bigtable data, discovering tablet servers, and finalizing tablet server deaths, and storing Bigtable schemas. Bigtable becomes unavailable if Chubby is unavailable over an extended period of time.
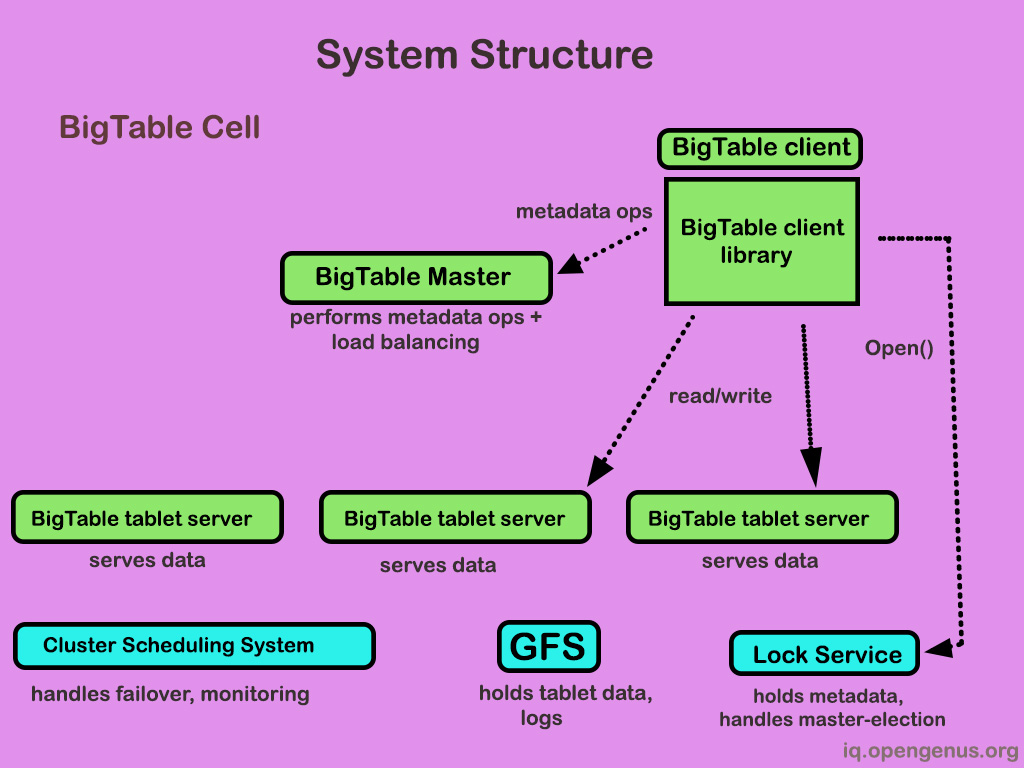
Implementation / How to use Bigtable?
A library that is linked into every client, one master server, and several tablet servers make up the Bigtable implementation. To accommodate variations in workloads, tablet servers can be dynamically added (or deleted) from a cluster.
Responsibilities of Master
- Assigning tablets to tablet servers
- Detecting the addition of new tablet server and expiration of existing tablet server
- Balancing tablet server load
- Garbage Collection of file is GFS
- Schema changes for Tables
Responsibilities of Tablet Servers
- Managing set of tablets (10 to 1000)
- Handling read and write requests to tablets that it has loaded
- Splitting Tablets that have gone too large (100-200MB Size per tablet)
- When it comes to the location of tablet servers, clients almost never interact with the master. To read and write from the BigTable, they communicate with tablet servers. In truth, Master is not substantially loaded.
Best uses of Bigtable
Google's Bigtable is a powerful tool for organizing big data, but it's not a good fit for every application. It's only a good solution for at least one terabyte of data, and its overhead is too high for many smaller amounts of data. Google doesn't build "normal" applications; it builds applications that typically have over a billion users.
If you store individual data components larger than 10 megabytes, Bigtable's performance will degrade. Cloud Storage may be a preferable alternative if you need to store unstructured assets that are larger than that, such as video files.
Bigtable is not a relational database and does not allow SQL or multi-row transactions, which is extremely crucial. As a result, it is unsuitable for a variety of applications, including online transaction processing.
It's also made to store key/value pairs. You should use a different database if you need to store data with more structure than that.
Given all of these constraints, Bigtable may appear to be unsuitable for a variety of circumstances. However, there are some instances where it is an excellent decision. The most prevalent application is as part of a MapReduce-based big data processing system. Bigtable is an excellent storage option if you're using Cloud Dataflow or Cloud Dataproc because it has a high throughput and scalability. It also supports the HBase API, making it simple to combine with Hadoop and Spark (both of which can run on Cloud Dataproc).
If you're doing interactive analytics - where you need to do queries on a data warehouse - then Bigtable is the right choice. It's also a good fit for use cases where you want to perform analytics on events as they happen, such as in financial services and Internet of Things applications.
Bigtable's major drawback is its lack of relational database capabilities, yet Bigtable scales so much better than standard relational databases that Google devised techniques to merge the two worlds. On top of Bigtable, it added software that supports:
- Data that is more complex than simple key/value pairs,
- Indexes that aren't primary indexes (instead of just one primary index) ,
- A SQL-like query language
- ACID features for dependable transactions (atomicity, consistency, isolation, and durability).
Cloud Datastore is the name of Google's new database service (although they actually released Datastore publicly before Bigtable).
The pricing structure is also different. You pay for monthly storage as well as reads and writes with Datastore. Of course, you must pay for monthly storage with Bigtable, but instead of paying for reads and writes, you must create a cluster and pay for it for as long as it is active. As a result, Datastore is less expensive for little amounts of data or rarely use, while Bigtable is less expensive for big amounts of data and frequent access.
Although Datastore has many of the features of relational databases, it lacks a few critical ones. As a result, Google developed yet another Bigtable-based service. It's called Cloud Spanner, and it was only made available to the general public in 2017. It has the following extra features:
- A relational schema,
- Strong consistency for all queries (rather than eventual consistency),
- SQL support, and
- Multi-region deployments.
As a result, Cloud Spanner provides the best of both worlds: massive scalability and high consistency. So why wouldn't you use Cloud Spanner instead of Bigtable or Datastore all the time? Because those extra capabilities come at a cost. Google's most expensive database service is Cloud Spanner. So, for example, if you only need to perform high-speed analytics, Bigtable would be less expensive and less complicated.
Google does provide another database service. Cloud SQL is a managed service for MySQL and PostgreSQL, so if you want to run a traditional relational database on Google Cloud Platform, this is the best way to do so.
Cloud Bigtable Pricing
Sample Computation: Single Cluster with one node
Assume you have a single cluster in your Bigtable instance. Your application server is in the same area as Bigtable, and the cluster has one node. During a 30-day billing period, you use the Bigtable resources listed below:
1 instance in us-central1 (Iowa) with a single cluster that has 1 node throughout the month
Average of 50 GB of data stored on SSD drives in us-central1
No network ingress
No network egress
Your Bigtable bill for the billing cycle is broken down as follows, assuming you are billed in USD. Any other Google Cloud services utilized during the billing cycle, such as Compute Engine instances, will incur additional charges.
Bigtable nodes
1 cluster * 1 node * 30 days * 24 hours/day * $0.65 per node per hour in us-central1: $468.00
Storage
1 cluster * 50 GB * $0.17 per GB in us-central1: $8.50
Network
No network ingress
No network egress
Monthly total
In this example, the total monthly bill for Bigtable is $476.50.
With this article at OpenGenus, you must have the complete idea of Bigtable in System Design.