
Attention Mechanism has been a powerful tool for improving the performance of Deep Learning and NLP models by allowing them to extract the most relevant and important information from data, giving them the ability to simulate cognitive abilities of humans. This article at OpenGenus aims to explore and walk you through the main types of Attention Mechanism models and the main approaches to Attention.
Table Of Contents:
- Introduction.
- Scaled-Dot Product Attention Mechanism.
- Multi-Head Attention Mechanism.
- Approaches to Attention.
Introduction
Before we explore the different types of Attention Mechanism, we will briefly go through what the term actually means. Attention Mechanism enables enhances the performance of models by introducing the ability to mimic cognitive attention the way humans do in order to make relevant predictions by understanding the context of given data. Attention can be defined as 'Memory per unit of time'.
It is used in Deep Learning models to selectively focus on certain parts of the input and assign weights to them based on their relevance to the current task, such that the model can assign more resource and 'attention' to the most important parts of the input while ignoring the less relevant parts. In Natural Language Processing (NLP), attention mechanisms have been particularly successful in improving the performance of machine translation, text summarization, and sentiment analysis models.
Scaled-Dot Product Attention Mechanism
Scaled dot product is a specific formulation of multiplicative attention mechanism that calculates attention weights using dot-product of query and key vectors followed by proper scaling to prevent the dot-product from growing too large. Here's the model for Scaled-Dot Product Attention:
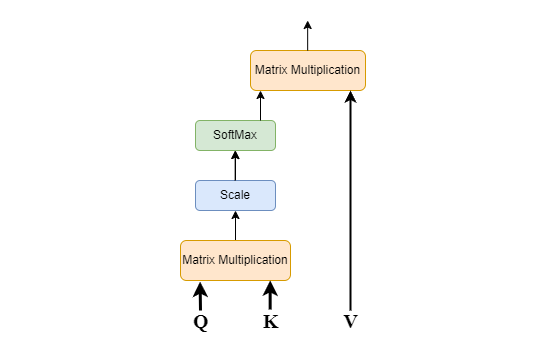
The steps involved are as follows:
- Input Sequence (Query, Key and Value)- The input sequence is transformed into three vectors: query, key, and value. These vectors are learned during training and represent different aspects of the input sequence.
- First Matrix Multiplication- Computes the similarity between the Query Matrix and the Key Matrix by performing a dot product operation. The resulting score represents the relevance of each element in the input sequence to the current state of the model.
- Scaling Of Matrix- To prevent the scores from being to large and to avoid the Vanishing Gradient problem, scaling of the matrix is done to stabilize the gradients during training.
- SoftMax Function- The scaled scores are passed through a softmax function to normalize them to ensure that the attention weights sum up to 1. It is used to convert a set of numbers into a probability distribution and enables the model to learn which parts of the input are most relevant to the current task.
- Second Matrix Multiplication- The output from the SoftMax function is then multiplied with the Value Matrix which is the final output of the Attention Layer.
Multi-Head Attention Mechanism
Instead of performing and obtaining a single Attention on large matrices Q, K and V, it is found to be more effecient to divide them into multiple matrices of smaller dimensions and perform Scaled-Dot Product on each of those smaller matrices.
Here's the model for Multi-Head Attention, propsed in the paper 'Attention is all you need.':
- Obtain Query, Key and Value matrices- Obtain the value 'h', which is the number of heads. Usually, a value of 8 is considered. Then we obtain the same number of set of Q, K and V matrices. A triple set from 1 to h will be obtained for Q, K and V.
- Scaled-Dot Product Attention- We perform scaled-dot product attention for each triple set Qi, Ki and Vi to Qh, Kh and Vh.
- Concatenation and Linear Transformation- The resulting attention distributions are concatenated using the ConCat function and passed through a learnable linear transformation to obtain a final representation.
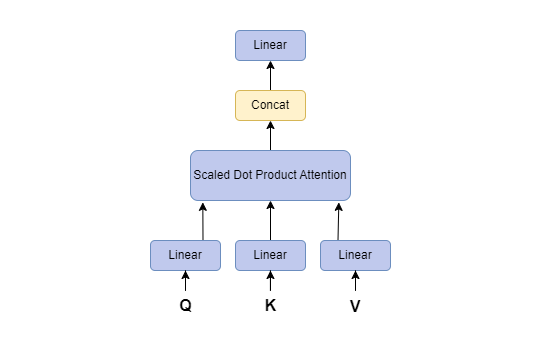
MultiHead attention uses multiple attention heads to attend to different parts of the input sequence which allows the model to learn different relationships between the different parts of the input sequence. For example, the model can learn to attend to the local context of a word, as well as the global context of the entire input sequence.
However, Scaled-Dot product attention uses a single attention head to attend to the entire input sequence which is a simpler mechanism when compared to MultiHead attention and it can be less effective for tasks that require the model to learn complex relationships between the different parts of the input sequence.
Ultimately, the choice of which attention mechanism to use depends on the specific task and the resources available.
Additive-Attention Mechanism
This type of mechanism is used in neural networks to learn long-range dependencies between different parts of a sequence. It works by computing a weighted sum of the hidden states of the encoder, where the weights are determined by how relevant each hidden state is to the current decoding step. First, the encoder reads the input sequence and produces a sequence of hidden states which represent the encoder's understanding of the input sequence.
The decoder then begins to generate the output sequence, one word at a time. The decoder takes the previous word, the current hidden state, and the attention weights as input. The attention weights are used to compute a weighted sum of the encoder's hidden states and this weighted sum is then used to update the decoder's hidden state. The decoder then generates the next word, and the process is repeated until the decoder generates the end-of-sequence token.
Dynamic-Convolution Attention
Dynamic convolution attention was first introduced in the paper "Dynamic Convolution Attention over Convolution Kernels" by Chen et al. (2019). It increases model complexity without increasing the depth or width of a network. Instead of using a single kernel per layer, dynamic convolution clusters multiple parallel convolution kernels in a dynamic method based upon their attentions, which are dependent on the input. Aggregation of multiple kernels is not only computationally efficient due to the small kernel size, but it also has representation power as these kernels are aggregated in a non-linear fashion via attention. It can be integrated easily into existing network architectures.
Entity-Aware Attention
Entity-aware attention was first introduced in the paper "Entity-Aware Attention for Relation Extraction" by Sun et al. (2019). In this paper, the authors showed that entity-aware attention could be used to improve the performance of relation extraction models. It is an attention mechanism that focuses on specific entities or entities' interactions within a sequence or a context.
In traditional attention mechanisms, attention weights are typically computed based on the similarity between the query and key vectors derived from the input sequence. However, in entity-aware attention, the attention mechanism takes into account the entities mentioned in the input sequence and their respective roles using Named Entity Recognition (NER) or Entity Linking.
Location-Based Attention
Location-based attention, also known as Positional Attention, was first introduced in the paper "Spatial Attention in Natural Language Processing" by Xu et al. (2015). It takes into account the relative position or location of elements within a sequence or context using Learned Position Embeddings or Sinusoidal Encoding. It is commonly used in models that process sequential data, such as natural language processing (NLP) tasks, where the position of words or tokens can carry important information.
This can be particularly useful in tasks where the order or position of elements matters, such as machine translation or text generation, as it helps the model capture sequential dependencies and generate more accurate and coherent outputs.
Self Attention
It is a mechanism that allows a model to attend to different parts of the same input sequence. This is done by computing a weighted sum of the input sequence, where the weights are determined by how relevant each part of the sequence is to the current task.
The basic idea behind self-attention is to compute attention weights for each word/token in a sequence with respect to all other words/tokens in the same sequence. These attention weights indicate the importance or relevance of each word/token to the others.
Global Attention
While Scaled-Dot Product and Multi-Head Attention are methods to compute attention, there are mainly two approaches to how the Attention itself is applied, i.e. Global Attention and Local Attention. Global attention attends to all of the input sequence, while local attention only attends to a subset of the input sequence.
Global attention can capture long-range dependencies between different parts of the input sequence and contextual information in the input sequence, as it allows the model to attend to all input elements at each decoding step. It can be computationally expensive as it has to attend to the entire sequence. It is typically used for tasks that require the model to consider the entire input sequence, such as text summarization.
Local Attention
Local attention can be more effective for tasks that require the model to focus on a specific part of the input sequence. Local attention is easier to train as it only has to learn to attend to a subset of the input sequence. It is typically used for tasks that require the model to focus on a specific part of the input sequence, such as machine translation.