
Introduction to DistilBERT
DistilBERT is a smaller, faster, and lighter version of the popular BERT (Bidirectional Encoder Representations from Transformers) model developed by Hugging Face. It was introduced in 2019 and since then has been a popular choice for natural language processing tasks. The main aim of DistilBERT is to achieve similar performance as BERT with fewer parameters and faster training times, making it more suitable for resource-constrained environments such as mobile devices and edge devices. The model has been trained on the same dataset as BERT, the BooksCorpus (800M words) and English Wikipedia (2,500M words), making it pre-trained on a large amount of general-purpose knowledge and capable of transfer learning to many NLP tasks. DistilBERT has 66% fewer parameters compared to its base model, BERT-base. It has a total of 66 million parameters, compared to BERT-base's 110 million parameters. DistilBERT has 6 layers, compared to BERT-base's 12 layers, making it more computationally efficient while still maintaining a high level of accuracy. The model also uses a distilled version of the attention mechanism found in BERT, which helps it to better focus on the most important information in the input data
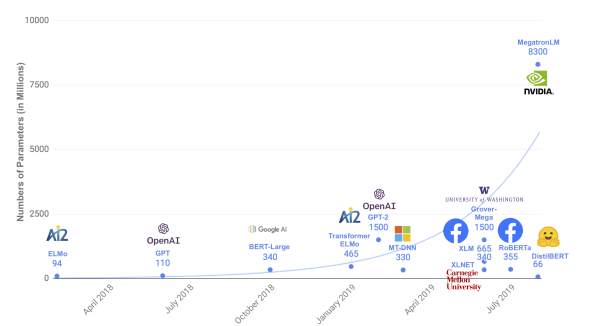
Parameter counts of several recently released pretrained language models
Table of contents:
- Background of DistilBERT
- How does DistilBERT works?
- DistilBERT Architecture
- Differences between DistilBERT and BERT
- Advantages of using DistilBERT
- Applications of DistilBERT
- References
Background of DistilBERT
DistilBERT is a distilled version of the popular BERT (Bidirectional Encoder Representations from Transformers) model that was developed by Hugging Face. BERT was introduced in 2018 and is considered one of the most powerful pre-trained models for natural language processing tasks. However, its large size and resource-intensive training process have made it challenging to deploy in resource-constrained environments such as mobile devices and edge devices.
To address these challenges, the team at Hugging Face introduced DistilBERT, a smaller, faster, and lighter version of the BERT model. The goal of DistilBERT is to provide a smaller and more efficient model that can achieve similar performance as the original BERT model while still retaining its ability to transfer learning to other NLP tasks. DistilBERT has been trained on the same dataset as BERT, the BooksCorpus (800M words) and English Wikipedia (2,500M words), making it pre-trained on a large amount of general-purpose knowledge.
Since its introduction in 2019, DistilBERT has been widely adopted as a pre-trained model for NLP tasks and has shown promising results in several benchmarks and real-world applications.
How does DistilBERT works?
DistilBERT works by using a knowledge distillation process, where the outputs from a large, pre-trained BERT model are used to train a smaller, faster, and more compact model. In the distillation process, the large pre-trained model acts as a teacher model and the smaller, distilled model acts as a student model. The student model is trained to mimic the outputs of the teacher model, thereby transferring the knowledge learned by the teacher model to the student model.
DistilBERT uses a transformer-based architecture to encode the input sequence, where each token in the sequence is mapped to a dense representation (also called an embedding) which captures the contextual meaning of the token. These embeddings are then used to make predictions for the task at hand, such as sentiment analysis, question answering, or named entity recognition.
The key difference between DistilBERT and BERT lies in the number of layers, hidden units, and attention heads. DistilBERT has fewer layers, hidden units, and attention heads compared to BERT, making it faster and more efficient, but with slightly lower performance.
DistilBERT Architecture
The architecture of DistilBERT is similar to that of the original BERT model.
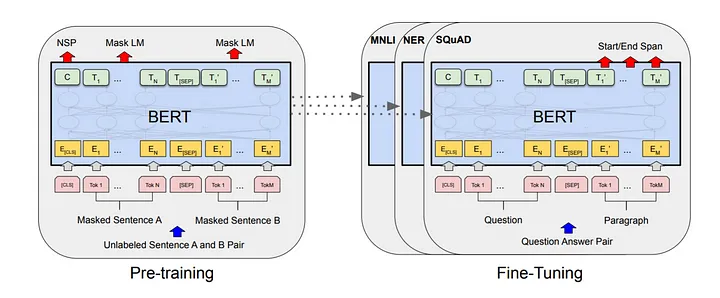
DistilBERT is a transformer-based deep learning architecture composed of several key components:
-
Attention Mechanism: DistilBERT uses self-attention mechanism, where each word in the input sequence can attend to all other words in the sequence to better understand context and relationships between words.
-
Encoder Layers: DistilBERT has 6 encoder layers, each consisting of a self-attention layer and a feed-forward layer, to learn rich and deep representations of the input sequence.
-
Token Embeddings: The input tokens are first embedded into vectors, which capture their semantic meaning and relationships with other tokens. DistilBERT uses pre-trained token embeddings to initialize this process.
-
Segment Embeddings: DistilBERT also uses segment embeddings to distinguish between two different sequences of tokens (e.g. two sentences) in a single input.
-
Position Embeddings: To incorporate the position of the tokens in the sequence, DistilBERT uses position embeddings, which are added to the token and segment embeddings.
-
Layer Normalization: DistilBERT uses layer normalization to normalize the activations between the self-attention layer and feed-forward layer, which helps improve stability and speed up training.
-
Output Layer: The final output layer generates the prediction based on the learned representations of the input sequence.
Differences between DistilBERT and BERT
| Feature | DistilBERT | BERT |
|---|---|---|
| Model Size | Smaller | Larger |
| Number of Layers | 6 | 12/24 |
| Number of Layers | 6 | 12/24 |
| Number of Parameters | 66M | 340M/1.3B |
| Training Time | Faster | Slower |
| Performance | Similar to BERT | Better than DistilBERT |
| Use Case | Resource-constrained environments | High-performance NLP tasks |
Advantages of using DistilBERT
DistilBERT has several advantages compared to its parent model BERT:
-
Smaller size: DistilBERT has fewer parameters compared to BERT, making it faster and easier to deploy on resource-constrained environments like mobile devices and edge devices.
-
Faster training times: DistilBERT can be trained much faster than BERT, making it a more practical choice for real-world NLP tasks.
-
Better performance on transfer learning: DistilBERT's pre-training on the BooksCorpus and English Wikipedia dataset makes it a better choice for transfer learning to other NLP tasks compared to BERT.
-
Improved interpretability: DistilBERT's smaller size and simplified architecture make it easier to interpret and understand, compared to the more complex BERT model.
-
Lower computational costs: DistilBERT's smaller size and faster training times result in lower computational costs compared to BERT, making it a more cost-effective option for NLP tasks.
Applications of DistilBERT
DistilBERT has many applications across NLP. Some of them are as follows:
-
Text classification: DistilBERT has been used in several text classification tasks such as sentiment analysis, topic classification, and spam filtering. The model's ability to understand the context of words and sentences helps it to perform well on these tasks.
-
Named entity recognition (NER): DistilBERT has been used in NER tasks to identify and classify entities such as people, locations, organizations, and dates in a text.
-
Question Answering (QA): DistilBERT has been used in QA systems to provide answers to questions by extracting information from a text corpus.
-
Text Generation: DistilBERT has been used in text generation tasks to generate new text based on the input given to it.
-
Machine Translation: DistilBERT has been used in machine translation systems to translate text from one language to another.
-
Summarization: DistilBERT has been used in summarization systems to summarize long documents into shorter versions while retaining important information.
-
Dialogue Systems: DistilBERT has been used in dialogue systems to respond to questions in a conversational manner.
These are some of the most common applications of DistilBERT. The model's performance and efficiency make it a popular choice for NLP tasks, especially in resource-constrained environments.
References
- Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
- “DistilBERT.” Huggingface, huggingface.co/docs/transformers/model_doc/distilbert.
- Sanh, Victor, et al. "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter." arXiv preprint arXiv:1910.01108 (2019).
- “Distilbert-base-cased · Hugging Face.” Huggingface, 3 Nov. 2022, huggingface.co/distilbert-base-cased.