
Reading time: 30 minutes
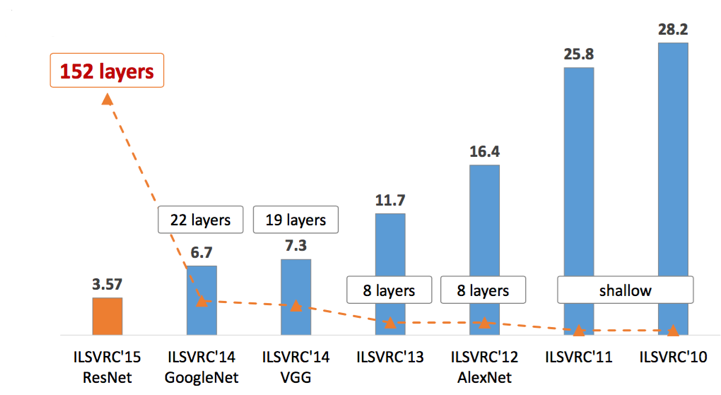
It all started with LeNet in 1998 and eventually, after nearly 15 years, lead to ground breaking models winning the ImageNet Large Scale Visual Recognition Challenge which includes AlexNet in 2012 to GoogleNet in 2014 to ResNet in 2015 to ensemble of previous models in 2016. In the last 2 years, no significant progress has been made and the new models are an ensemble of previous ground breaking models.
A Convolutional Neural Network (CNN, or ConvNet) are a special kind of multi-layer neural networks, designed to recognize visual patterns directly from pixel images with minimal preprocessing. The ImageNet project is a large visual database designed for use in visual object recognition software research. The ImageNet project runs an annual software contest, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), where software programs compete to correctly classify and detect objects and scenes.
LeNet in 1998
LeNet is a 7-level convolutional network by LeCun in 1998 that classifies digits and used by several banks to recognise hand-written numbers on cheques digitized in 32x32 pixel greyscale inputimages. The ability to process higher resolution images requires larger and more convolutional layers, so this technique is constrained by the availability of computing resources.
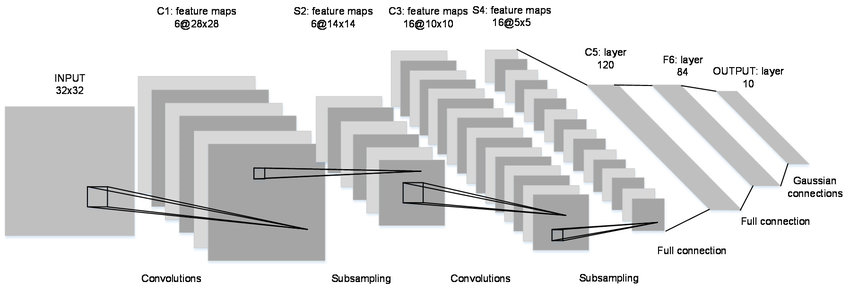
Over the next several years, we worked to improve our computational power so that we can do a large number of calculations in reasonable time and overcome the limitations faced by LeNet.
The quest has been successful and this led to a research into deep learning and gave rise to ground breaking models.
AlexNet in 2012
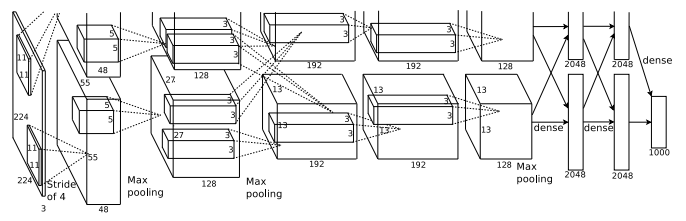
AlexNet is considered to be the first paper/ model which rose the interest in CNNs when it won the ImageNet challenge in 2012. AlexNet is a deep CNN trained on ImageNet and outperformed all the entries that year. It was a major improvement with the next best entry getting only 26.2% top 5 test error rate. Compared to modern architectures, a relatively simple layout was used in this paper.
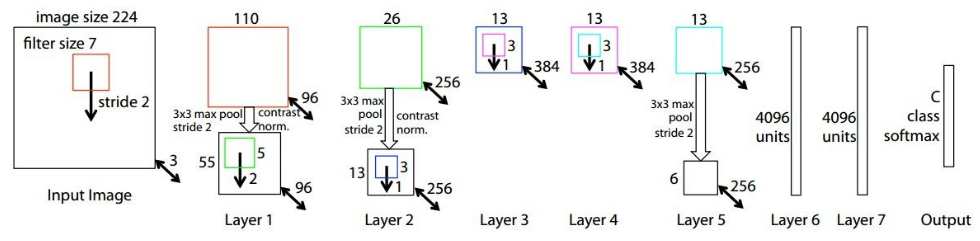
ZFNet in 2013
ZFNet is a modified version of AlexNet which gives a better accuracy.
One major difference in the approaches was that ZF Net used 7x7 sized filters whereas AlexNet used 11x11 filters. The intuition behind this is that by using bigger filters we were losing a lot of pixel information, which we can retain by having smaller filter sizes in the earlier conv layers. The number of filters increase as we go deeper. This network also used ReLUs for their activation and trained using batch stochastic gradient descent.
VGG in 2014
The idea of VGG was submitted in 2013 and it became a runner up in the ImageNet contest in 2014. It is widely used as a simple architecture compared to AlexNet and ZFNet.
VGG Net used 3x3 filters compared to 11x11 filters in AlexNet and 7x7 in ZFNet. The authors give the intuition behind this that having two consecutive 2 consecutive 3x3 filters gives an effective receptive field of 5x5, and 3 – 3x3 filters give a receptive field of 7x7 filters, but using this we can use a far less number of hyper-parameters to be trained in the network.

GoogleNet in 2014
In 2014, several great models were developed like VGG but the winner of the ImageNet contest was GoogleNet.
GoogLeNet proposed a module called the inception modules which includes skip connections in the network forming a mini module and this module is repeated throughout the network.
GoogLeNet uses 9 inception module and it eliminates all fully connected layers using average pooling to go from 7x7x1024 to 1x1x1024. This saves a lot of parameters.
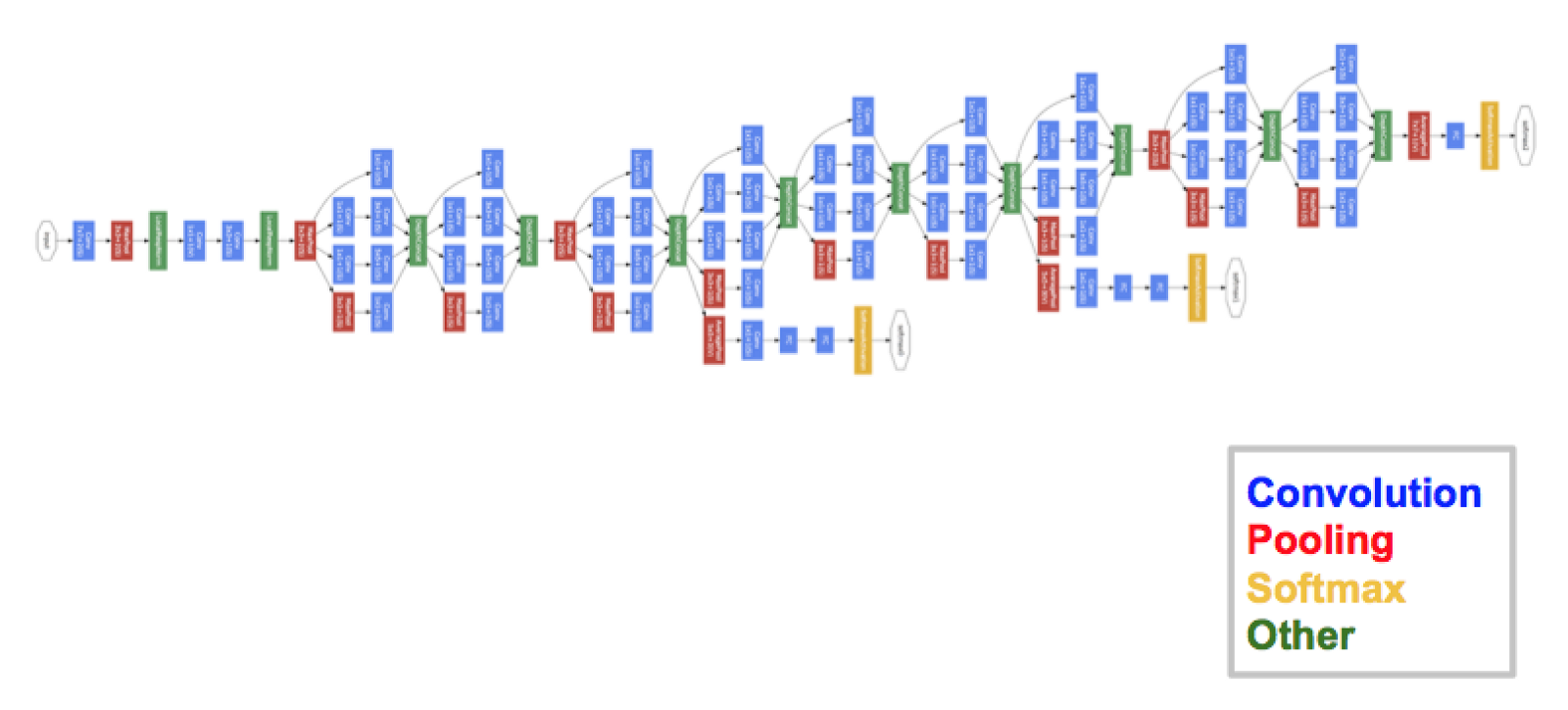
ResNet in 2015
There are 152 layers in the Microsoft ResNet. The authors showed empirically that if you keep on adding layers the error rate should keep on decreasing in contrast to “plain nets” where adding a few layers resulted in higher training and test errors. It took two to three weeks to train it on an 8 GPU machine. One intuitive reason why residual blocks improve classification is the direct step from one layer to the next and intuitively using all these skip steps form a gradient highway where the gradients computed can directly affect the weights in the first layer making updates have more effect.
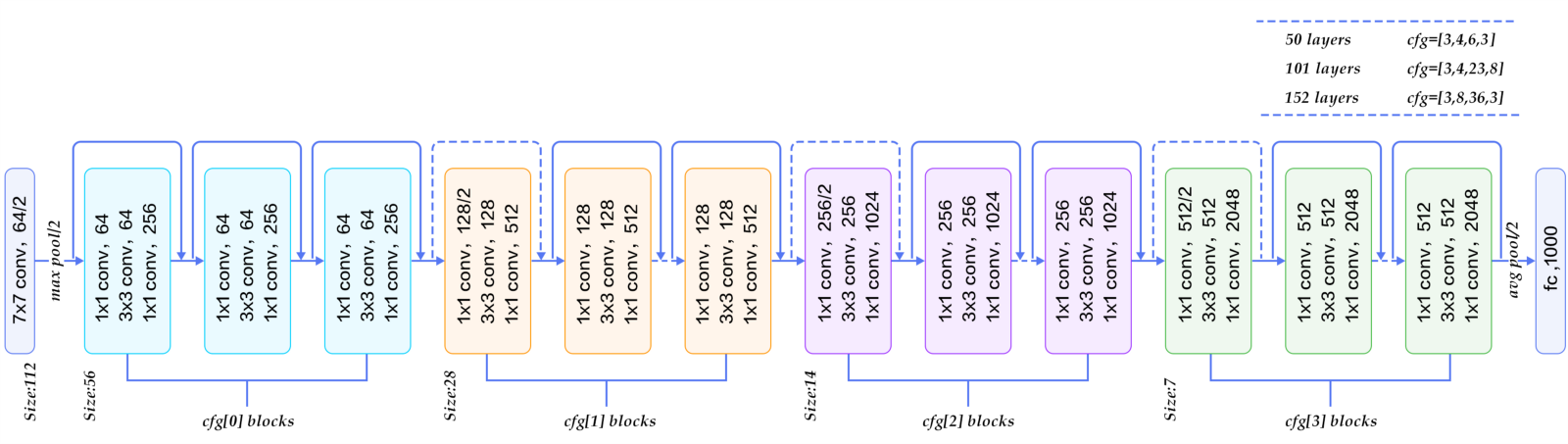
Comparison
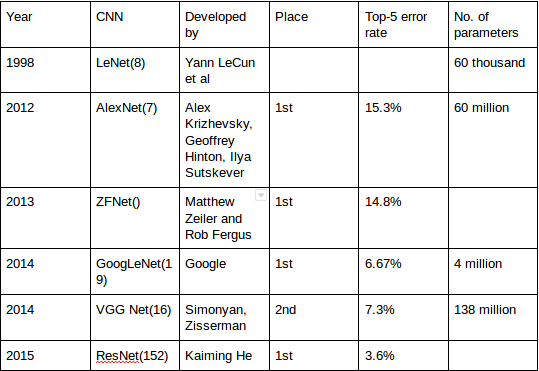
Beyond 2015
Most of the new models are improvements over previous ground-breaking models and some are ensemble of the previous models. These new models do perform better than the previous models but no significant or path changing idea has been formed over the last couple of years.
The future holds several exciting improvements and we are just at the beginning.