
Natural Language Tasks include various tasks such as semantic similarity assessment, textual entailment, document classification and question answering. Previously to train any models on these tasks, special data set curated for such tasks were required. But, the problem was to acquire such dataset was very difficult and even if we have such a dataset, we can't have large corpus. The other problem was that such models failed miserabely on other NLP tasks as they were especially trained on specific tasks.
Generative Pre-Training (GPT) models are trained on unlabeled dataset (which are available in abundance). So the models were trained on the unlabeled data set and then fine tuning the model on specific annotated dataset. These models perform way better than the previous state of the art models. For example, a model can be trained on Wikipedia dataset and then that model can be fine-tuned on sentiment analysis dataset.
GPT-1
Open AI came up with the first iteration of Generative Pre-Training-1 (GPT-1). It was trained on books Corpus data set which has 7000 un-published books. GPT model was based on Transformer architecture. It was made of decoders stacked on top of each other (12 decoders). These models were same as BERT as they were also based on Transformer architecture. The difference in architecture with BERT is that it used stacked encoder layers. GPT model works on a principle called autoregressive which is similar to one used in RNN. It is a technique where the previous output becomes current input.
The semi-supervised learning which include first performing unsupervised pre-training and then supervised fine-tuning.
a. Unsupervised Pre-training: For unsupervised learning, normal (standard) language model objective was used.
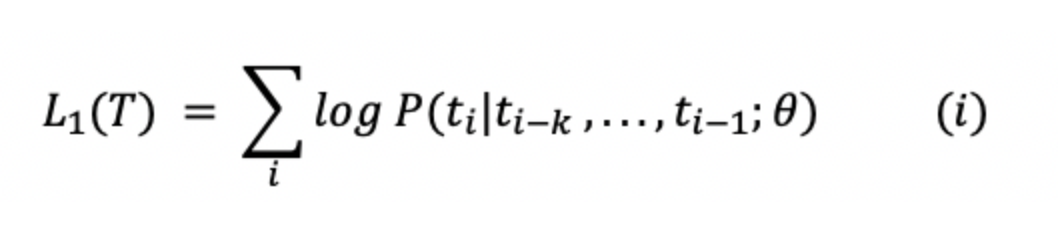 .
.
In the equation above, T is tokens in the data, k is contex window size and theta is parameters of the model.
b. Supervised Fine-Tuning: This equation maximizes the likelihood of label y (given features or tokens i.e., x1, x2,...,xn).
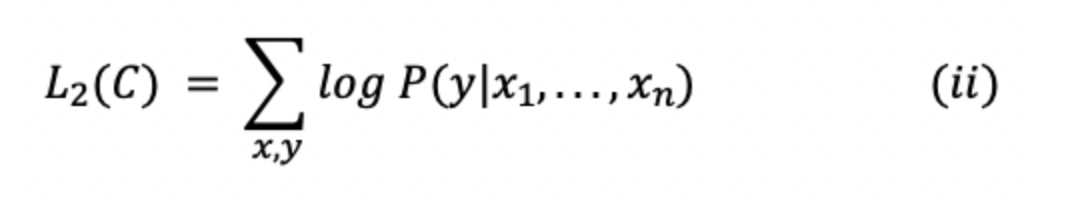
In the equation above, C is the labeled dataset made of training examples.
After combining equation 1 and 2, we'll get combined training objective;
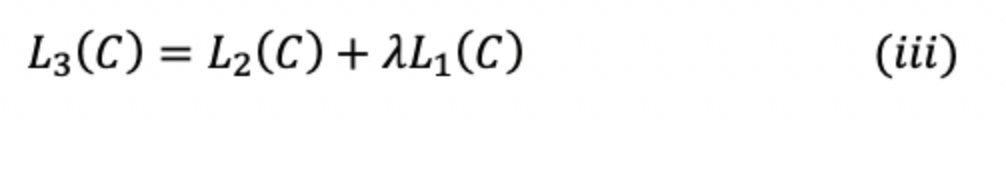
where lambda is the weight.
c. Task Specific Transformations at the input: In order to make minimal changes to the GPT model during the phase of fine tuning, inputs to the certain tasks were converted to ordered sequences.
- Tokens such as start and end were added to the input sequence.
- A token called delimiter was added between parts of the input so that it can be taken as an ordered sequence.
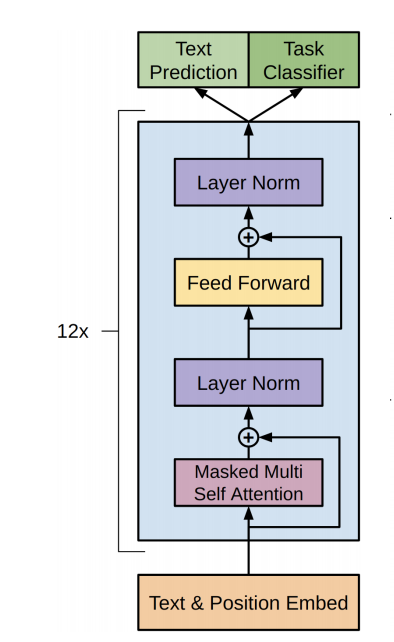
The architecture of the GPT is shown above. It shows that it uses 12 layers of decoder with 12 attention heads in each self-attention layer. It contains masked self attention which is used for training the model. The architecture was very similar to the original transformer architecture. Masking helps where the model doesn't have access to the words to the right side of the current word.
GPT-2
Open-AI came up with the second generation of Generative Pre-Training model, gpt2. Architecture is based on same philosophy as that of GPT-1 (stacked decoder layers), but was made larger by using a very large data set and adding more parameters to the model. The model was trained on very large data set which was scrapped from reddit and which they called the WebText data set. It was around 40 GB of text data with 8 million documents. The model had way more parameters than the previous edition of gpt, around 10 more than gpt-1 (1.5 billion). In this edition of GPT model, layers of the decoders stacked on each other, 48 to be precise. GPT-2 showed that between a model trained on a larger data set and with more parameters can increase the accuracy of the model.
Some very important concepts were discussed in this iteration.
Task Conditioning: Training objective of any language model is given as P(output|input). But, GPT-2 was trainied is such a way that ut can learn multiple tasks using the same model. In this, the learning objective was changed to P(output|input, task). This is known as task conditioning. In this type fo conditioning, model gives different output for the same input we change the task.
Zero Shot Learning and Zero Short Task Transfer: An interesting capability of GPT 2 is zero shot task transfer. Zero shot learning is a special case of zero shot task transfer in which no examples are provided to the model and the it understands the task based on the given instruction. like in GPT-1 where we rearranged the input for fine tuning task, input to GPT-2 was given in such a format which forces the model to understand the nature of task by itself and provide the relevant output. This was done to emulate zero-shot task transfer behaviour. For example, to convert an english sentence to french sentence, the model was provided with an English sentence followed by the french term and then some symbol like ':'. It forces the model to understnad that it is a translation task and give the output in french.
The authors of GPT-2 trained four different models. First was with 117 million parameters (same as GPT-1), second was with 345 million parameters, third was with 762 million parameters and fourth one was with a whooping 1.5 billion parameters (GPT-2). Each subsequent model performed better than the previous one and had lower perplexity than previous one.
GPT-3
In 2020, Open-AI came up with another edition of GPT model, GPT 3, which has over around 175 billion parameters, which was around 10 times more than Microsoft NLG model and around 100 times more than the previous GPT-2. It was trained on 5 different Corpus each having different weight assigned. They were webtext, books-1, books-2, Common Crawl, WebText2, Wikipedia. Applications of GPT-3 include generating text, writing podcasts, writing legal documents. This doesn't here as it can write website or ML codes too!
This iteration of GPT brought a very powerful model which won't need fine tuning.
In-context learning: Models with very large parameters and trained oon hge dataset start learning hidden patterns in the data. While their learning objective is still same, predict the next word given some input words, the models recognizes hidden meaning and patterns in the data which not only hepls in minimise the loss but this ability also helps the model during zero-shot task transfer. When the model is given few examples, the language model matches the pattern of the examples with what it had learnt in past for the dataset we provided and it uses that learned knowledge during training to perform the task. This capability of the large language model increases with increase in the number of parameters of the model.
Few-shot, one-shot and zero-shot setting: As discussed previously, few, one and zero-shot settings are specialized cases of zero-shot task transfer. In few-shot setting, our language model is provided with the task description and as many examples as it fit into the context window of the language model. In the case of one-shot setting the language model, it is provided with just one example. Similarly, in zero-shot setting, the language model is provided with no example whatsoever.
The architecure of GPT-3 was same as GPT-2, so we can say that it is a bloated version of GPT-2.
Conclusion
Open-AI's GPT models have come in long way. These models with their powerful architecture has revolutionized the field of NLP achieving state-of-the-art accuracies on various NLP tasks. Though these models are not at par with humans in natural language understanding, they have certainly shown a way forward to achieve that objective.