
Panoptic is a word with Greek origins, derived from two words (pan - all) + (opsesthai - seeing), when put together it means all-seeing. Panoptic Segmentation is an improved human-like image processing approach that combines the goals of both Instance and Semantic Segmentation. It was first proposed in a 2018 paper by Alexander Kirillov.
Table of contents
- Introduction
- Applicable Datasets
- Models and Approaches
- Model Comparisons
- Applications
Introduction
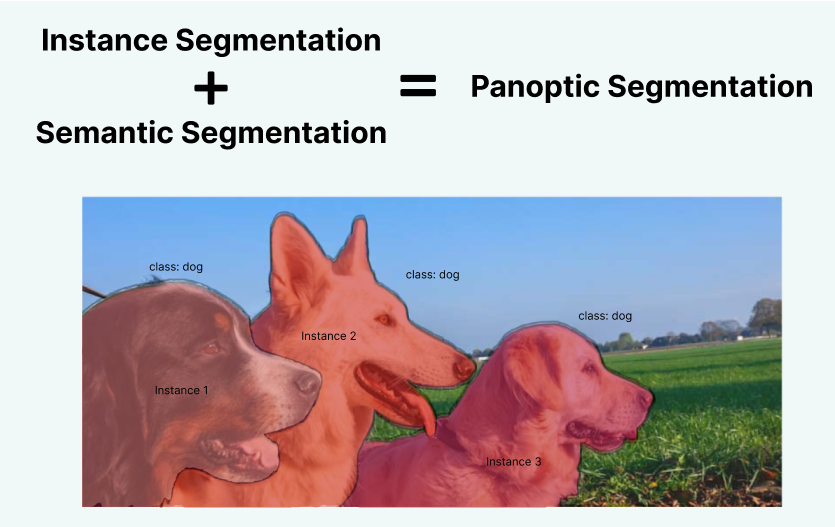
Semantic Segmentation aims to assign a class label to each pixel and the aim of Instance segmentation is to distinctly detect each instance of a class. By nature we humans subconsciously perform a combination of both of the tasks with ease, it follows that we try to replicate the same in machines, Panoptic Segmentation is the term given to this attempt. To illustrate consider the following image,

The differences are visually highlighted in the following figures,

In Essence,
There are two possible approaches to Panoptic Segmentation,
-
Multi-Label Classification Models - The use of a single end-to-end multi-label classification model due to the theorization of Panoptic segmentation, poses an efficient solution as they are meta-models capable of predicting multiple labels.
-
Modified Labels - The simplest method to assign labels appropriate to Panoptic Segmentation would be to combine the individual labels of Instance and Semantic Segmentation with the help of data structures, this results in a new label that provides additional information concerning computing methods than the traditional Segmentation methods.
Applicable Datasets
The abundance of open-source datasets obligates us to narrow down high-quality datasets to appropriately apply panoptic segmentation. Most available reliable image panoptic segmentation datasets can be classified into two types,
- 2D datasets - The learning is based on length and width. Some excellent 2D datasets include,
- Cityscapes Panoptic Semantic Labeling Task
- COCO 2020 Panoptic Segmentation Task
- Pastis: Panoptic Agricultural Satellite Time Series
- 3D datasets - Additional to length and width, the learning is also based on depth. These kinds of datasets are created with the help of advanced depth-sensing lasers or cameras. Some of them include,
- SemanticKITTI Panoptic Segmentation
- ScanNet v2
Additional Information on the respective datasets can be found in the references given at the end.
Apart from using open-source datasets, one can also create their panoptic segmentation dataset by following the below-mentioned steps,
-
Select a Theme - It is good practice to create a dataset with a practical application in mind, this way the dataset created will be consistent with a goal. It is also essential to incorporate images that add variation to the dataset, this allows the learning to improve based on incorrect/non-existent labels.
-
Labeling - labeling is a crucial step as the resolution boundaries defined for the different labels in the image will resonate throughout the model affecting the resolution of the predictions generated by the trained model, in turn the performance of the model. The use of image labeling tools is extremely helpful to reduce the time and effort required to create a dataset. Some commonly used image labeling tools include,
-
labelme
-
labelImg
-
CVAT
Models and Approaches
Going through preexisting work is the priority as it provides perspective and inspiration and serves as a headstart to the exploration. A good place to start would be,
Mask R-CNN
R-CNN is shorthand for Regions with Convolutional Neural Networks, essentially it is an object detection model that leverages high-capacity CNNs to provide region suggestions from the bottom up, allowing it to locate and segment items.
Using R-CNN as a foundation Mask R-CNN a comprehensive, adaptable, and theoretically straightforward framework for object instance segmentation was proposed in 2017. It uses an additional branch for the generation of an overlaying boundary in parallel with the existing branch for bounding box recognition of Fast R-CNN. As an added benefit, Faster R-CNN is run at 5 frames per second while Mask R-CNN adds only a little overhead.
The efficiency and flexibility of Mask R-CNN are exploited to create exceptional Panoptic Segmentation models that focus on enhancing different aspects of Panoptic Segmentation.
UPSNet
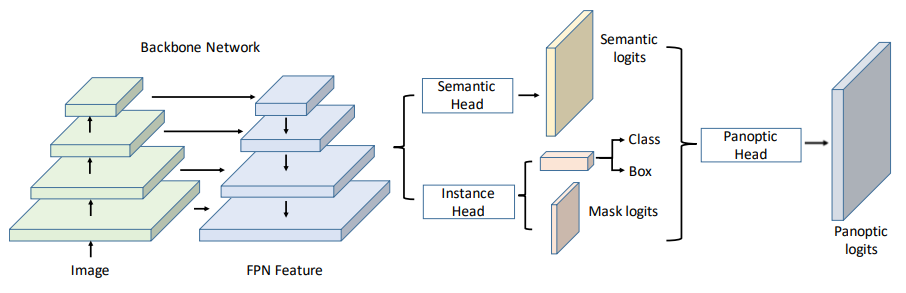
Forerunners in the series of recognizable models are the Unified Panoptic Segmentation Network in 2019. It accomplished to design a deformable convolution-based semantic segmentation head and a Mask R-CNN style instance segmentation and a parameter-free panoptic head which solves the panoptic segmentation via pixel-wise classification.
It initially makes use of the logits from the previous two heads before creatively expanding the representation to allow the prediction of an additional unknown class, which aids in more effectively resolving the conflicts between semantic and instance segmentation.
EfficientPS
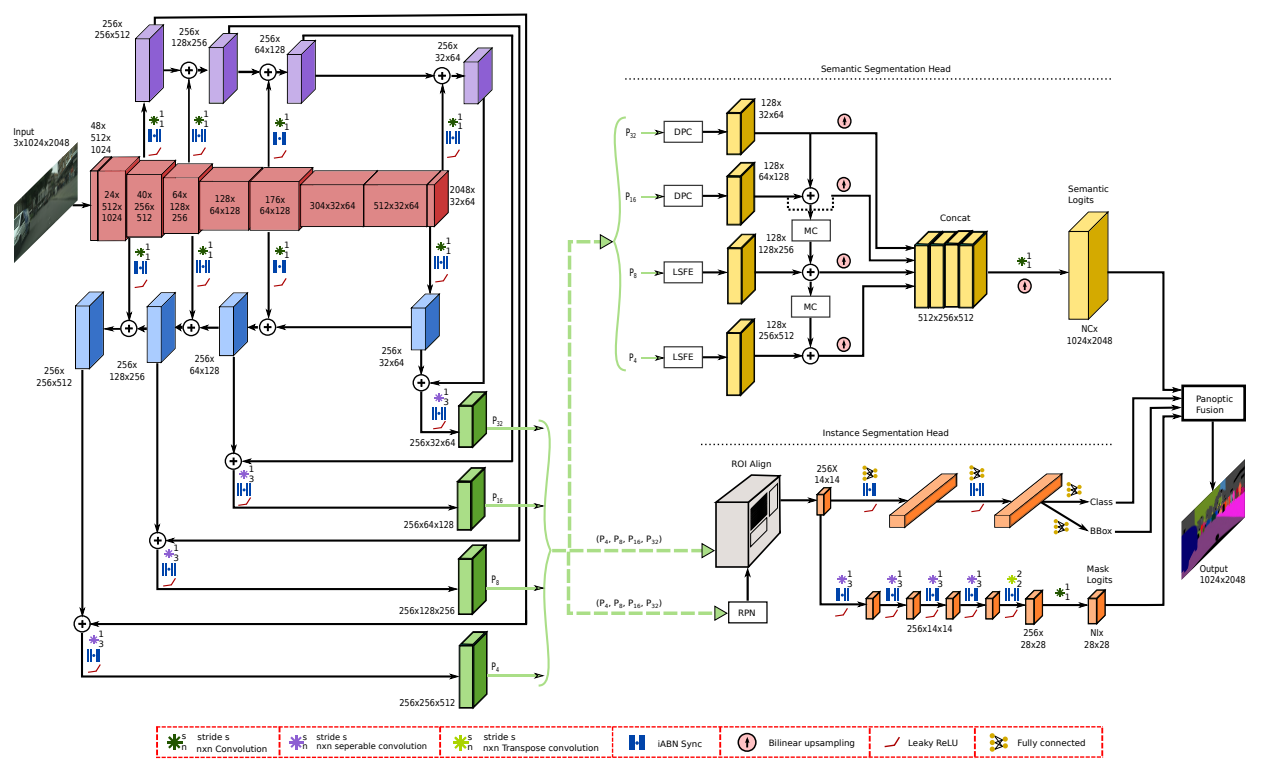
Put forth in 2020 a unique variant of Mask RCNN augmented with depthwise separable convolutions as the instance head. An encoder and its suggested 2-way FPN form the network's backbone (Feature Pyramid Network).
It achieved a new semantic head that captures fine and contextual features efficiently and a novel adaptive panoptic fusion module.
LPSNet
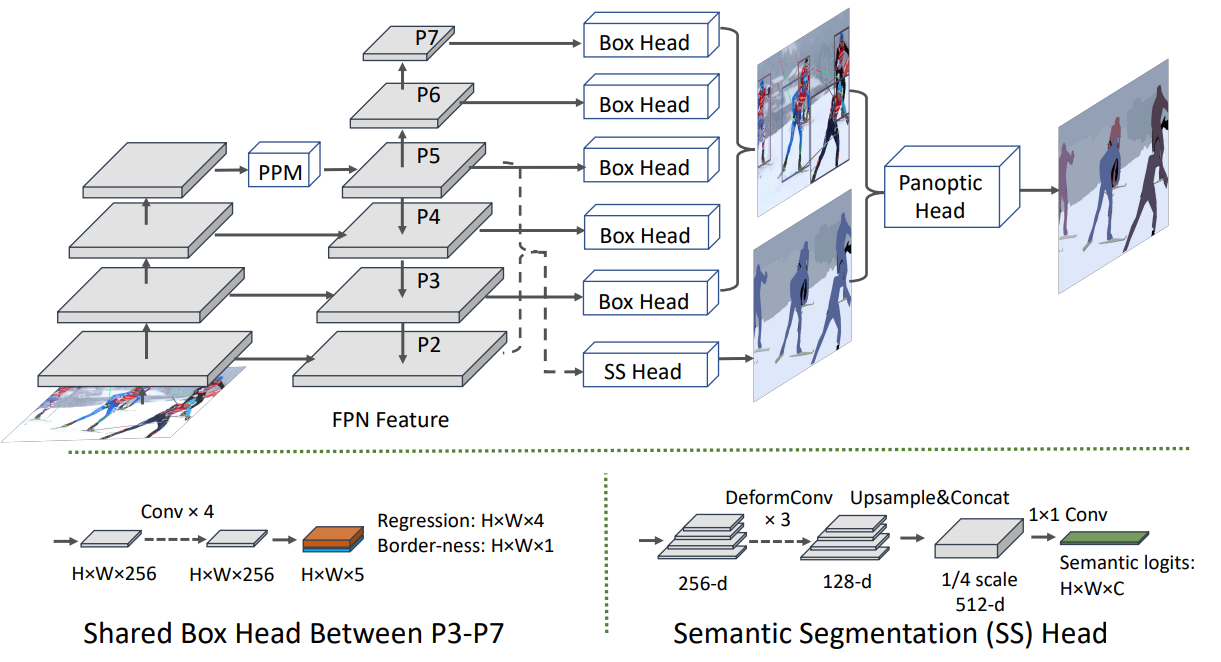
A relatively recently proposed model from 2021 is the Lightweight solution for fast Panoptic Segmentation. The majority of currently used techniques use a fully convolutional network to forecast semantic segmentation and a two-stage detection network to achieve instance segmentation results.
To simplify the pipeline and decrease computation/memory cost the one-stage approach is employed by predicting a bounding box and semantic category at each pixel upon the feature map produced by an augmented feature pyramid. Further, it is followed by the design of a parameter-free head to merge the per-pixel bounding box and semantic prediction into panoptic segmentation output.
Model Comparisons
To establish valid comparisons it is we are required to agree upon a standard metric to do so.
Evaluation metrics
The original metric proposed in the Panoptic Segmentation paper by Kirillov is,
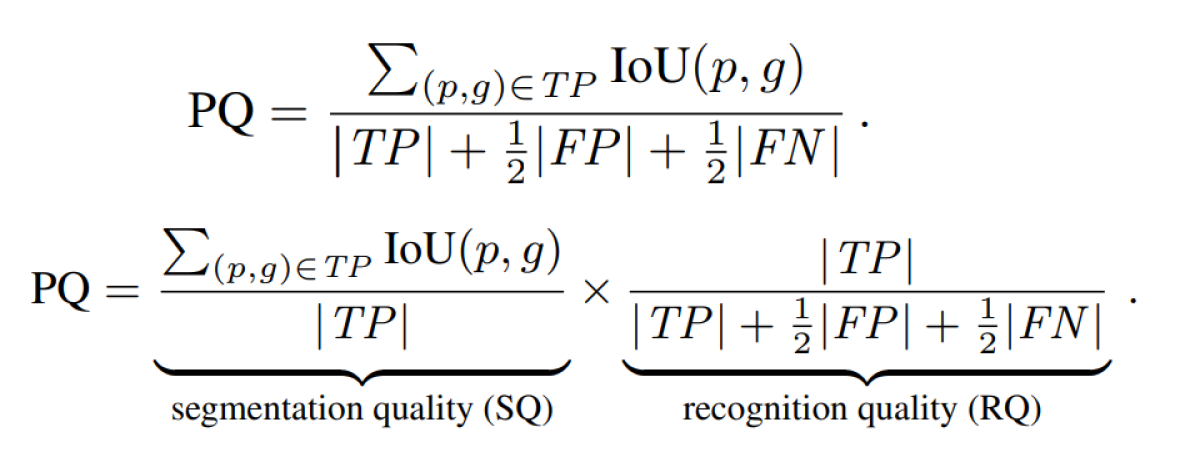
The PQ metric is the abbreviation for Panoptic Quality metric.
Here,
TP is true positives
FP are false positives
and FN is false negatives
A more recently proposed metric is the PC metric in DeeperLab paper which accounts for instance sizes,
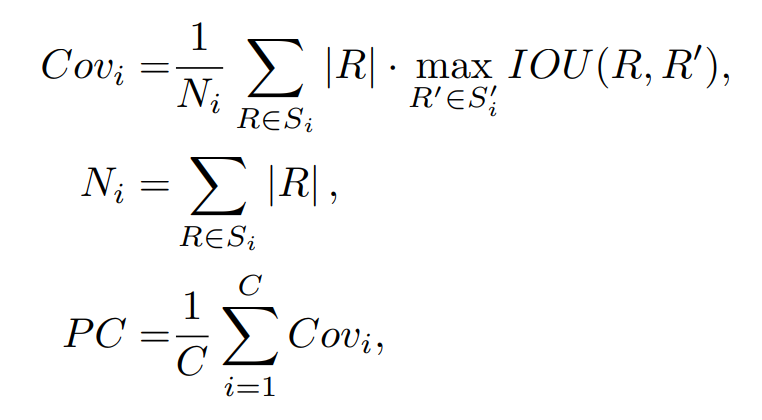
The PC metric is the abbreviation for Parsing Covering metric.
where Si and Si' are the ground-truth segmentation and predicted segmentation for the i-th semantic class respectively, and Ni is the total number of pixels of ground-truth regions from Si.
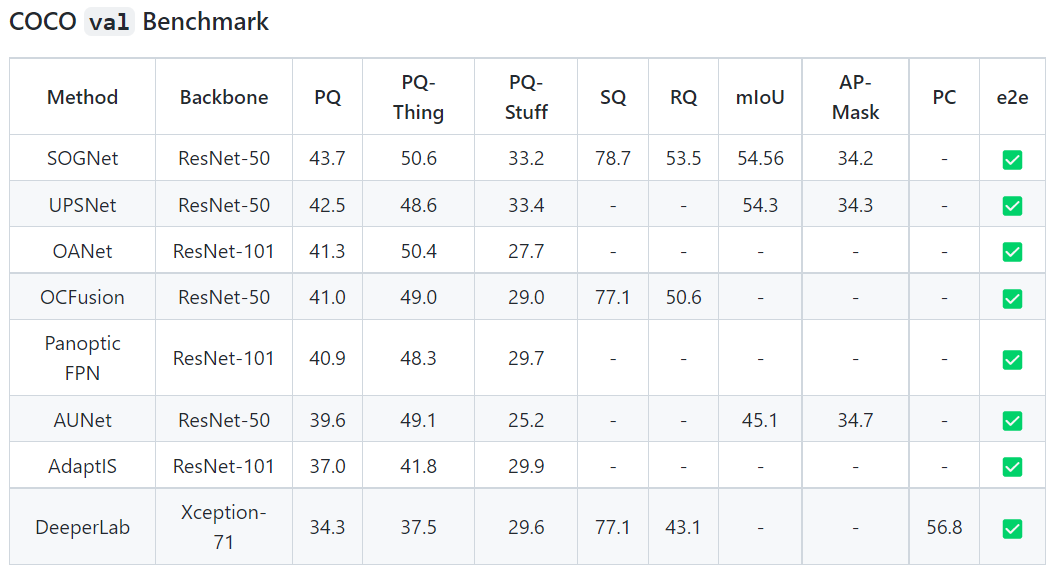
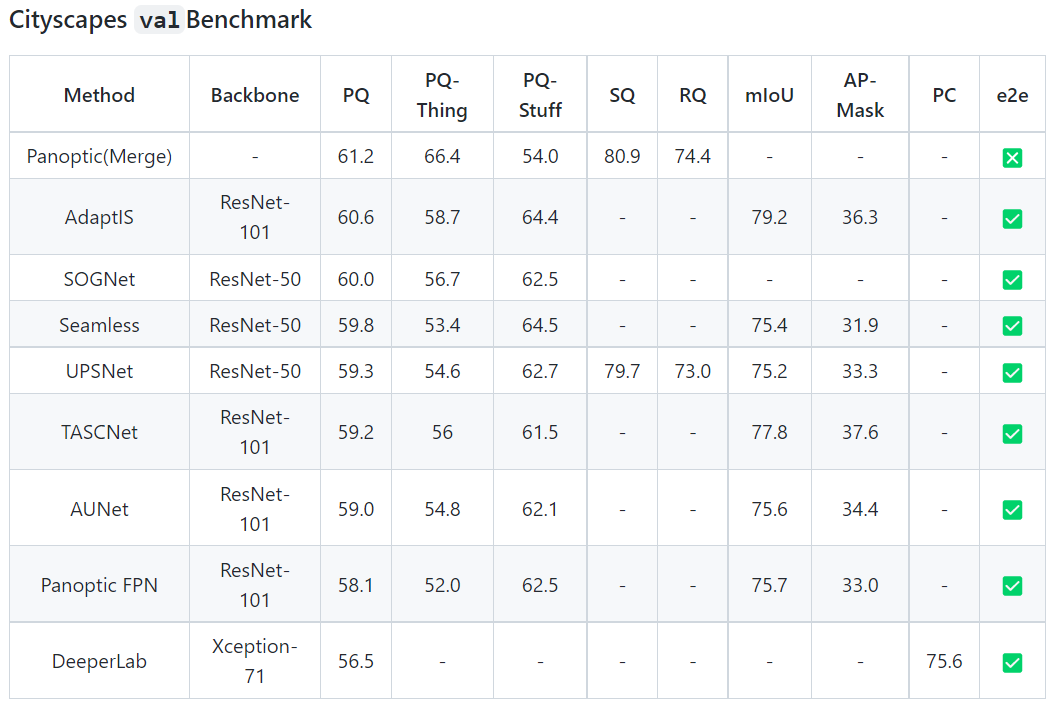
The comparison of different metrics for Panoptic segmentation on 2 most widely applied datasets is given below,
The benchmark comparison for COCO dataset is,
The benchmark comparison for Cityscapes dataset is,
Applications
The applications of panoptic segmentation are derived from the way it is defined i.e., it is wise to use panoptic segmentation only when the task at hand requires both instance and semantic identification.
- Autonomous vehicles
- Healthcare
- Geographic Survailenece
- Digital Image processing
References
The Result comparison for the different model was inspired from Angzz/awesome-panoptic-segmentation