
In this article, we will learn about pre-trained model PoseNet in detail which will be consisting of need and working of posenet,operations possible on it,its application, and possible improvement over existing posenet model.
What will we learn:
- What is Posenet ?
- How Posenet works ?
- Keywords explained used in Posenet
- Need of Posenet
- Operations on PoseNet
- Architecture of PoseNet
- About GoogleNet
- Full-Connected Layer in CNN
- Loss function in Posenet
- Improvements over the architecture of Posenet
- Conclusion
What is PoseNet ?
Posenet is the Pre-trained model used as post detection technique which can detect the human beings poses in the given video and images. In other words, Posenet is the deep learning tensorflow model which tells about the human pose by estimating the parts of the body designated as key points(which are 17 in total for this model) namely being nose,right elbow,right wrist etc which are connected with each other to form skeleton structure of the body and giving all the points confidence score as the model only estimates them to recognize a pose.
- Posenet can estimate either single or multiple poses.Either , we can determine the real time pose of objects using Pose estimation by using libraries like
ml5.js,ps5.jsandTensorflow.jsor we can do a pose detection of image set like COCO dataset etc using the same libraries.
Note:
ml5.js,ps5.jswill work in browser as it is with nearly no knowledge of python required for the same while If you want to implement using python,tensorflow.jsis a way to go which also works in browser but only difference being provides python support in it.
How Posenet works?
- Posenet was trained in MobileNet Architecture. MobileNet is a Covolutional Neural Network developed by Google on the ImageNet dataset, majorly being used for image classification and target estimation using confidence scores.
Some Perks of PoseNet model!!!
Also, Posenet being a lightweight model which uses depthwise seperable convulation to deepen the network by reducing the parameters,computation cost whcih in turn increases the accuracy of the model. Thus, being lightweight model it easily runs on the web browsers i.e. posenet is pretrained model that can be run on the browsers. This seperates it from other API dependent libraries making use of this model extensively on the variety of models with anyone having limited configration in a laptop or a personal desktop.
Posenet uses a total of 17 key points ranging from our eyes , ears to the ankles and knees also including the wrist,elbow,shoulder,nose as well.
If image given to posenet is not clear , then it returns the confidence score telling how much confident it is guessing the particular pose in the image.This is done in form of
JSONresponse.
Keywords used in Posenet Explained!!!!
The pose estimation happens when the input RGB image is processed through Convolutional neural network on which either multiple poses or single pose algorithmn is applied which give model outputs via stating the pose in the image, its pose confidence scores,keypoints positions and its keypoints confidence scores.
Let's look at each keyword one by one:
- Pose : PoseNet returns the pose object(can be single or multiple objects) with all the kepoints visble and an instance level confidence score for each detected person in the image being used as input.
- Pose Confidence Score : It determines the overall accuracy of the pose via confidence in estimation of the score which ranges from 0.0 to 1.0. This can be hidden if the input image dataset is not strong enough.
- Keypoint : As mentioned earlier as quote , a part of pose person makes is estimated via some points which are returned by Posenet itself which includes only 17 of them currently for example: nose, left foot,left knee, right ear, left hip ,right elbow etc.
All the points are shown below in the image [Fig(A)]:
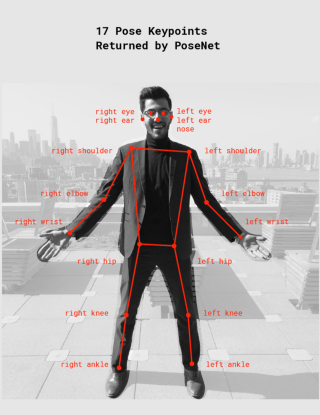
- Keypoint Confidence score : This determines the confidence in the accuracy of the estimated keypoint which raanges between 0.0 to 1.0. Like Pose confidence score, it can be used to hide kepoints if not deemed strong enough.
- Keypoint Position : The input image we will give to the model is divided into keypoints which are in short the 2D (x,y) coordinates detecting the useful keypoints in the whole image.
Need of Posenet
- Usually Posenet,vSLAM which are camera pose estimation models require abundant labeled data which can be decreased by using transfer learning. Also, reperesentation learned by CNN on large image classification data can be fine tuned to solve camera pose estimation problem with the use of much smaller datasets.
- Traditional vSLAM algorithms and solutions have been proposed for various environments and applications, most of which sahre similar structure. Thus, they face the same limitations precisely being:
Often losing track due to motion blur,high speed rotations,partial occulsions and presence of dynamic objects in the scene. Making them unsuitable for cases like unmanned aerial vehicles.
- Most commonly vSLAM algorithms rely on expensive pipelines having handcrafted database features,the camera intrinsic parameters, selection and storing of key frames, finding some feature correspondence among set of images etc. Also, for monocular images it suffer from phenomenon called as scale drift leading to inconsistent camera trajectories.
- To get rid of all these problems, Posenet comes with the end to end trainable architecture. Now, we will learn about the Posenet Architecture.
Architecture of Posenet
In this section, we will understand the Architecture of Posenet and details of it.
- Posenet uses the modified GoogleNet and leveraged the transfer learning from ImageNet dataset which is used for classsification task to train the network for pose detection using monocular images.Furtur, they increased the performance by curating and making more sophisticated loss functions required for optimiztion. This is furthur improved by using LSTM cells to better use the spatial information in each image.The required rows and columns are feeded to LSTM cells.The cells output at last timestamp is used to predict the 6-DoF Pose.
- To make the Posenet solutions more accurate to vSLAM soltuions by using what informations can be used to gain datasets attributes without imposing more complex CNN architecture.
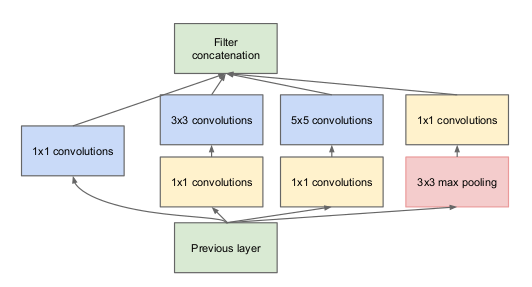
- GoogleNet, officialy designed for object classification and its detection has a 22 deep layers of neural networks based on inception module which is shown below:
The inception module also called as inception layer. [Fig(B)]
- Unlike vSLAM algorithms, Posenet works on monocular images plus being robust to motion blur and lighting conditions(if they are changed constantly). Also, they do not require access to camera parameters, good initialization and handcrafted features.
About GoogleNet:
- GoogleNet designed for the image detection and classification is a 22 layer deep neural network based on Inception module previously illustrated in Fig(B)
- GoogleNet takes input of 224 by 224 pixels and propagates through the 9 inception modules stacked up on top of each other using the ReLu
Rectified Linear units: whose output being f(x)= Max(0,x).Its precise use being better performance than others non-linear functions like: sigmoid,tanh and also, CNN can learn about non-linear values which makes its usable for real-world
- Just like this, the input data gets abstracted residing on the last layer along with two intermediate abstractions to fully connected and softmax layers for help in predicting object classes
Being the last layer of CNN, it takes the output by convulational process as input and applies linear transformation many times and finally a activation function for predicting class of image.
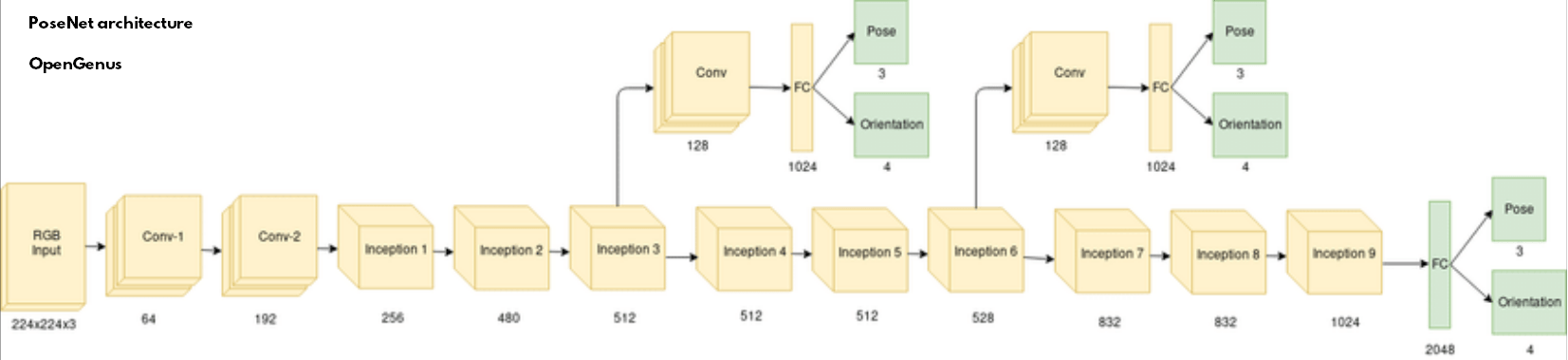
But, In posenet the softmax layers (which help in classification of images) is replaced by 2 parallel fully connected layers with 3 or 4 units respectively.These are generally regress to pose(demonstrated to (x,y,z) coordiantes) and orientation(represented as quaternion). Additionally , it adds 2048 units fully connected layer on the top of the last inception module
Posenet architecture shown below:[Fig C]
Operations on PoseNet
There are 3 functions on posenet namely Pose,Orientation and Full-Connected Layer which are linked up to all inception models, convulational process and to a 2048 units FC layer on top of last inception module.
Full-Connected Layer in CNN
- When the input,convulational and pooling layer make the feature extraction part possible which is the output of convolution process is the input to the Full connected Layer which the predicts the different classes of different images.
- We already know that, this layer transforms the input by applying linear transformations various times which is sent to activation function for prediction of class.
- The input given to this layer is like given to the layer like neural networks.
Here the feature map matrix with converted as vectors <x1,x2,x3,x4.....>. With the help of full connected layers and combining them we create the required model.Then, by using Sigmoid,softmax,ReLu we get the classes of the object inputted in the model. Although, softmax is replaced 2 parallel fully connected layers with 3 or 4 units respectively.These are generally regress to pose(demonstrated to (x,y,z) coordiantes) and orientation(represented as quaternion).
Loss function in Posenet
- According to the model described above which gives output vector x' and quaternion q' representing estimated position and orientation respectively. These parameters in the network are optimized for each image I for which loss function is calculated as:
Loss(I) = ||x-x'||2 + ß||q-q'||2
Here, x shows groundtruth position and q shows orientation. As, quaternions are limited to unit manifold , the orientation error becomes minimum and smaller than position error. That's why ß is used to balance the loss terms which is a constant scale factor.
But, authors of Posenet replaced this constant scale factor which is adaptive to improving accuracy of network and loss function for camera pose regression.
The new loss function is formulated according to homoscedastic uncertainity:
Loss(I) = ||x-x'||2× e(-ŝx) + ŝx + ||q-q'||2× e(-ŝq) + ŝq
Improvements over the architecture of Posenet
Some of the improvements that can be using more of localized sequences around the image via using the whole field-of-view as input which produces the best output and downsampling the frames of sequences and there being enough overlap between training and test data. Data augmentation can reduce the margin between the test and training data. And, by using LSTM cells (even of length 1) performs on average as good as for longer sequence lengths.This is helpful due to their relatively more complex archietcture compared to CNN's fully-connected layers which is even shown evidently on single image as input.
We can say that Posenet can be improved by giving field-of-view more importance than input image's resolution.Also, depending on the training labels one can cover more areas with more accuracy during the training time also gaining more accuracy on test time as well. Lastly, we can say LSTM cells are not that useful on temporal information as its invariant to small translations but they do perform better due to complex nature as compared to their counterparts fully connected layers.
Conclusion
We learned in this article at OpenGenus about posenet and why its needed over vSLAM algorithms. Also, we saw architecture of the posenet and how it can be improved via LSTM, increased field-of-vision,and data augmentation.Also , we learned about GoogleNet as well as operations on the posenet. Additionally , we also learned important keywords and loss function required in posenet.