
Get this book -> Problems on Array: For Interviews and Competitive Programming
RefineDet model is a popular Deep Learning model that is used for Object Detection applications as an alternative to SSD and YOLO based CNN models.
Table of contents:
- Introduction to Deep Learning Applications
- RefineDet model
- Different Object Detection models
Introduction to Deep Learning Applications
Computer Vision
Computer vision is a branch of artificial intelligence (AI) that allows computers and systems to extract useful information from digital photos, videos, and other visual inputs, as well as to conduct actions or make recommendations based on that data. If artificial intelligence allows computers to think, computer vision allows them to see, watch, and comprehend.
Human vision is similar to computer vision, with the exception that people have a head start. Human vision benefits from lifetimes of context to teach it how to distinguish objects apart, how far away they are, whether they are moving, and whether something is incorrect with an image. Computer vision teaches computers to execute similar tasks, but using cameras, data, and algorithms rather than retinas, optic nerves, and a visual cortex, it must do it in a fraction of the time. Because a system trained to check items or monitor a production asset may evaluate hundreds of products or processes per minute, detecting faults or issues that are invisible to humans, it can swiftly outperform humans.
A lot of data is required for computer vision. It repeats data analyses until it detects distinctions and, eventually, recognizes images. To teach a computer to recognize automotive tires, for example, it must be fed a large number of tire photos and tire-related materials in order for it to understand the differences and recognize a tire, particularly one with no faults.
Deep learning, a sort of machine learning, and a convolutional neural network are two key technologies utilized to do this (CNN). Machine learning is a technique that allows a computer to train itself about the context of visual input using algorithmic models. If enough data is supplied into the model, the computer will "look" at the data and learn to distinguish between images. Instead of someone training the machine to recognize an image, algorithms allow it to learn on its own. By breaking images down into pixels that are given tags or labels, a CNN aids a machine learning or deep learning model in "seeing." It creates predictions about what it's "seeing" by using the labels to do convolutions (a mathematical operation on two functions to produce a third function).
In a series of iterations, the neural network executes convolutions and assesses the accuracy of its predictions until the predictions start to come true. It then recognizes or sees images in a human-like manner. A CNN, like a human recognizing a picture from a distance, detects hard edges and simple forms first, then fills in the details as it runs iterations of its predictions.
To comprehend single images, a CNN is employed. In video applications, a recurrent neural network (RNN) is used in a similar way to help computers grasp how visuals in a sequence of frames are related to each other.
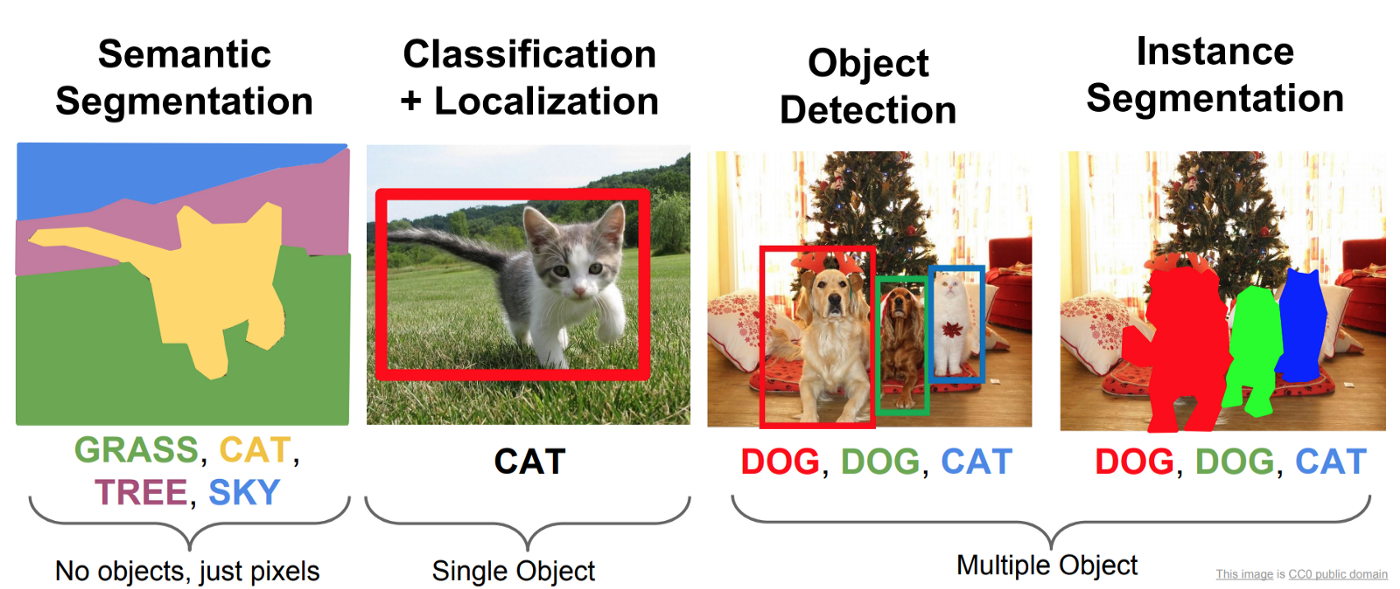
figure1: object detection
Image Classification
When an image is classified, it is passed through a classifier (such as a deep neural network) to generate a tag. Classifiers consider the entire image, but they do not indicate where the tag appears in the image.
Object Detection
Object detection is a deep learning system that allows items like people, buildings, and cars to be recognized as objects in images and movies. Object detection has been determined in a variety of computer vision applications, including object tracking, retrieval, video surveillance, picture captioning, image segmentation, Medical Imaging, and a slew of others.
Image Segmentation
Image segmentation is the process of determining which pixels in an image belong to which object class. Semantic picture segmentation will identify all pixels that relate to that tag, but it will not specify the object boundaries. Instead of segmenting the object, object detection uses a box to explicitly indicate the location of each individual object instance. When semantic segmentation and object detection are combined, instance segmentation is created, which finds object instances first and then segments each within the detected boxes (known in this case as regions of interest).
RefineDet model
To obtain the final result, RefineDet generates a predetermined number of bounding boxes and scores indicating the existence of distinct kinds of items in those boxes, followed by non-maximum suppression (NMS). The anchor refinement module (ARM) and the object detection module (ODM) are the two interconnected components that make up RefineDet (ODM). The backbone is made up of ILSVRC CLS-LOC pretrained VGG-16 and ResNet-101.
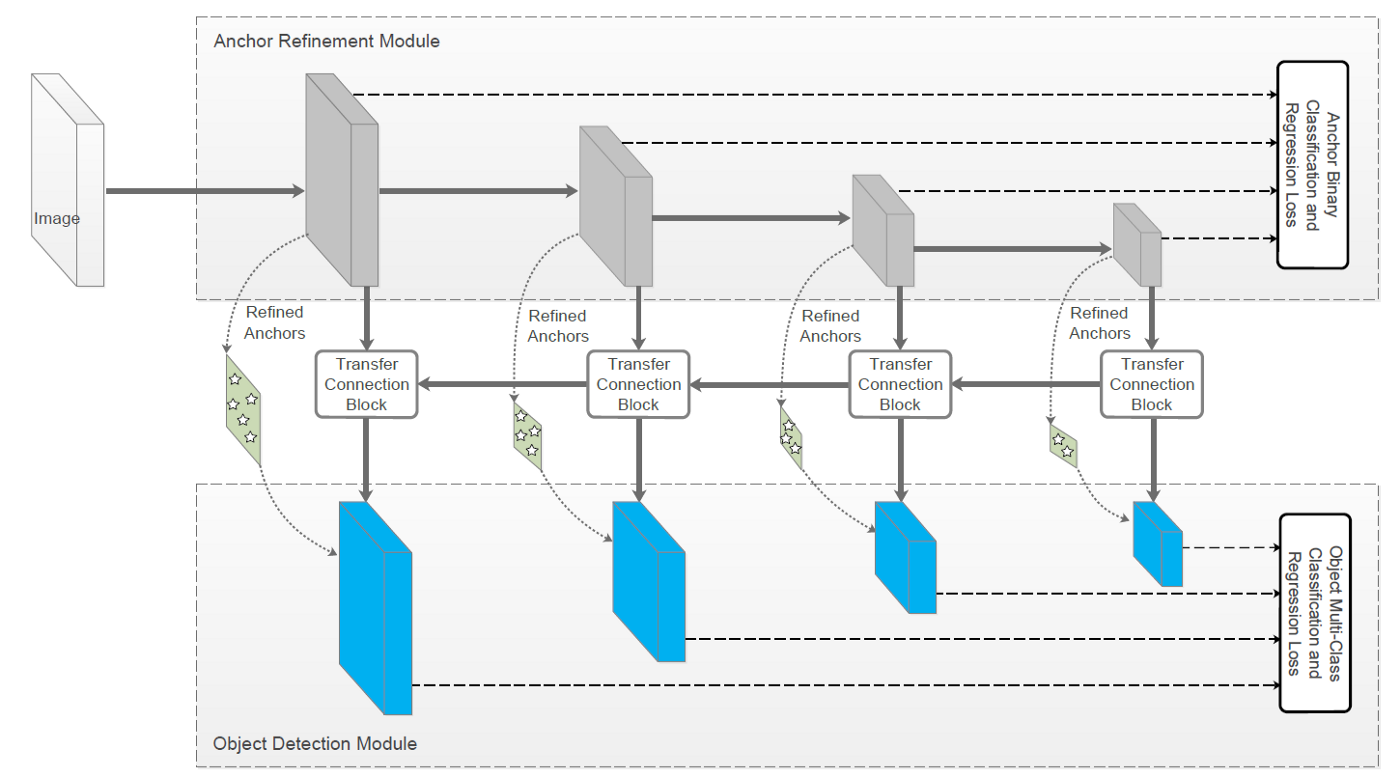
figure2: RefineDet: Network Architecture
Cascaded Regression in Two Steps
As previously stated, ARM removes negative anchors from the search area for the classifier and coarsely adjusts anchor placements and sizes.
To improve the regression and forecast multi-class label, ODM uses the revised anchors as input from ARM.
Designing and Matching Anchors
To handle varied scales of objects, four feature layers with total stride sizes of 8, 16, 32, and 64 pixels are used.
Each feature layer has a different anchor scale and three different aspect ratios.
Module for Anchor Refinement (ARM)
In SSD, there are pre-defined anchor boxes with fixed sizes, ratios, and placements.
As previously stated, ARM filters away negative anchors to limit the classifier's search space and coarsely adjusts the classifier's output. ARM tries to remove negative anchors to minimize the classifier's search space, as well as coarsely alter anchor placements and sizes to give better initialization for the subsequent regressor.
Each regularly divided cell on the feature map has n anchor boxes linked with it.
Four refined anchor box offsets are projected for each feature map cell.
To indicate the existence of foreground items in those boxes, two confidence ratings are used.
Filtering using Negative Anchors
The anchor box is rejected in ODM training if its negative confidence is greater than a predefined threshold (i.e. 0.99 experimentally). It's almost certain that it's a backdrop. To teach the ODM, only the refined hard negative anchor boxes and refined positive anchor boxes are used.
Object detection module (ODM)
The revised anchor boxes are given to the respective feature maps in the ODM when they have been obtained. Based on the improved anchors, ODM tries to regress accurate object locations and forecast multi-class labels.
To complete the detection task, c class scores and the four accurate offsets of objects relative to the refined anchor boxes are calculated, producing c + 4 outputs for each refined anchor box.
Hard Negative Mining
To compensate for the high foreground-background class imbalance, hard negative mining is employed. Instead of employing all negative anchors or randomly selecting negative anchors in training, some negative anchor boxes with top loss values are chosen to keep the ratio between negatives and positives below 3:1.
Transfer connection block (TCB)
For detection, TCB transforms the characteristics from the ARM to the ODM. The goal of TCBs is to improve detection accuracy by integrating large-scale context by adding high-level features to the transferred information.
The deconvolution procedure is used to increase the high-level feature maps and sum them element-wise to match the dimensions between them.
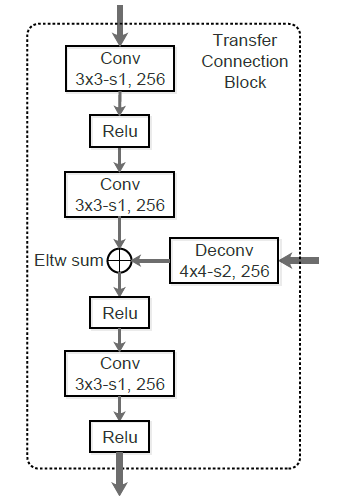
figure3: Transfer connection block
Loss Function & Inference
Loss Function
As a result, RefineDet's loss function is divided into two parts: the loss in the ARM and the loss in the ODM. For the ARM, each anchor is given a binary class name (whether it is an object or not) and its location and size are regressed at the same time to produce the refined anchor. The improved anchors with a negative confidence smaller than the threshold are then provided to the ODM, which uses them to forecast object categories as well as precise item locations and sizes.
The loss function is as follows:
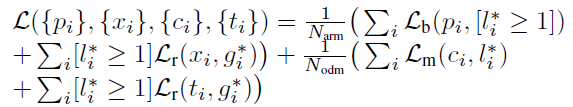
The numbers of positive anchors in the ARM and ODM, respectively, are Narm and Nodm.
The cross-entropy/log loss over two classes is the binary classification loss Lb (object vs. not object). The softmax loss over multiple classes confidences is the multi-class classification loss Lm. Smooth L1 loss is employed as the regression loss Lr, similar to Fast R-CNN. For negative anchors, [li* ≥ 1] signifies that the regression loss is ignored.
Inference
The regularly tiled anchors with negative confidence scores greater than the threshold 0.99 are first filtered out by ARM. ODM replaces these refined anchors with the top 400 most confident detections every image. NMS is used, with a jaccard overlap of 0.45 per class. To obtain the final detection results, the top 200 high confident detections per image are kept.
Different Object Detection models
SSD
The Single Shot MultiBox Detector (SSD) starts with a collection of default boxes rather than predicting them from scratch. It uses a fixed set of default boxes of different aspect ratios per cell in each of those grids/feature maps and several feature maps of different scales (i.e. several grids of different sizes like 4 x 4, 8 x 8, etc.) and a fixed set of default boxes of different aspect ratios per cell in each of those grids/feature maps. The model then computes the "offsets" as well as the class probabilities for each default box. The offsets are made up of four numbers: cx, cy, w, and h, which represent the center coordinates, width, and height of the real box in relation to the default box.
SSD also takes a different approach to matching object ground truth boxes to default boxes. There is no one default box that is held responsible for an item and is matched to it. Instead, any ground truth with IOU greater than a threshold is matched to default boxes (0.5). This means that numerous default boxes overlapping with the object will be projected to get high scores, rather than only one of those boxes being held responsible.

YOLO
Yolo divides the input image into a S S grid, for example. Each grid cell is assessed not just for the class probabilities discussed above, but also for a set of "B" bounding boxes and confidence scores for those boxes.
To put it another way, unlike our basic thought exercise, the boxes are predicted together with the class probabilities for the cell. There are five predictions in each bounding box: x, y, w, h, and confidence. The first four deal to coordinates, while the last one, confidence, shows the model's confidence that the box includes an object as well as the accuracy of the box coordinates.
Furthermore, the grid cell in which the item's center is located is responsible for establishing the box coordinates of the object. This helps prevent numerous cells determining boxes around the same object. Nonetheless, each cell predicts many bounding boxes. During training, one of these boxes is designated as "responsible" for predicting an object, based on whose prediction has the highest current IOU with the ground truth. During training, the multiple bounding boxes in each cell specialize in predicting specific sizes, aspect ratios, or item types, which improves overall recall.
These forecasts are represented as a S S (B 5 + C) tensor (S x S is the grid dimension, B is the boxes each cell in the grid will determine, 5 is the predictions made per box namely x, y, w, h and confidence, C is the probabilities for the C classes of objects the model can identify).

With this article at OpenGenus, you must have a good idea of RefineDet model.