
Get this book -> Problems on Array: For Interviews and Competitive Programming
For the real-world smart systems and applications of today, traditional supervised learning provides quick and precise predictions. It is not, however, evolving to meet the evolving demands of today's sophisticated decision-making. A remedy that can concurrently anticipate several outcomes from a single input is multi-output learning. The corpus of literature in this area has expanded quickly, and a number of publications have been given that give a thorough analysis of the new problems and learning strategies in each discipline.
In this article at OpenGenus, we have explored the part of Deep Learning where a model is trained to produce multi-outputs (more than 1) in contrast to standard Deep Learning models like ResNet50 for Image Recognition.
Table of contents:
- Four Vs Challenges of Multiple Outputs
- Life cycle of the output label
- Multi-output learning
- The challenges of multi-output learning and representative works
- Multi-output CNN models
Four Vs Challenges of Multiple Outputs
- Volume poses challenges to multi-output learning, such as scalability issues, burden for label annotators, and label imbalance issues.
- Velocity can be a challenge due to changes in output distribution.
- Variety refers to the heterogeneous nature of output labels.
- Veracity refers to differences in output labels due to noise, missing values, abnormalities, or incomplete data.
Life cycle of the output label
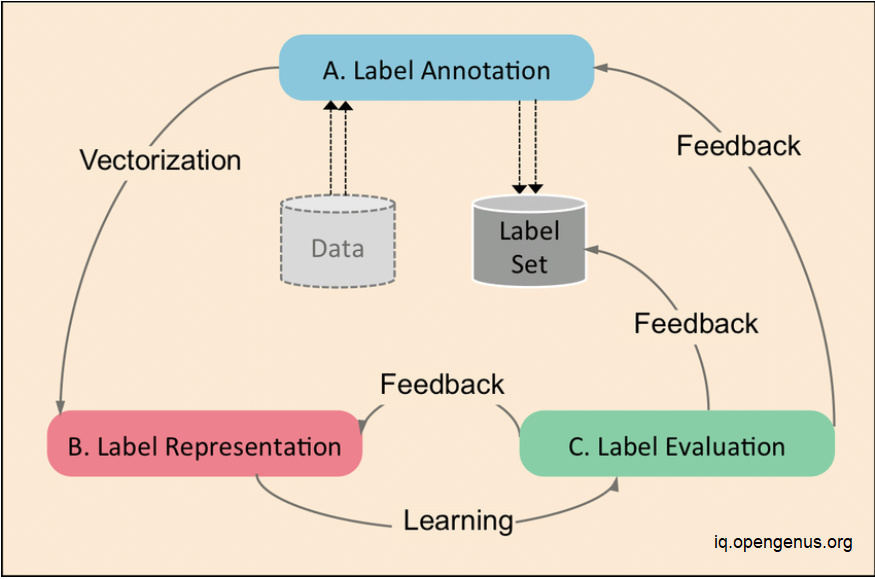
1. How is Data Labeled
Label annotation is a crucial step for training multi-output learning models. It can be used directly or aggregated into sets for further analysis. There are multiple ways to acquire labeled data, such as social media, open source collections, and crowdsourcing platforms. ImageNet is a popular dataset that was labeled through a crowdsourcing platform and has been used to help researchers solve problems in a range of areas.
2. Forms of Label Representations
Label annotations are often represented as vectors, but binary vectors are not optimal for more complex multi-output tasks. Alternative representation methods have been developed, such as real-valued vectors of tags, hierarchical label embedding vectors, and semantic word vectors. It is important to select the label representation that is most appropriate for the given task.
3. Label Evaluation and Challenges
A crucial stage in ensuring the caliber of labels and label representations is label assessment. Label quality can be assessed using a variety of models, and labels can be assessed in three different ways: first, whether the annotation is of high quality; second, whether the selected label representation accurately captures the labels; and third, whether the provided label set sufficiently covers the dataset. A human expert is typically required to investigate any underlying problems and offer input to enhance various elements of the labels as necessary after the examination. Label representation problems include internal structures and ambiguity, whereas label annotation problems include missing and inaccurate annotations.
Multi-output learning
A. Myriads of Output Structures
The increasing demand for sophisticated decision-making tasks has led to new creations of outputs, some of which have complex structures. Output labels can be text, images, audio, or video, or a combination as multimedia. There are also a number of different output structures, such as independent vectors, binary vectors, real-valued vectors, and weighted vectors, which can be used for annotation or classification. An independent vector can be used to represent the tags of an image, while distributions provide information about the probability that a particular dimension will be associated with a particular data sample. Outputs can be in the form of a ranking, keywords, sentences, paragraphs, or documents. Sequence outputs refer to a series of elements selected from a label set, and an output sequence often corresponds to an input sequence. In the example shown in Fig. 2 (5), the input is an image caption, i.e., text, and the outputs are part-of-speech(POS) tags for the image.
B. Problem Definition of Multi-output Learning
Multi-label learning is the task of learning a function that predicts the proper label sets for unseen instances. Multi-target regression is to simultaneously predict multiple real-valued output variables for one instance. Label distribution learning determines the relative importance of each label in the multi-label learning problem. Label Ranking is the goal of label ranking. Sequence alignment learning produces a sequence of multiple labels for an input instance.Network analysis explores the relationships between objects and entities in a network structure, and link prediction is a common task. Data generation is a subfield of multioutput learning that aims to create and then output structured data of a certain distribution. Deep generative models are used to generate the data.
C. Special Cases of Multi-output Learning
Multi-class classification is a traditional single-output learning paradigm, while fine-grained classification is a challenging multi-classification task with subtle visual differences. Multi-task learning (MTL) is a subfield that aims to improve generalization performance by learning multiple related tasks simultaneously. Different tasks might be trained on different training sets or features, while the output variables usually share the same training data or features.
D. Model Evaluation Metrics
The conventional evaluation metrics used to assess multi-output learning models with a test dataset are example-based, label-based and ranking-based. Example-based metrics evaluate the performance of models with respect to each data instance, while label-based metrics assess the performance of the model with respect to the set of labels corresponding to the predicted and actual output. Hamming loss is an example-based metric that computes the average difference between the predicted and output, while micro-averaging measures the number of times the top-ranked label is not in the true label set. Ranking-based metrics measure the average proportion of incorrectly ordered label pairs, average Precision (AP) is the proportion of labels ranked above a particular label as an average over all the true labels, and mean absolute error (MAE) is a classic single-output regression metric that can be extended to multi-output regression models. Intersection over union threshold (IOU) is a specifically designed metric for assessing object localization or segmentation.
E. Multi-output Learning Datasets
The datasets used to experiment with multi-output learning problems have either been constructed or become popular because they reflect a challenge that needs to be overcome. Table II lists the datasets, including their multi-output characteristics, the challenge can be tested, the application domain, plus the dataset name, source, and descriptive statistics. Large-scale datasets, such as those used to test volume, are extremely large and illustrate the need to overcome the challenges caused by this particular V among the 4. Additionally, datasets designed to test complex multi-output problems contain a mix of different output structures and can be used to test the variety of data. Finally, veracity is tested by adding artificial noise to a clean dataset.
The challenges of multi-output learning and representative works
A. Volume - Extreme Output Dimensions
Large-scale data sets are ubiquitous in real-world applications, but the issues associated with high output dimensions have received less attention. An analysis of the current state-of-the-art research on ultrahigh-output dimensions revealed some interesting insights. Quantitative approaches/discriminative models can be used to reduce output dimensionality, and embedding methods such as randomized embedding and AnnexML can be used for extreme output dimensions.
B. Variety - Complex Structures
Multi-output learning is challenging due to the complexity of complex output structures. To obtain better performance, many classic learning methods have been proposed to model multiple outputs with interdependencies, such as label powersets (LPs) and classifier chains (CCs). Random k-label sets are a variant of LP that alleviates the computational complexity problem by training each label separately. ECC, PCCs, CCMC, SSVM, and structured hinge loss are all proposed to solve this problem. The predicted output of a multi-output learning model is affected by different loss functions, such as hinge loss, negative log loss, perceptron loss, and soft max margin loss. The margin, has different definitions based on the output structures and task.
C. Volume - Extreme Class Imbalances
Multi-output applications rarely provide data with equal number of training instances for all labels/classes, so traditional models tend to favor majority classes more. To balance class distributions, resampling techniques such as undersampling and oversampling are used, but these are mainly designed for single-output learning problems. There are other techniques to handle class imbalance, such as incremental rectification of mini-batches with a deep neural network, and adversarial training to mitigate imbalance.
D. Volume - Unseen Output
Multi-output learning involves training actions based on prior knowledge of action-toattribute mappings, but this may not be true in real-world applications. Jain et al. proposed Objects2action, which leverages object annotations, images, and text descriptions from open-source collections, and Mettes and Snoek have further enhanced Objects2action by considering relationships between actors and objects. Open-set recognition is the most generalized problem studied in conjunctions with multi-class classification.
E. Veracity - Noisy Output Labels
In real-world applications, it is necessary to handle noisy outputs, such as missing, corrupt, incorrect, and/or partial labels. Missing labels are caused by human annotators annotating an image or document with prominent labels but missing some of the less emphasized labels. To handle missing labels, modeling tasks are performed based on a fully labeled data set, but this approach can introduce undesirable bias. Multi-output learning algorithms that learn from noisy data sets are of great practical importance, and two main types of multi-output learning methods are based on building robust loss functions and learning latent labels. Partial multi-label learning (PML) relaxes this assumption by leveraging the data structure information to optimize the confidence weighted rank loss.
F. Velocity - Changes in Output Distribution
Real-world applications must deal with data streams, where the output distributions can change over time or concept drift can occur. Existing multi-output learning methods model changes in output distribution by updating the learning system each time data streams arrive. Strategies to handle concept drift include the assumption of a fading effect on past data, maintaining a change detector, and using stochastic gradient descent. Online hashing and online quantization-based methods are proposed to improve the efficiency of kNN while accommodating the changing output distribution.
Multi-output CNN models
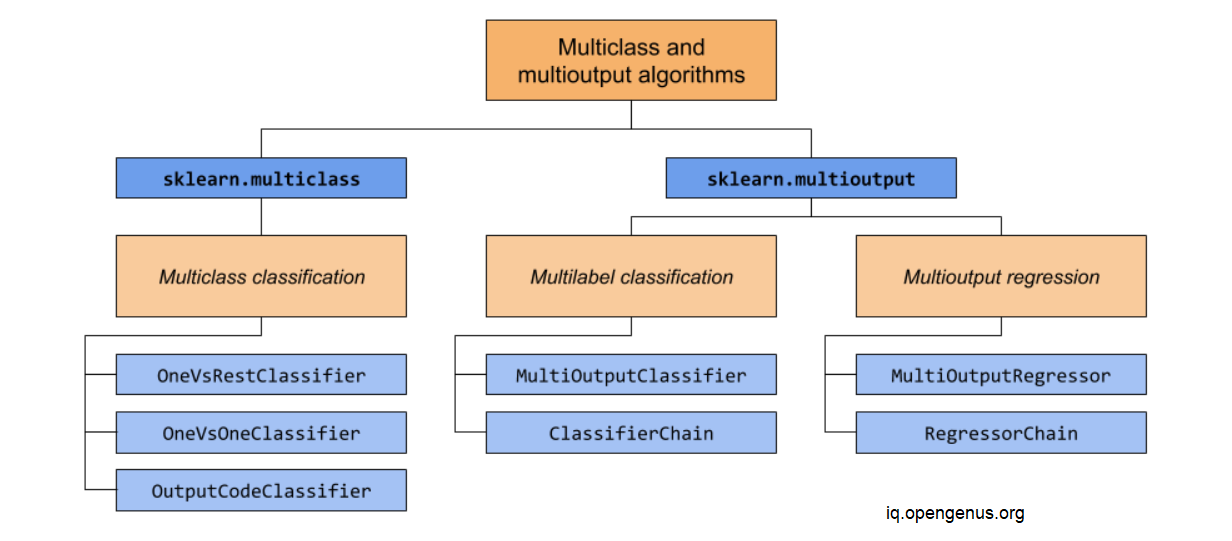
Multiclass classification
Multiclass classification is a classification task with more than two classes, where each sample is assigned to one and only one label. Examples include classification using features extracted from images of fruit, where each image is one sample and labeled as one of the 3 possible classes. All scikit-learn classifiers are capable of multiclass classification, but meta-estimators offered by sklearn.multiclass may have an effect on classifier performance.
Multilabel classification
Multilabel classification is a classification task that labels each sample with m labels from n_classes possible classes, where m can be 0 to n_classes inclusive. Formally, a binary output is assigned to each class, with positive classes indicated with 1 and negative classes with 0 or -1. This approach treats each label independently, while multilabel classifiers may treat the multiple classes simultaneously, accounting for correlated behavior among them. For example, prediction of the topics relevant to a text document or video may be about one of 'religion', 'politics', 'finance' or 'education'.
Multiclass-multioutput classification
Multiclass-multioutput classification (also known as multitask classification) is a classification task which labels each sample with a set of non-binary properties. It is a generalization of the multilabel classification task, which only considers binary attributes, as well as the multiclass classification task, where only one property is considered. For example, classification of the properties "type of fruit" and "colour" for a set of images of fruit. Each sample is an image of a fruit, a label is output for both properties and each label is one of the possible classes of the corresponding property. Multitask classification is similar to the multioutput classification task with different model formulations.
Multioutput regression
Multioutput regression predicts multiple numerical properties for each sample. Each property is a numerical variable and the number of properties to be predicted is greater than or equal to 2. Some estimators that support multioutput regression are faster than just running n_output estimators. For example, prediction of both wind speed and wind direction, in degrees, using data obtained at a certain location.
DL model with multiple output (YOLOv4 model)
YOLOv4 is a SOTA (state-of-the-art) real-time Object Detection model published in April 2020 by Alexey Bochkovsky. It is a one-stage detector with ROI not selected, making it faster than two-stage detectors. It is written in the Darknet Framework and divides the object-detection task into regression and classification tasks.
DL model with a single output (ResNet50 model).
ResNet50 is a variant of ResNet model with 48 Convolution layers, 1 MaxPool and 1 Average Pool layer, 3.8 x 10^9 Floating points operations, and Residual learning for training ultra deep neural networks.
Over the past 10 years, multi-output learning has gained a lot of interest. This article offers a thorough analysis of the research on multi-output learning using the four Vs as a framework. We start by looking at the output labels' life cycle before moving on to other aspects of the multi-output learning paradigm. We place emphasis on the problems related to each stage of the learning process. With example works cited throughout, we also give an overview of the several output kinds, the structures, particular issue descriptions, standard model assessment metrics, and well-known data sources utilised in trials. The issues brought on by the four Vs are discussed in the article's conclusion, along with several promising areas for further research.