
In this article, we have presented how to work with CSV files (Comma Separated Values) in Python like reading CSV files and processing the information stored in it. We have presented the ideas with Python code examples with output.
Table of contents:
- Introduction to CSV file
- Loading and reading CSV files
- Converting datatypes
- Intro to Dictionaries in Python
- Conclusion
Introduction to CSV file
CSV stands for Comma Seperated Values, and it is the most common format used for exchanging and updating datasets . It is essentially rows of data. Each row is on a different line, with the first row usually being the column headings and columns are seperated by commas.
In this tutorial, we are going to work on a csv file I created myself. It shows 10 people from different locations, ages, income and jobs who have bought the new OpenGenus car and their opinions of the car, saved as OpenGenuscarreviews.csv.
We will learn to Load the csv file, convert datatypes and work with dictionaries.
Note; be sure to read and understand the comments in any code in this article
idx,name,gender,age,income,opinion
1,roger,m,43,72000,like
2,natalie,f,31,63000,like
3,mayresh,m,25,50000,neutral
4,javier,m,45,67000,dislike
5,terry,m,54,56000,neutral
6,anna,f,32,72000,dislike
7,joseph,m,52,77000,like
8,franklyn,f,32,84000,dislike
9,alex,f,28,68000,neutral
10,timothy,m,30,80000,like
Loading and reading CSV files
First thing we have to do is to load the csv file. We are going to create a function called load_file() that a file from a specified path and return a dataset we can work with in our python domain.
import csv
def load_file():
filename = 'OpenGenuscarreviews.csv'
# Or full path to file if the file is not saved in the same directory
file = open(filename, 'r')
# This tells python to open our csv file for the #purpose of reading its
# contents
lines = csv.reader(file)
# csv.reader() is an iterator that returns each row of the file as an iterable
data = list(lines) # renders "lines" as a list of rows
return data
A more efficient way to write this code is shown the the following picture.
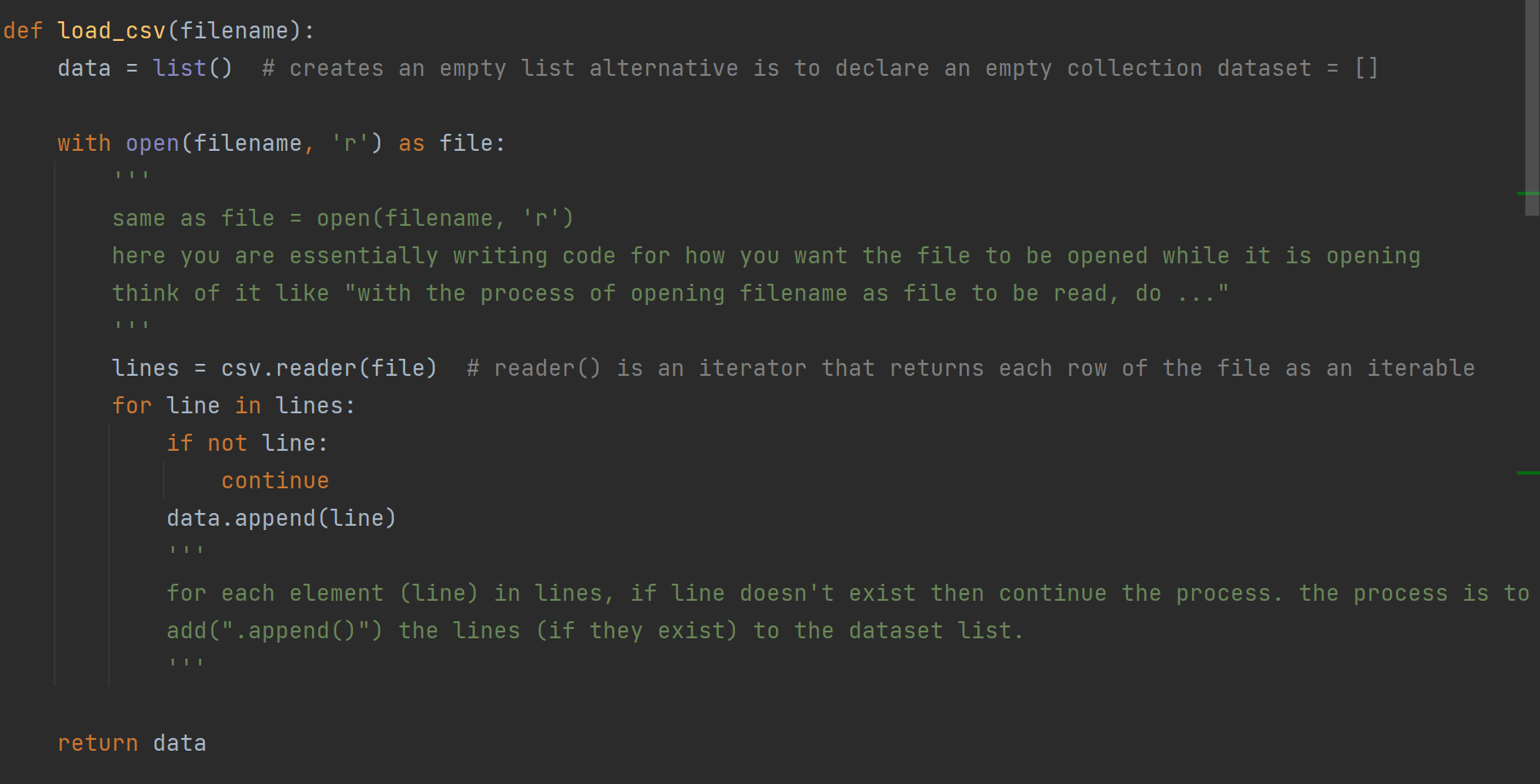
Converting datatypes
There are various datatypes to work with in Python, example: strings, integerts, floats, boolean, etc.
CSV files store every entry as a string. In some cases a string is the datatype we will need but in some cases where the data is going to be used calculations or graphing we will need integers, or floats.
If you type print(data) in your editor, our csv file now will look like this on the console;
['idx','name','gender','age','income','opinion']
['1','roger','m','43','72000','like']
['2','natalie','f','31','63000','like']
['3','mayresh','m','25','50000','neutral']...
Each element of each row is a string. We can't make any calculations or graphs with the ages and incomes because python has stored them as strings. You can check the datatypes of elements(or variables) using datatype(element).
print(type(data[1][3])
# data[1][3] has the age of roger which is 43 but the console returns
# <class string>
To change the datatype of an element or variable in python you simply enclose the variable with the python representation of that datatype. i.e
int(data[1][3])
Infact, lets do that for all the indexes,ages and incomes. We will iterate through every element in data from the second (because the first element has the column headings, remember?), and make convert the positions with ages and incomes to integers. Nevermind the idx column, in some cases the first element of each row in a csv file is an also used for categorizing(uncommon though, just wanted to give you a taste of what that looks like).
for i in range(1,len(data)):
data[i][3] = int(data[i][3]) # For ages
data[i][4] = float(data[i][4]) # For incomes
Now, all your ages are integers and all your incomes are floats, and can both be used for calculations.
Note: Python starts indexing at 0, so the 1st element of a list is 0 and the 2nd is 1
Intro to Dictionaries in Python
There are certain limitations to datatype conversion. Not because of an underlying limitation of python or other programming languages, but because of the very nature of some datatypes. For example, for a boolean 'N', 'Y'; you can use a set of codes to convert them to 1, 0 but you can't make N or Y integers. You likewise can't make numbers = 'OneTwoThree', 123 by using int(numbers).
For the purposes of this article, we will use dictionaries to convert the reviews into integers that represent each opinion: liked, disliked, neutral to 0, 1, 2.
opinions = [data[i][5] for i in range(1,len(data))]
# This is another way to define a list or set, take it as a bonus lesson.
# It is essentially saying " I want a list called opinions, which is defined as
# each 6th element in data from the second element.
unique_opinions = set(opinions)
# set() is a built-in python function. This will return the distinct values in a
# given list as a dictionary
We have sucessfully, extracted the distinct opinions given by the buyers. Now we want to find the integers to represent them with. You could always use any number you want to represent them, for the chance of potentially learning something new, we will represent each opinion by its index.
values = dict()
for idx, opinion in enumerate(unique_opinions):
value[opinion] = idx
In the code above, we enumerated our unique opinions(i.e numbered our list), and assigned each unique opinion a value, which is its index after the enumeration. 'print(value)' will return {'dislike': 0, 'like': 1, 'neutral': 2} in the console. Note that the indexes weren't returned as strings but as integers!
Now we need to replace each opinion with its integer correspondent. Note that, dictionaries are declared with curly brackets(i.e {}), and regular lists and colllections are defined with square brackets(i.e []).
for i in range(1, len(data)):
data[i][5] = value[data[i][5]]
After this if you type 'print(data)' in the editor the console will return the table but with each opinion as its integer representative. i.e...
['idx','name','gender','age','income','opinion']
['1','roger','m',43,72000,0]
['2','natalie','f',31,63000,0]
['3','mayresh','m',25,50000,2]...
Note that set() won't give the same values in the same sequence every time you run it; so dislike, like, neutral could be 0,1,2 or 2,0,1 or ,1,0,2 respectively everytime you run the code.
Conclusion
In this tutorial at OpenGenus, we have learned to open a file to be read, to convert datatypes in two different ways, and an introduction to dictionaries. This is the kind of introductory work that a data scientist might do when they are presented with csv data to make sense out of.
To peak your curiosity I will recommend a short task; why don't you figure out a way to adjust our code so that like, dislike, neutral is always going to be 0,1,2? Hint, you can use for 4 loops and replace().