
Pre-trained language models such as ERNIE, GPT, BERT have revolutionized the field of Natural Language Processing (NLP) by improving language generation, analysis and understanding. This article at OpenGenus aims to provide you an overview of Baidu's ERNIE 3.0 TITAN LLM and briefly explore its architecture.
Table Of Contents:
- What is ERNIE 3.0 TITAN LLM?
- Architecture of ERNIE 3.0 TITAN.
- Facts and key points about the Model.
What is ERNIE 3.0 TITAN LLM?
In 2021, Baidu, one of China's leading multinational technology companies, developed Large Language Model (LLM) called ERNIE (Enhanced Representation through Knowledge Integration) 3.0 TITAN, the largest ERNIE model to date with 260 billion parameters. It is an improved and more powerful version of the original ERNIE 3 model. It has excelled in tasks such as Sentiment Analysis, Relation Extraction, Legal Document Analysis, Closed-Book Question Answering, Text Classification, Machine Translation etc.
Large Language Model (LLM) - A large language model is a type of self-supervise Artificial Intelligence technique that is trained to understand, summarize and generate new natural language content. It is typically trained on large datasets of text, such as Wikipedia, books, or news articles, using techniques like deep learning and neural networks. The ELIZA Language Model developed by MIT in 1966 is one of the first AI language models. Some examples of LLMs are GPT-4, Megatron-Turing NLG, GLaM (Generalist Language Model) and BERT.
Architecture of ERNIE 3.0 TITAN
Here is the architecture of the model. We will explore the main components of the model's framework.
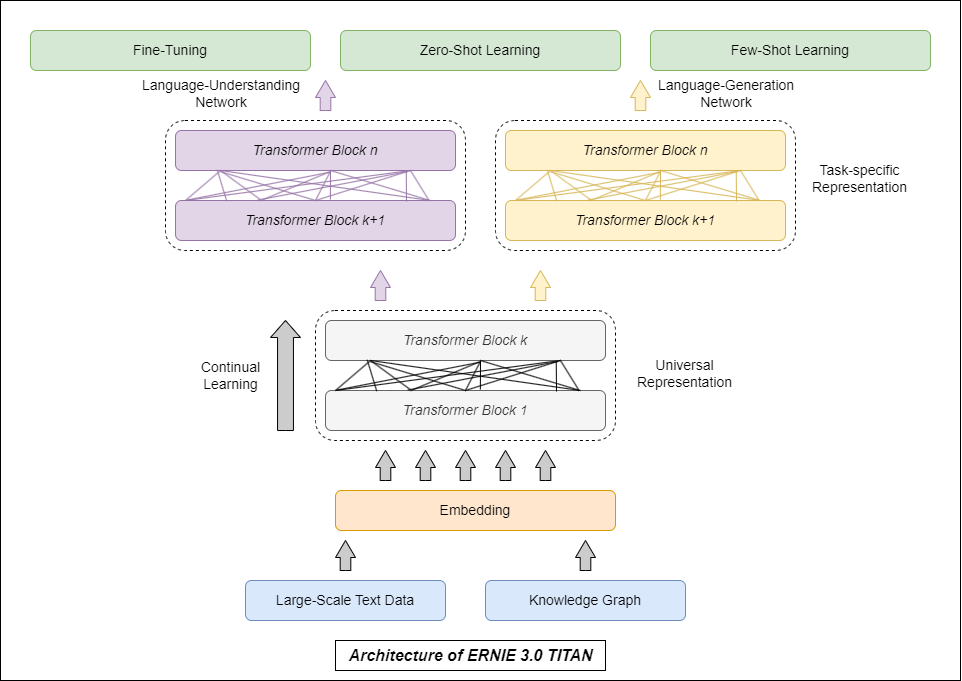
Knowledge Graph (Semantic Network) - It is a directed labeled graph which is a representation of a network of real-world entities. It shows the relationship between the entities and puts data into context. It consists of nodes and edges, where the nodes represent entities (such as people, objects and places) and the edges connecting them represents the relationships between them. It is designed to teach the model to encode the meaning and relationships of words and sentences, such as by predicting missing words in a sentence or detecting whether two sentences are related.
Embedding Layers - In Natural Language Processing(NLP) applications, the embedding layers convert each word in an input text/block into an a high-dimensional continuous vector representation. It allows the model to better understand the syntactic & semantic relationship between words and the context of individual words for gaining a holistic understanding of a text.
Transformer Blocks - Ernie 3.0 TITAN LLM is based on the Transformer architecture which is a type of a Neural Network architecture best suited for NLP applications. Transformer blocks are sub components of the Transformer Layer. It is designed to capture complex underlying patterns and interconnected relationships in natural language data. In ERNIE 3 TITAN, each transformer layer consists of 30 transformer blocks, spanning over a total of 300 blocks across the entire model.
Each Transformer block in ERNIE 3 Titan LLM has the following components:
-
Multi-Head Self-Attention Mechanism: This component allows the model to focus on different parts of the input sequence at each layer, by attending to different parts of the sequence simultaneously which allows the model to capture dependencies between words that are farther apart in the input sequence.
-
Feedforward Neural Network: This component processes the output of the self-attention mechanism, applying a series of linear transformations and non-linear activations to generate a new representation of the input sequence.
-
Layer Normalization: This component normalizes the output of the feedforward neural network, making it easier for the model to learn the underlying patterns and relationships in the input data.
Fine Tuning - It is based on the method of Transfer Learning where the knowledge/information obtained from performing one problem is applied to another problem. It takes a model that has already been trained on one task and tunes it to perform in order to perform another similar task. It allows a model to adapt to a new task and lead to improved performance when compared to creating & training a new model from scratch.
Zero-Shot Learning - It is a Machine Learning technique where a pre-trained model is trained to recognize classes it has never seen before (there is no explicit training data for those classes). In ERNIE 3 TITAN, the model uses its previous understanding of semantic connections between words/sentences to describe relationships between new attributes.
Few-Shot Learning - It is a Supervised ML technique that aims to train a model with only limited training data or examples, as opposed to the traditional approach where huge amounts of training data is fed to a model.
Facts and key points about the model
- Though it is trained on both English and Chinese, it is the largest Chinese dense pre-trained language model with over 260 billion parameters. For context, OpenAI's GPT-3 utilizes 175 billion parameters.
- Utilizes an online distillation framework for easy deployment. It contains 4 key features, i.e. Ability to teach multiple students at the same time, On-The-Fly Distillation (OFD) technique, introduction of teacher assistants for better distillation of large scale models, introduction of Auxiliary Layer Distillation (ALD). A distillation framework is where a small network (student) is trained by a larger network (teacher).
- The corpus/textual database size is over 4TB.
- It outperformed several models in solving 68 NLP datasets, achieving state-of-the-art results.
- It is a low cost model as the model parameter compression rate is around 99.98%.
- Several LLMS fail to generate texts that are factually consistent with the real-world which might make it less credible. In order to bridge the gap, a self-supervised adversarial loss and controllable language modeling loss are optimized and tuned during the pre-training phase in ERNIE 3.0 TITAN.
- The first version, ERNIE 1.0 was deployed in 2019. ERNIE 3.0 ZEUS, the latest entry in the ERNIE series, was announced in late 2022.
With this article at OpenGenus, you must have a comprehensive idea of ERNIE 3.0 TITAN LLM.