
Did you ever wondered how an Information Retrieval occur when you search for a query on Google or any other search engine?
Information Retrieval can be defined as finding material of an unstructured nature that satisfies the information need from within large collections.
In the 90's, the searching for an information on the Internet is less memory consuming because at that time there is less document available online and that is in structured manner on the Internet, but as the Internet usage started rising unstructured data(raw text) is dominated by structured data. So it gets difficult to retrieve information need from such a large collection if the query is written in Natural Language.
In this segment we will go through some methodologies of how text data is handled for the query retrieval.
GREP
GREP is abbreviated for Global Regular Expression Print. When we are dealing with small amount of data we can typically just use regular expressions to linearly scan through the data to extract the information we are looking for. Consider we want to search which play of Shakespeare contain the words Brutus AND Caesar but NOT Calpurnia. Then GREP could be used to find Brutus and Caesar from all of the Shakespeare's play and then strip out the line containing Calpuria.
But this method had to be depraved because of the reasons:
- Cannot able to retrieve the document which best ranked (document that contains the query words maximum times).
- Worked slow for large corpus.
GREP can be used for searching through small amount of data but when we are looking about more significant amounts of data we really need to do some indexing, pre-processing of that data beforehand so that we can efficiently query it.
The fundamental ideas for Information Retrieval is Indexing Data.
The first type of indexing that we are exploring is Term Document Matrix or Term Document Incidence Matrix.
Term Document Incidence Matrix
It can said as a data structure that allow us to do a specific type of search from the data. It uses a Boolean Retrieval Model to bind the terms with the boolean operators.
For understanding the concept of Term Document Incidence, consider the following image. It contains the Corpus of three documents with document ID. We have done the tokenization of the words to create a array like structure.
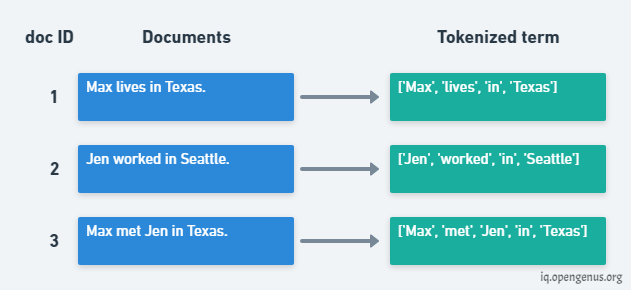
After tokenizing the documents we create the Term Document Matrix, where rows denoted the unique terms from all the documents and columns denote the documents (doc ID).
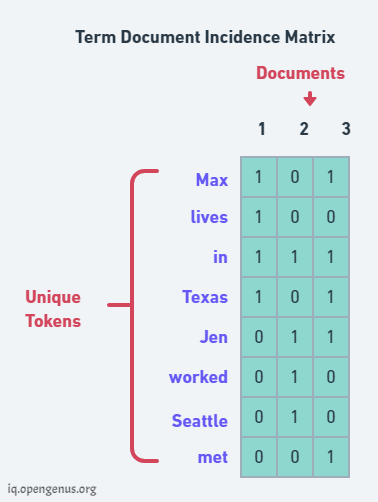
To fill up the matrix we put 0 or 1 for each one of the cell depending on whether or not a particular term occurs in a document. Like "lives" occur in first document but not in second and third.
Now, we can use this matrix for the Boolean Retrieval. Let's say we want to search for the documents that contain the terms "Texas" and "Jen".
We take the vector of the term "Texas" and "Jen" from the Document Matrix. Then do the Bitwise AND to get the vector denoting which documents contain these terms.
Boolean Retreival for Query
Texas AND Jen
Texas --> 1 0 1
Jen --> 0 1 1
_______
0 0 1
The resultant vector [0, 0, 1] represent that the term "Texas" and "Jen" both are present in the third document.
You can see how relatively simple is it to construct these Boolean Retrieval queries once we have indexed our data in this Term Incidence Matrix structure but this limitation does have some limitations.
Lets see how this structure grow with the size and unique terms of the documents.
Estimate that average word in English is 7 characters long and in UTF-8 it occupies 7 bytes/word and each page of a document contain around 250 words/document. Now lets say we want to store 1 million(10^6) pages of document. Therefore, we need 7 × 250 × 10^6 bytes = 15 × 10^8 bytes= 1.75 GB to store that data.
Now to index that data in a Term Document Incidence Matrix. Lets take that set of unique words in English language is anywhere around 3,00,000 and we have to index 1 million(10^6) document. So to store this matrix we need 3 × 10^5 × 10^6 bits= 3 × 10^11 bits= 37 GB.
37 GBs just to store 1's and 0's.
As Term Document Matrix stores 1 if a unique word is there in a document so the matrix will be a Sparse Matrix.
We can calculate the percentage of 1's in the Term Document Matrix by:
Possible 1's in Document= 250 × 10^6
Possible values (matrix size)= 3 × 10^11
Percentage of possible 1's= (25× 10^7 / 3× 10^11)×100= 0.08%, which is extremely low and not of use to store such a sparse matrix which consume 37 GB of size.
Inverted Index
We saw in Boolean Retrieval of Term Document Matrix that size of it grows very quickly and occupying a large amount of memory and it could be a bad mechanism for searching purpose. And the matrix is storing more than 99% of the storage to just denote a particular term doesn't occur in a document (sparse matrix).
For understanding the concept of Inverted Index lets consider the same corpus as of Term Document Matrix and to tokenize the terms of the document.
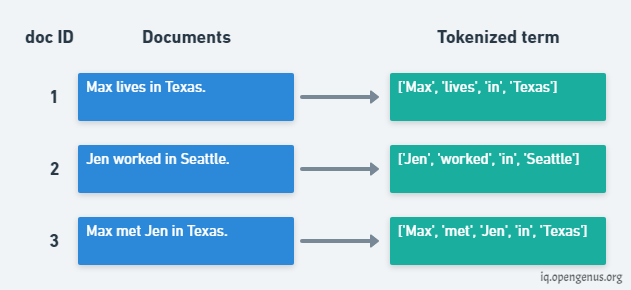
In Inverse Matrix we take in account all the tokenized terms if they are duplicate also. Then we create a vector where each cell contain the document ID in which a term is present it is acting like a pointer to store the document ID in which the term exist.
Next step is to sort the list of terms alphabetically and maintaining the pointer to their particular document ID. This step is essential to make a posting list in next step.
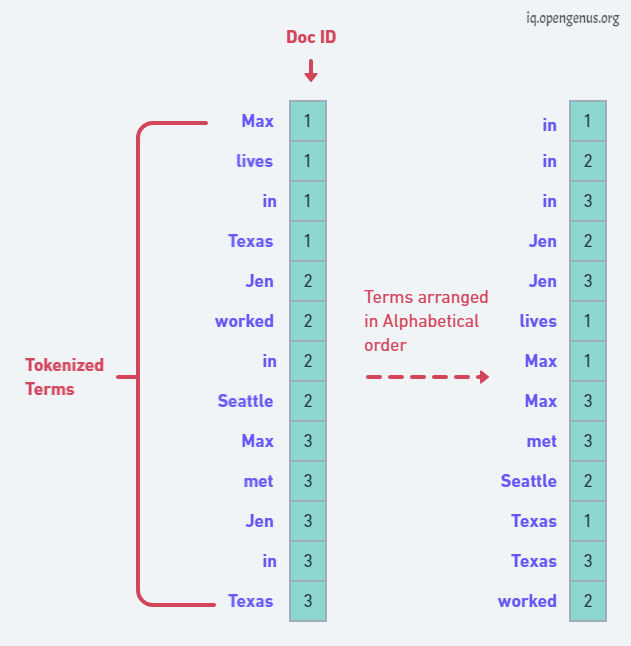
Here we will create our Inverted Index structure. We're going to group by term and then point that grouped term to an array-like structure containing all of the document IDs that grouped term occurs in.
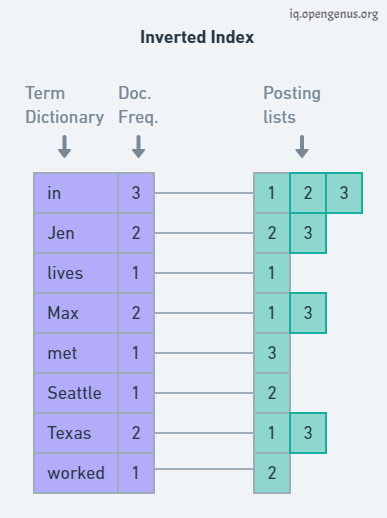
Each of the array-like structure corresponding to a term is the posting list and each tokenized word is a token in our dictionary. And with the dictionary a document frequency is associated to store the frequency of each word from all the dictionaries.
You can notice that Inverted Matrix is somewhat similar to Term Document Matrix except now Inverted Matrix is now only storing documents in which a particular term occurs which is better to a sparse matrix of 1's and 0's.
Boolean Queries
For information retrieval in Inverse Index we use the vectors of the terms that we are looking for and use the pointers for searching the terms that the user need according to the query.
Jen OR met

For query terms related to Jen, met we took there vectors from Inverse Index.
We look at the first and second pointers and here it is at 2, 3. We look at pointer at lowest value and increment it, it is now pointing to 3 but we not include it again as 3 is already in result set. Now both pointers reach to the end of the posting list array.
Therefore, document 2 and 3 contains the term Jen or met.
Jen AND met
Here, Document Frequency is found to be useful for the query optimization because an AND boolean like this is going to be the size of the smallest posting list.
We are going to start with the pointer that is pointing to the smallest pointing list, here second pointer that is pointing to the "met" and pointing to document 3 and then we can move our first pointer until we see a 3 and once we do we can put 3 in result set. Then we could increment the smallest postings list pointer and we see that we're at the end of the array.
Therefore, only document 3 contains both the terms of user query.
Dynamic and Distributed Indexing
The above two algorithms that we just discussed were on Static Collections, we are assuming that our corpus is static it's not dynamically changing and moreover we also assumed here that data fits into the hard disk of a single machine.
Now we went with a more general case where your data is larger than what can fit into main memory, here we are going to see is that the whole document data is not even going to fit into the hard disk of a single machine so the total data will need to be stored across multiple machines.
Distributed Indexing
All the Web Search Engines does the distributed indexing. The amount of data that they have to create an index on cannot fit into the disk of a single machine so what they do is instead of working with a single machine they work with an entire cluster of machines and the task of indexing is distributed across the different nodes of that cluster so each individual machine in the cluster is called a node. Every individual machine in the cluster is fault prone so it's possible that individual machines could either fail completely or slow down so we need to be able to reassign the tasks that are assigned to that machine to some other machine so that the cluster as a whole is able to build the index for the data.
Web search engines use a cluster, they contain normal machines making up a huge cluster of machines and this cluster is stored in a facility called a Data Center so a data center can be a huge warehouse for storing indexing of data. For example, Google's data centers are estimated to have about a million of such machines and each machine having on an average three cores or three processors so there are about 3 million processors working on building the web search index. If you make a query to Google for example your query is not necessarily going to come to Mountain View where the headquarters of Google is placed, it could be sent to a the nearest Data center.
Dynamic Indexing
Up till now we have assumed that our collection of documents is static right so we are not assuming that the corpus is dynamically changing but if you look at web search engines the web corpus is not a static corpus it's continuously changing, there are documents that are being added to the web all the time, there are documents that are being modified, there are documents that are being deleted. The modifications and deletions were immediately reflected in the inverted index and if we had to immediately reflect them in the inverted index then we would need to add terms to the postings list and perhaps to the dictionary also.
Approach for Dynamic Indexing
- Maintain a "big" index or the main index.
- New documents that are appearing in the corpus will go into a "small" auxilary index.
- Search across both (big and small) index using merge operation.
- Deletion process for a term:
-
- Using Invalidation bit-vector for deleted documents.
-
- Filter documents on a search result by this validation bit-vector.
- Periodically, re-index into one main index.
By comparing the GREP, Term Document Matrix and Inverse Index we can conclude that Inverse Index when combined with Distributed and Dynamic Indexing can be taken as the superior way for Information retrieval.
References/ Further learning:
- Information Retrieval System Playlist by MentorsnetOrg