
Reading time: 30 minutes
MLIR (Multi-level intermediate representation) is an intermediate representation (IR) system between a language (like C) or library (like TensorFlow) and the compiler backend (like LLVM). It allows code reuse between different compiler stack of different languages and other performance and usability benefits.
MLIR is being developed by Google as an open-source project primarily to improve the support of TensorFlow on different backends but can be used for any language in general.
Background
To understand where MLIR fits, we need a brief overview of the compiler infrastructure of common languages like C, Java and Swift and move on to the compiler infrastructure for TensorFlow. With this, the idea of MLIR's position and deliverables will be clear.
Following is the current compiler architecture situation:
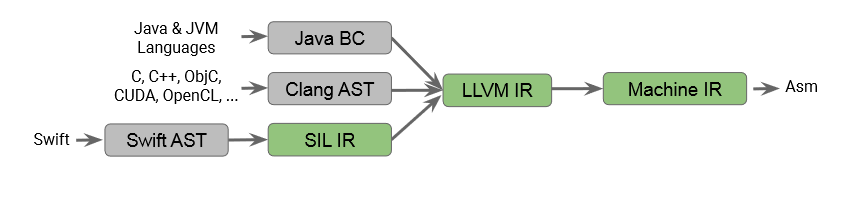
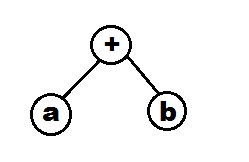
It started with the compiler infrastructure for C. The C compiler takes in a C code and converts it into an Abstract Syntax Tree (AST) which is converted to LLVM IR. AST is a tree data structure where nodes denotes code components like operations and leaf nodes denote data. For example, the abstract syntax tree for a code statement like a+b will be as follows:
Following this, the abstract syntax tree is converted to LLVM IR (intermediate representation). LLVM is a compiler infrastructure that converts LLVM IR to machine code. LLVM is a commonly used tool and forms a part of most popular languages like C, C++, JAVA, Swift and many others.
So, the flow of C code is as follows:
- C code converted to Clang AST by C compiler like GCC
- Clang AST converted to LLVM IR by C compiler like GCC
- LLVM IR converted to machine code by LLVM
There are some problems with this compilation strategy of C like:
- In AST, the information of linking code statements to code line numbers or source code is lost as AST cannot stored such an information. This results in errors which cannot be pointed to source code. A common example is that when segmentation fault occurs, the error message does not say which line in the source code is causing this problem.
- As C code is directly converted to AST, language specific optimizations do not take place. In fact, if a C library is developed, library specific optimization during compiler time cannot take place in this flow.
Other languages like Java and Swift took different paths to resolve this issue.
Java was the first language to tackle this problem and successfully solve it. Java's approach was to convert Java code to Java Byte Code (JavaBC) which is an internall representation of Java. It is in this representation that Java specific and library specific optimizations take place. Following this, Java BC is converted to LLVM IR which is converted to Machine code by LLVM. So, Java's approach was to avoid creating AST which is a generalized representation of any program and hence, created their own format which not only solved C's problem but also made Java the first platform independent language.
A problem with Java's approach was that it became very complex and required deep knowledge of LLVM to take its full advantage. This took the existing resources to its ultimate level to get the best optimizations.
It was a problem for other languages to replicate Java's technique so later, Swift came up with its own approach which became widely adopted.
Swift code is converted into AST with Swift specific representation which is converted to Swift's internal representation. It is at this point where all language specific optimizations are done. Following this, Swift IR is converted to LLVM IR which is taken by LLVM and converted to Machine code.
This was a relatively easy approach and solved all C's original problem. Functionally, it is same as Java's approach. Swift's approach became wildly popular and was adapted into new languages like Rust.
The major problem at this point is that whenever a new language is created, all optimizations such as program flow optimization, data structure optimization and others (which are already done by previous languages) have to be done again. The only layer that differs is the language specific optimizations. Machine level optimizations are taken care by LLVM. So, the entire pipeline has to be created again for each language.
If we see carefully, languages differ only in operation abstraction and internal language specific optimizations. To aid the creation of new languages and libraries, the Google TensorFlow team decided to create MLIR (Multilevel Intermediate Representation).
Actually, the problem was faced in TensorFlow and instead of solving it specificially for TF, Google decided to fix the compiler infrastructure once and for all.
Compiler infrastructure of TensorFlow:
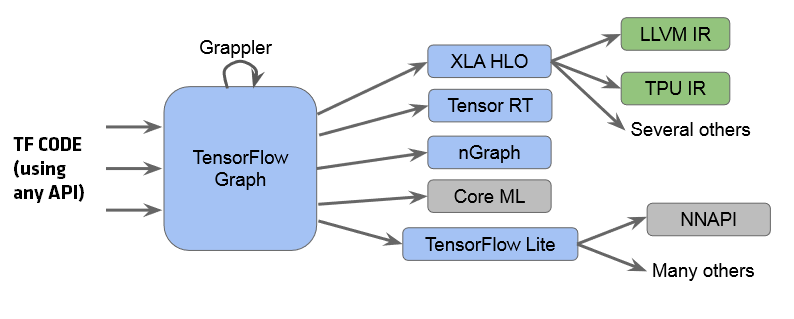
The flow is as follows:
- We can will TensorFlow code using one of its APIs like C++ or Python
- The TensorFlow code is converted into TF graph where Gappler (a module in TensorFlow) does graph level optimizations which includes several Machine Learning specific optimizations like operator merging.
- Following this, the TF graph is converted into one of its many internal representation (IR) for one of its backends (alternative to LLVM).
- TensorFlow has many backends like XLA (for TPU), TF Lite (for mobile devices) and others
The problem is that for each path (like XLA and TF Lite), developers have to reimplement all optimizations and most of the optimizations are common but code reuse is not possible. This problem will be solved with MLIR.
Hence, the flow of MLIR is captured by this diagram:
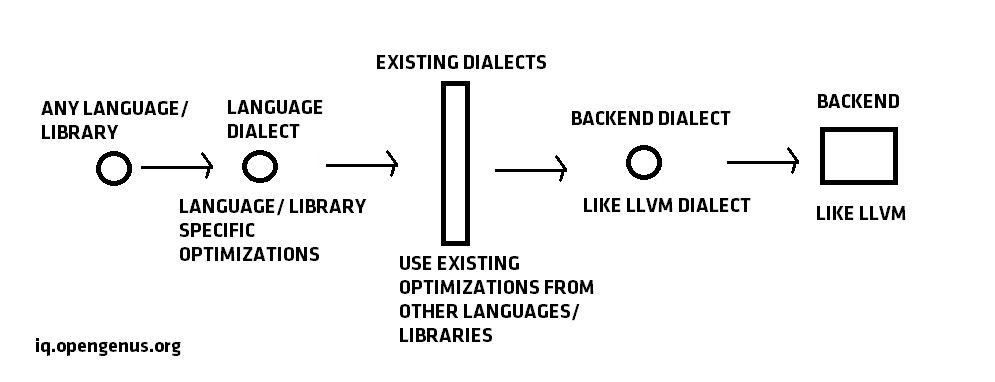
Summary:
- same compiler infrastructure for different languages, no reuse
- similar to compiler infrastructure in Swift and other languages
- tensorflow has support for a lot of backends with different IRs with no code reuse
- aim is to increase code reuse to quickly adapt to new hardware backends
- Intermediate IR to capture data flow information and apply optimizations, better source code tracking than LLVM, flexible design, Reuse LLVM for Machine code generation
Advantage of using MLIR
Following are the advantages of using MLIR:
- Source code location tracking by default
- All functions run on multiple cores by default (uses OpenMP)
- Better code reuse for compiler stack (for new library and hardware) and hence, optimizations done by other languages can be reused
- Better compiler stack for C by developing CIL IR
- For TensorFlow, optimizations in one path can be reused in other paths and hence, massive code reuse.
Internal Key ideas
Key ideas in MLIR are:
- there is no predefined types or instructions. This allows developers to define their own datatypes and instruction abstraction
- no predefined operations
- elementary object in MLIR is a dialect which can be thought of a class from an implementation point of view
- need to define dialects which point to C++ code, dialects are like classes of a custom language
- dialect has 3 parts: function name, list of input parameters, list of output parameters
- for each dialect, default functions like type checking, mapping to LLVM IR
- MLIR has default support for linear algebra operations like type checking between dialects
- a language is converted to a form with dialects
- on this form (set of dialects), optimizations are performed
- after various levels of lowering, dialects can be coverted to LLVM IR directly
- better use of OpenMP as in MLIR all information is available
- all functions run on all cores by default (better system use)
- (better than LLVM) Each operand has a source code memory address attribute so errors directly point to the line of source code in which error occured
- It will use XLA infrastructure for performance analysis and profiling.
Applications
MLIR will be used to improve TensorFlow compiler infrastructure:
- Improve generation of TF Lite with source code tracking
The compilation flow will be as follows:
- TF code
- mlir dialect
- validate/ optimize
- tf lite dialect for tf lite backend
- Change path to XLA HLO using MLIR
The compilation flow will be as follows:
- tf
- tf dialiect
- validate/ optimize
- xla dialect
- xla backend
It will reuse some of the components from TF Lite path
- Using MLIR to support new compiler backends
When a new platform P comes in and it has a new backend B, then to convert TensorFlow code is converted to an existing dialect/ IR by using the existing code for TF Lite and XLA. Following it, we need to code a new dialect set/ IR (with custom optimization for the platform) and conversion code for convert it to the IR needed by the platform's backend compiler.
The use of MLIR makes the process more manageable and fast.
Other applications
MLIR, being a general tool, can use used for other purposes such as:
- Fixing the problems with C and C++ code by inserting a new IR through MLIR
- New languages can directly use the optimizations of existing languages that use MLIR and hence, developing new languages will be easy and quick.
- Innovation in compilation technology by one group can be easily used by multiple groups once implemented using MLIR's system
In short, LLVM has greatly innovated the compiler ecosystem but now MLIR has brought in the next phase by enabling easier and more efficient compiler ecosystem by leveraging the best parts of LLVM.