
Get this book -> Problems on Array: For Interviews and Competitive Programming
Introduction
Multi Layer Perceptron (MLP) is a type of artificial neural network that is widely used for various machine learning tasks such as classification and regression. It is called a multi-layered perceptron because it has many layers of nodes (known as artificial neurons) that connect to each other. In this article, we will explore the main features and components of MLP, its architectural and training processes, and its programs in various fields.
History
MLP was first introduced in the late 1950s and early 1960s as a way to train computers to perform pattern recognition tasks. In the decades that followed, MLP was largely overshadowed by other neural network models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). However, in recent years, MLP has seen a resurgence of interest due to its simplicity, versatility, and effectiveness in solving a variety of complex problems.
Architecture of MLP
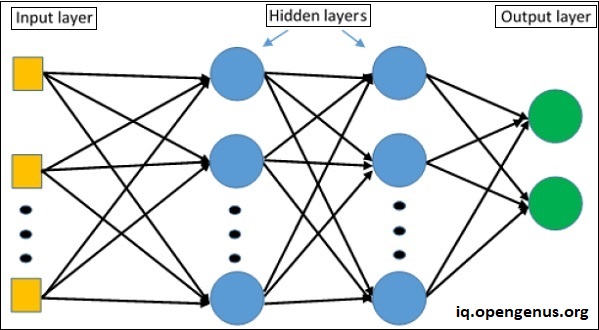
The architecture of an MLP consists of three key components: the input layer, hidden layer(s), and output layer.
-
Input Layer: The input layer receives the input data and passes it to the hidden layer(s). It consists of nodes, each of which corresponds to a feature in the input data. The number of nodes in the input layer is equal to the number of features in the input data.
-
Hidden Layer(s): The hidden layer(s) are responsible for transforming the input data into a suitable representation for the output layer. They consist of nodes, which are connected to the input layer and other hidden layer(s) through weights and biases. The number of hidden layer(s) and the number of nodes in each layer can be adjusted to optimize performance for a specific task. Common activation functions used in hidden layers include sigmoid, tanh, and rectified linear unit (ReLU).
-
Output Layer: The output layer receives the transformed representation of the input data from the hidden layer(s) and generates the final output. It consists of nodes, each of which corresponds to a class or a continuous value, depending on the task. The output layer uses a specific activation function that is appropriate for the task, such as softmax for classification and linear for regression.
It is important to note that the weights and biases in the MLP are learned during the training process, where the network adjusts its parameters to minimize the error between its predictions and the actual outputs. The training process involves passing the input data through the network, computing the error, and then updating the weights and biases to reduce the error. This process is repeated multiple times until the error is sufficiently low.
Overall, the architecture of MLP plays a crucial role in its ability to solve complex problems. By having multiple hidden layers and nodes, MLP can learn complex non-linear relationships between the input and output data. The number of hidden layer(s) and the number of nodes in each layer, as well as the choice of activation functions, can be adjusted to improve performance for specific tasks.
Training process of MLP
The goal of MLP training is to find the optimal values of weights and biases that minimize the error between the network's predictions and the actual outputs. This is done using a supervised learning algorithm, such as backpropagation, and an optimization method, such as gradient descent.
Backpropagation works by computing the gradient of the error with respect to the network's weights and biases, and using this gradient information to update the weights and biases in the direction that reduces the error. This process is repeated for multiple iterations, until the error reaches a minimum or a stopping criteria is met.
During training, it is important to avoid overfitting, which is when the network becomes too complex and fits the training data too well, at the expense of poor generalization to unseen data. One common technique to prevent overfitting is regularization, which adds a penalty term to the error function that discourages the network from having too many weights and biases.
A Simple Implementation in Python
import numpy as np
from sklearn.neural_network import MLPClassifier
# Load the dataset
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
# Initialize the MLP classifier
clf = MLPClassifier(hidden_layer_sizes=(2,), activation='tanh', solver='lbfgs')
# Fit the classifier to the data
clf.fit(X, y)
# Make predictions on a new sample
sample = np.array([[1, 1]])
prediction = clf.predict(sample)
print("Prediction:", prediction)
Applications of MLP
MLP is widely used in various fields, including computer vision, speech recognition, natural language processing, and finance. Some examples of MLP applications include:
- Image classification: MLP can be used to classify images into different categories, such as animals, objects, and scenes.
- Speech recognition: MLP can be used to transcribe spoken words into written text, and to identify the speaker's accent, language, and emotional state.
- Stock price prediction: MLP can be used to forecast the future stock prices based on historical data and market trends.
- Anomaly detection: MLP can be used to identify unusual patterns in data, such as fraud, network intrusion, and sensor failures.
Conclusion
In conclusion, Multi Layer Perceptron (MLP) is a powerful and versatile type of artificial neural network that is widely used for machine learning tasks. Its key components include the input layer, hidden layer(s), output layer, nodes, activation functions, weights, and biases. MLP is trained using supervised learning algorithms and optimization methods, such as backpropagation and gradient descent, to minimize the error between its predictions and the actual outputs. MLP has many applications in various fields, including computer vision, speech recognition, natural language processing, and finance. Overall, MLP is a valuable tool for solving complex problems and has a rich history and promising future in the field of artificial intelligence.