
Reading time: 25 minutes | Coding time: 10 minutes
In this article, we will use Naive Bayes classifier on IF-IDF vectorized matrix for text classification task. We use the ImDb Movies Reviews Dataset for this. We use Scikit learn library in Python.
Hello friends, once again it's time to sit straight and put your fingers on keyboard, i.e., Coding Time.
But before we start our code demonstration, let's summarize briefly about tf and tf-idf :-
TF - Term Frequency,
-
Term Frequency = count(t, d) i.e., count of term t in document d. -
Normalized term frequency = count(t,d)/Total terms in that document. -
Logarithmic Term Frequency = 1 + log10(count(t,d))
TF -IDF - Term frequency - inverse document frequency, i.e. tf-idf = tf * idf
idf ( t, d ) = log ( D / { d ∈ D : t ∈ d })
where idf is the inverse document frequency function
- t is the term/ word
- d is the document
- D is the total number of documents
- { d ∈ D : t ∈ d } denotes the number of documents in which t occur
- tf is already described above.
This results in:
tf-idf = tf * idf
We generally use normalized term frequency in the tf-idf formula.
Demonstration
Let's begin our code demonstration, procedure followed is given as : -
- Choose a dataset based on text classification. Here, we use ImDb Movie Reviews Dataset.
- Apply TF Vectorizer on train and test data.
- Create a Naive Bayes Model, fit tf-vectorized matrix of train data.
- Predict accuracy on test data and generate a classification report.
- Repeat same procedure, but this time apply TF-IDF Vectorizer.
Brief Description about Dataset - The ImDb Movies Reviews Dataset from Kaggle, which contains text file of reviews with labels positive and negative. The file distribution is as follows :
- Train Data - 25000 files/ reviews.
Positive labelled - 12500 reviews.
Negative labelled - 12500 reviews. - Test Data - 25000 files/ reviews.
Positive labelled - 12500 reviews.
Negative labelled - 12500 reviews.
Since, all these reviews are in text files, so first we will generate csv files of train and test data. I am attaching links for:
- Actual ImDb Dataset
- <a href="https://www.kaggle.com/mantri7/imdb-movie-reviews-dataset" target="_blank>Converted ImDb Dataset
- <a href="https://www.kaggle.com/mantri7/creating-data-set-from-imdb-dataset-text-files?scriptVersionId=22385216" target="_blank>Code to generate CSV files
Once, we have dataset, we are all set to code.
1. Importing Libraries
Here, first we need to import libraries, ex. sklearn - to perform naive bayes, performing tf and tf-idf, to calculate accuracy, precision, recall, etc.
from time import time
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
2. Loading Data from csv files
In our dataset(csv files), 0th indexed column represents the text reviews and 1st indexed column represents sentiment of the review(if labelled '0' that means negative and if labelled '1' that means positive).
test_csv = pd.read_csv('../input/imdb-movie-reviews-dataset/test_data (1).csv') # path to file
train_csv = pd.read_csv('../input/imdb-movie-reviews-dataset/train_data (1).csv') # path to file
train_X = train_csv['0'] # '0' corresponds to Texts/Reviews
train_y = train_csv['1'] # '1' corresponds to Label (1 - positive and 0 - negative)
test_X = test_csv['0']
test_y = test_csv['1']
3. Applying tf vectorizer (count vectorizer)
Here, we use CountVectorizer (another term of TfVectorizer)
t = time() # not compulsory
# loading CountVectorizer
tf_vectorizer = CountVectorizer() # or term frequency
X_train_tf = tf_vectorizer.fit_transform(train_X)
duration = time() - t
print("Time taken to extract features from training data : %f seconds" % (duration))
print("n_samples: %d, n_features: %d" % X_train_tf.shape)
Output : -
Time taken to extract features from training data : 4.508458 seconds
n_samples: 25000, n_features: 74849
4. Transforming test data into tf-vectorized matrix
In this step, we transform the test data into TF vectorized matrix using tf_vectorizer.transform.
t = time()
X_test_tf = tf_vectorizer.transform(test_X)
duration = time() - t
print("Time taken to extract features from test data : %f seconds" % (duration))
print("n_samples: %d, n_features: %d" % X_test_tf.shape)
Output : -
Time taken to extract features from test data : 4.202561 seconds
n_samples: 25000, n_features: 74849
Here, note one thing, we use fit_transform when we apply count vectorizer on train data, but while applying on test data, we use transform function. Why so???? Think Yourself. I'll answer it at the end of article.
5. Applying Naive Bayes
Training Naive Bayes classifier with train data:
# build naive bayes classification model
t = time()
naive_bayes_classifier = MultinomialNB()
naive_bayes_classifier.fit(X_train_tf, train_y)
training_time = time() - t
print("train time: %0.3fs" % training_time)
Output -
train time: 0.054s
6. Calculating accuracy and generating classification report from test data
Testing our Naive Bayes classifier model with test data -
# predict the new document from the testing dataset
t = time()
y_pred = naive_bayes_classifier.predict(X_test_tf)
test_time = time() - t
print("test time: %0.3fs" % test_time)
# compute the performance measures
score1 = metrics.accuracy_score(test_y, y_pred)
print("accuracy: %0.3f" % score1)
print(metrics.classification_report(test_y, y_pred,
target_names=['Positive', 'Negative']))
print("confusion matrix:")
print(metrics.confusion_matrix(test_y, y_pred))
print('------------------------------')
Output -
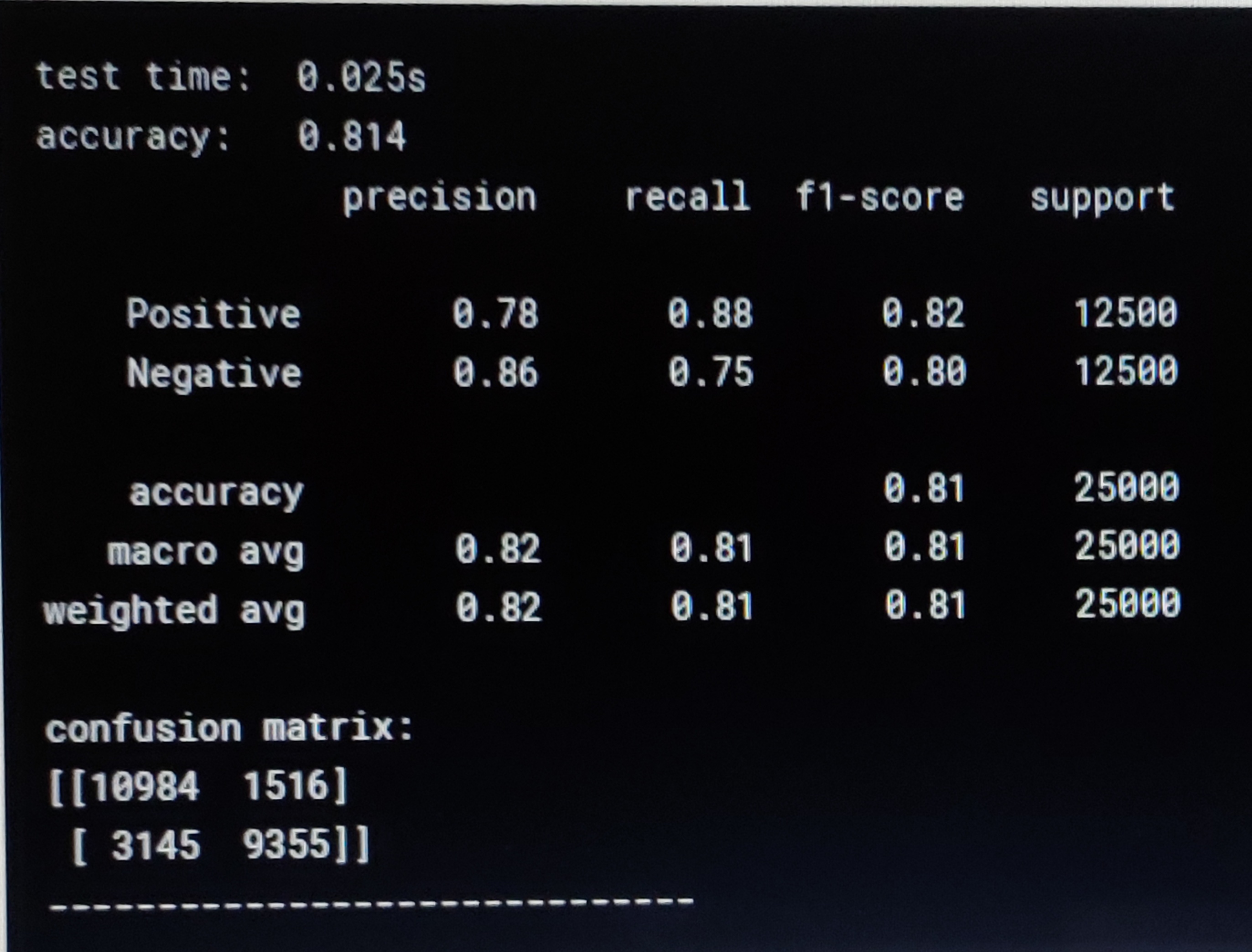
Yeahhhhhh!!!! We got accuracy of 81.4%.
Coming to the question, I asked before -
What is the difference between fit_transform and transform function? Why we use fit_transform on training data and transform on test data?
Answer : -
We want our terms(vocabulary) from training data and then calculate it's term frequency. So, in fit_transform function, fit is to extract all the unique words and transform is to make term frequency matrix of the data for all the unique terms extracted from fit part.
Further steps to try out:
-
Try applying tf-idf vectorizer and see your output.
-
Suggestion - use TfidfVectorizer inplace of CountVectorizer
-
Try preprocessing like removing stop words from documents and then applying tf and tfidf vectorizer. And Compare results.