
Get this book -> Problems on Array: For Interviews and Competitive Programming
This article discusses about one of the commonly used data pre-processing techniques in Feature Engineering that is One Hot Encoding and its use in TensorFlow.
One-Hot Encoding is a frequently used term when dealing with Machine Learning models particularly during the data pre-processing stage. It is one of the approaches used to prepare categorical data.
Table of contents:
- Categorical Variables
- One-Hot Encoding
- Implementing One-Hot encoding in TensorFlow models (tf.one_hot)
Categorical Variables:
A categorical variable or nominal variable is the one that can have two or more categories, but unlike ordinal variables there is no ordering or ranking given to the categories, or simply we cannot order them in a known or clear way.
For e.g:
- The color of a ball would fall into the categories like "Red", "Green", "Blue" or "Yellow".
- The breed of a dog would have categories like "German Sheperd", "Beagle", "
Siberian Husky" or "Shiba Inu"
One-Hot Encoding:
What is it?
One-hot encoding replaces categorical variables with binary variables (or to be more specific as vectors), which take a value of 0 or 1. Basically, we're indicating whether a certain item of a particular category was present or not. This is done by creating new rows for each entry in the data and columns representing their categories. Their presence or absence is marked with 1s and 0s.
Let us consider an example,
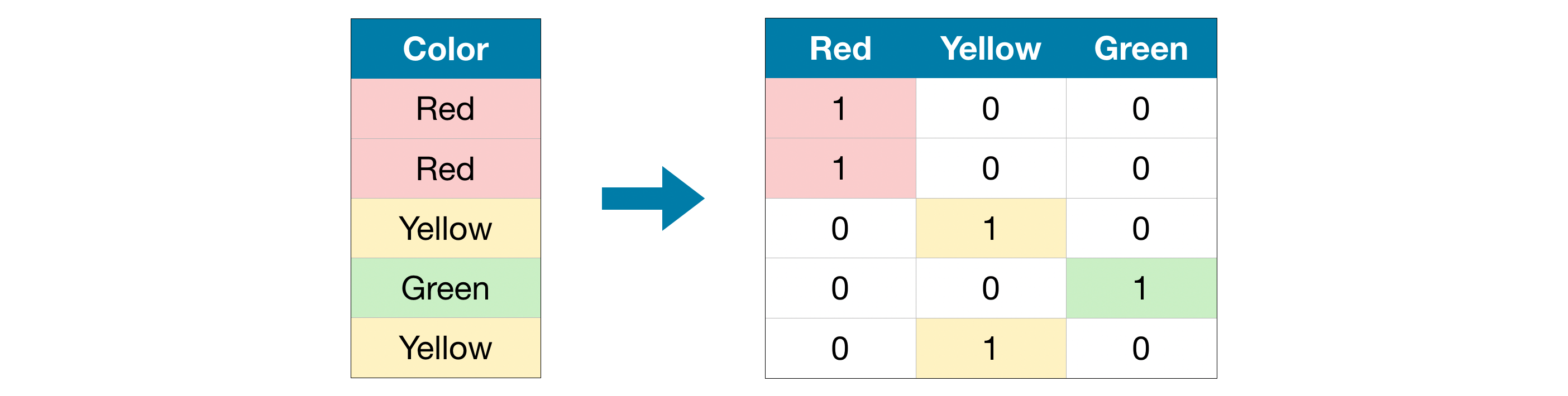
Here we've 5 entries in our data, so we've 5 binary variables and 3 columns for the category labels. As mentioned previously, this encoding does not assume any ordering of the categories. So this would work well there is no clear ordering in the given categorical data.
Why One-Hot encoding is required?
We cannot plug these variables directly to our models as most of the machine learning models require all variables, both input and output to be in a numeric form.
But it is surprising to note that Decision trees and it's derivatives, including regression trees and tree ensembles like random forests are robust to categorical variables that are not processed. We can understand this by building an intuition from it's view that each node in the tree has one child node per value that its variable can take and thus treats all variables like categorical variables.
Before going further, we might have a question that why label encoding or ordinal encoding isn't simply sufficient?
The problem with ordinal encoding is that it assumes higher the value, better the category is. Suppose if we had another color in the category, it would be assigned a higher value i.e 4. So categorical values proportionally increase with the number of unique entries. Thus, higher numbers are given higher weights (importance)
For instance, if "Red" is 1, "Yellow" is 2 and "Green" is 3 and our model calculates the average across the categories, it would do it as 1+3/2 = 2 and the model would infer it as the average of "Red" and "Green" is "Yellow". This will eventually lead to our model picking up completely wrong co-relations or patterns.
One thing to keep in mind is that One-hot encoding doesn't perform well if the categorical variable is taking up a large number of values, say such as 15 different values.
Implementing One-Hot encoding in TensorFlow models (tf.one_hot):
tf.one_hot operation:
We’ll have to first create a Neural Network layer that will use this tf.one_hot operation in order to include the One Hot Encoding as a data pre-processing with the actual training model
tf.one_hot(
indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None
)
These are the parameters that can be passed:
indices: An input Tensor of indices.
depth: A scalar defining the depth (no. of categories) of the one hot dimension.
on_value: A scalar defining the value to fill in output when indices[j] = i. (default : 1)
off_value: A scalar defining the value to fill in output when indices[j] != i. (default : 0)
axis: The axis to fill (default : -1, a new inner-most axis).
dtype: The data type of the output tensor.
name: An optional name for the operation
tf.one_hot accepts a list of category indices and depth which is essentially the number of unique categories and also the number of columns in the resulting tensors.
As an example, we try out tf.one_hot operation on an input of indices
import numpy as np
import tensorflow as tf
indices = [0,1,1,2,3,0,3]
cat_count = 4 #depth or the number of categories
input = tf.one_hot(indices, cat_count) #apply one-hot encoding
print(input.numpy())
>>>
[[1. 0. 0. 0.] <- binary variable 0
[0. 1. 0. 0.] <- binary variable 1
[0. 1. 0. 0.] <- binary variable 2
[0. 0. 1. 0.] <- binary variable 3
[0. 0. 0. 1.] <- binary variable 4
[1. 0. 0. 0.] <- binary variable 5
[0. 0. 0. 1.]] <- binary variable 6
The output of this operation is a list of binary tensors with one-hot encoded values.
As we can see, it is quite inconvenient that we cannot directly pass input as a string of categories, as it only accepts indices. So, for this we'll have to create a custom layer that'll convert strings into integer indexes in a consistent way, i.e a particular category should always get the same index.
We'll use the technique of Text Vectorization to do this conversion. We've to introduce a new TextVectorization layer with the help of the layers module from keras that'll tokenize sequences of text. output_sequence_length=1 is set because we are assigning a single integer index for each category we're passing. Using the adapt() method we'll fit this on to the dataset.
import pandas as pd
from tensorflow.keras import layers
df = pd.DataFrame(data=[['red'],['green'],['green'],['blue'],['yellow'],['red'],['yellow']])
text_vectorization = layers.experimental.preprocessing.TextVectorization(output_sequence_length=1)
text_vectorization.adapt(df.values)
#print the index of color 'Red'
text_vectorization.call([['red']])
After the fitting has been done an internal vocabulary is created that stores the mapping created between the words and indices. You can view this vocabulary using get_vocabulary() method.
print(text_vectorization.get_vocabulary())
This is how we can manually use the Text Vectorization method to convert category strings to integer indexes.
Additionally, as a bonus a One Hot Encoder Layer Class can also be created that can be used to instantly create an instance of One Hot Encoding layer whenever it is required.
It accepts a categorical input, then One Hot will encode it. The above class example also provides an option to export the config as a JSON file, so it can deployed or reloaded into memory.
With this article at OpenGenus, you must have a strong idea of One Hot encoding in TensorFlow (tf.one_hot).