
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Natural Language Processing (NLP) refers to a branch of Artificial Intelligence (AI) in Computer Science that gives computers the ability to analyze and interpret human language. The ultimate goal of NLP is to train the computer to reach a human-level understanding by combining computational linguistics, statistical, machine learning and deep learning models. Practical usage of NLP models includes speech recognition, part of speech tagging, sentiment analysis and natural language generation.
👶 What makes a basic NLP model?
Before we dive into cutting-edge NLP models, it is easier for us to understand them further along the road if we know the basics. In a nutshell, most of the NLP models utilize deep learning to get the job done. Before then, NLP practitioners implemented classical linguistic methods or classical statistical means to yield results. These methods tend to work fairly well with narrow cases but they proved to be fragile since the analytical methods are hand-crafted by experts with rigid rules. The manifestation of deep learning changed the whole NLP field[1]. You may read more about deep learning NLP implementation here.
To make a basic NLP model, one has to do through following steps:
- Data Cleaning and tokenization: It cleans the sequenced words by operations like removing stop words, lower the case, reduce words into a single form. Aiming to commonize words with the same meaning but slightly different representations and unify them for easier grouping. Words are then split into phrases or even smaller units.
- Vectorization / Word Embedding: Computers do not process strings, but numbers. After cleaning the data, one must map or label individual strings into real numbers which makes the ideal input for computers to process as an input.
- Model training: Normal NLP models are done through deep learning, specifically Recurrent Neural Network (RNN) and Long Short Term Memory (LSTM) network. RNN is basically a specially designed deep learning Artificial Neural Network (ANN) with recurrent connection on the hidden state that ensures sequential information is captured. It is especially crucial given that understanding human languages involves capturing sequential information presented in the input data, i.e. dependency between words in the text while making predictions. During RNN constructions, information of a node is passed back to immediate previous nodes unlike only forwarding it in ANN[2].
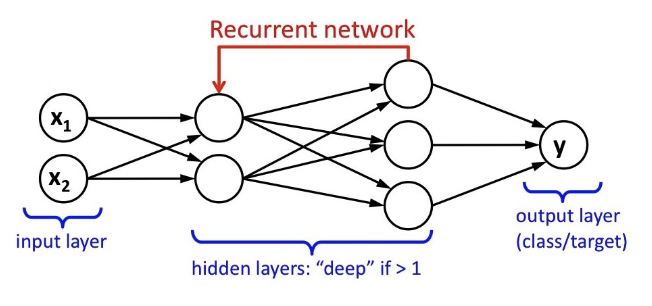
LSTM network, on the other hand, extends the feedback concept of RNN in which the information is not only passed to neighboring previous nodes but it is shared across the whole network[2]. LSTM approach enables the network to remember input information for a longer period of time, which is somehow essential for understanding human languages. You may read more about the introduction of RNN and LSTM networks here.
🆎 Type of NLP
Now with the basics taken care of, let us explore the most popular and up-to-date NLP models:
- BERT
- GPT-3
- XLNet
- ALBERT
- RoBERTa
🧮 BERT
BERT stands for Bidirectional Encoder Representations from Transformers, ad it is developed and pre-trained by Google in 2018 on over 2500 million internet words and 800 million words of Book Corpus.
🛠️ How does it work?
BERT is an open-source machine learning framework and as the name suggests, reads the text in both directions at once and analyzes the language using a large repository of specialized labelled training data. The trained data comes from a pre-trained RNN that uses unlabelled plain text corpus, therefore from unsupervised machine learning without an expert labelling the desired output of a sentence or a paragraph. That is why BERT can improve its accuracy even as it is deployed in practical applications like Google Search.
Moreover, the pre-trained model serves as a base layer of knowledge to build from, which can adapt to the specific user's specifications and continue training. This process is known as transfer learning. It makes the BERT NLP model differ between each google user account. Pre-training and fine-tuning are the two key processes in BERT.
BERT, in a nutshell, works by constructing a deep learning model with a transformer. The transformer is part of the RNN model that increases model capacity for understanding context and ambiguity in language and it works by processing any given words in relation to all other words in a sentence rather than processing them one at a time. The transformer allows the BERT model to understand the full context of work and therefore the intent of the input better.
BERT is the basis of other more advanced NLP models such as XLNet, RoBERTa and ALBERT.
⚙️ Applications of BERT:
Sequence-to-sequence-based language generation tasks such as:
- Question answering
- Abstract summarization
- Sentence prediction
- Conversational response generation
Natural language understanding tasks such as:
- Polysemy and Coreference (words that sound or look the same but have different meanings) resolution
- Word sense disambiguation
- Natural language inference
- Sentiment classification
🧮 GPT-3
GPT stands for Generative Pre-Trainer. While some of the advanced NLP models are built on top of BERT, GPT-3, a model created by OpenAI, is the newest design along with the GPT series. Previous GPT models include GPT and GPT-2.
🛠️ How does it work and how does it differ from BERT?
Sheer size: Like BERT, GPT-3 is also a large-scale transformer-based language model which is trained on 175 billion parameters. The sheer model size of GPT-3 crushed BERT-like models by around 470 times. In fact, it was trained with almost all available data from the Internet.
Fully unsupervised and does not require fine-tuning: Except for the size of the model, while BERT requires an elaborated fine-tuning process where the model gathers user-specific input data for transfer learning, GPT-3’s text-in and text-out API allows the users to reprogram it using instructions and access it. From the start, it uses unsupervised learning as a base just like BERT, but it does not require a massive amount of transfer learning by fine-tuning the model to suit an individual's need. It simply needs a pre-trained model combining a few examples and it was enough to obliterate any competitor in some specific tasks (better than BERT). It is also not quite possible to tune since the model is provided by OpenAI through API.
Transformers: It used transformers as a basis for analysis and was also trained on astronomically large amounts of text from CommonCrawl, WebText, Wikipedia and a corpus of books.
Multitask learning: GPT-3 is also a multitask learning model that is able to solve different tasks given input. For instance, when shown the word "cat", it can perform translation, showing an image or return a paragraph of text containing its features. Different tasks for the same input.
Zero/one/few-shot learning: Normal models, when set up to classify a certain amount of classes, can only be tested on those classes. In zero-shot learning set up the system is shown at test time, on classes it has not seen at training time. The same thing for one-shot and few shot settings, but in these cases test time the system sees one or few examples of the new classes.
⚙️ Application of GPT-3:
GPT-3 is generally considered superior in terms of accuracy to BERT and its variants, tasks that can be done by BERT and BERT-like models can be implemented using GPT-3.
🧮 XLNet
XLNet is a BERT-like model instead of a totally different one, and a very promising one. It is a generalized autoregressive (AR) pretraining method of NLP.
But what is AR? It is a method of using context word to predict the next word, by either forward and backward prediction.
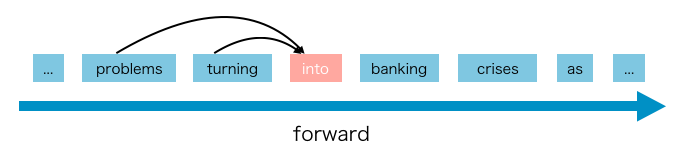
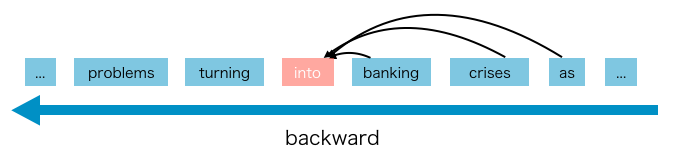
It has the advantage of having high precising with NLP task, but also disadvantaged since both cannot be applied together. AR cannot use forward and backward context at the same time. XLNet model tries to break this limitation.
🛠️ How does XLNet work?
The idea behind XLNet is to keep using forward and backward traversal using the AR model? It focuses on using permutation, and specifically proposed a new objective called Permutation Language Modelling to solve such a problem.
As per the name of the permutation, given a list of words [a, b, c, d], the permutation yields 24 nos. distinct options. Assume n nos. of elements in a list, there would be n! nos. of permutations.
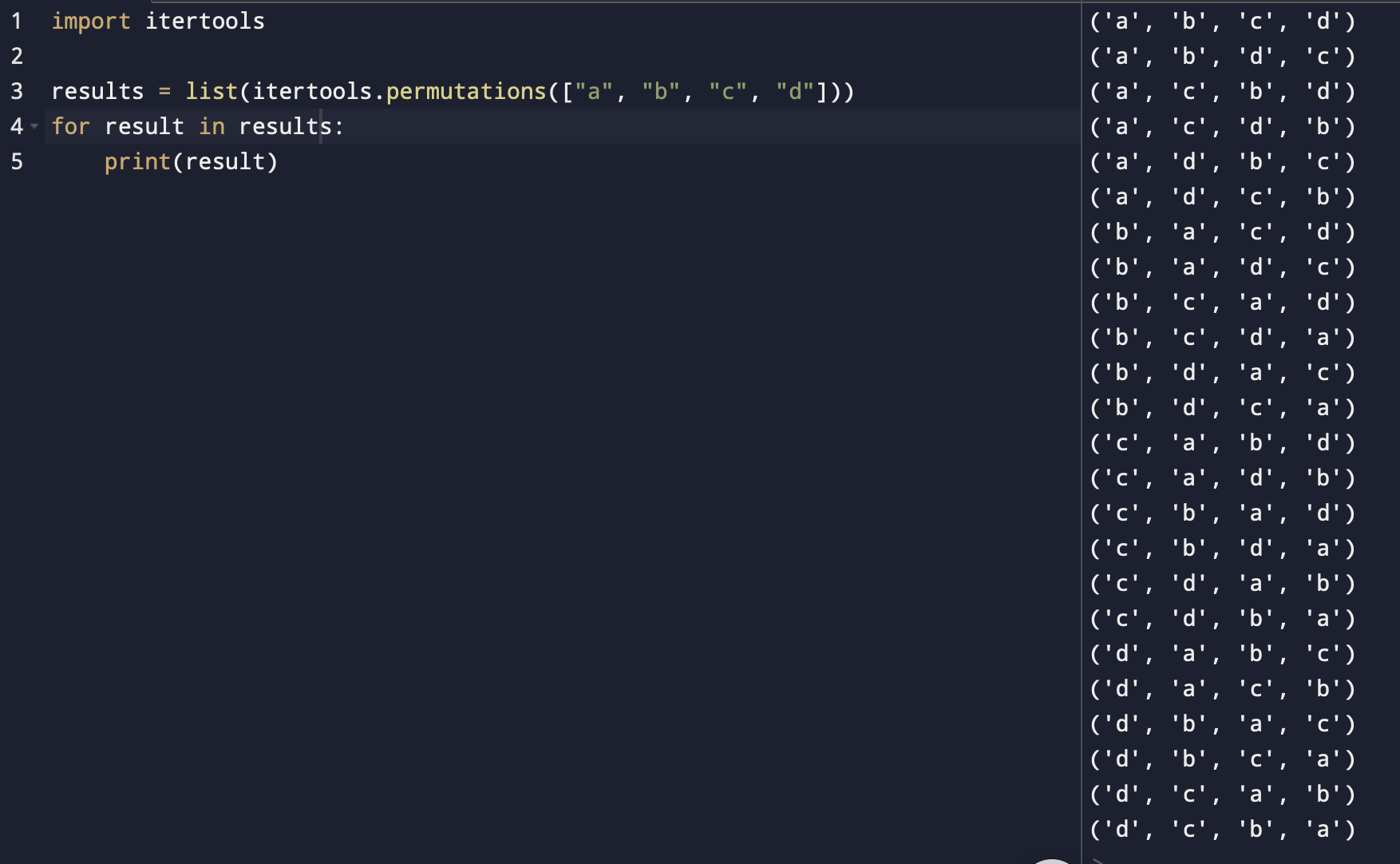
Above shows all permutations. Suppose that we are trying to predict text "c". How can we use such permutations for better prediction? Notice a few examples of list generated:
- [c, xx, xx, xx]
- [xx, c, xx, xx]
- [xx, xx, c, xx]
- [xx, xx, xx, c]
Assume only forward If we are trying to map and predict "c", we can use one of the layouts from 1, 2, 3 or 4. If the permutation is one of the choice 1, it will make a blind guess since there is no word prior to "c". If it is case 2, there would be 1 token provided for matching. In general, if "c" is at nth space, there would be n-1 nos. of tokens available for training.
Since permutation gives a total of n! and we evaluate our target (in this case "c") at the nth position with all n-1 nos. of tokens, the model is essential to learn to gather information from all positions on both sides, thus combining forward and backward context to train and mask the target word in case of autofill.
🧮 ALBERT
As above described for BERT, ALBERT is a Google proposed NLP model that is based upon BERT architecture. ALBERT stands for A Lite BERT (for self-supervised learning of language representations). It differs from the basic model by three main changes which would be described in the coming section.
🛠️ How does ALBERT work?
ALBERT work based on BERT, but has 3 key differences in model architecture:
-
Factorization of the Embedding matrix
In the BERT model and XLNet, the input layer and hidden layer embedding have the same size but for ALBERT, the model separates the two embedding matrices and thus there are two smaller sizes. This separation results in a reduction in parameters by 80% with a minimal effect on model performance when compared to BERT. -
Cross-layer parameter sharing
It suggests that parameters from different layers of the model can be shared to improve efficiency and decrease redundancy. It leads to an overall 70% reduction in overall parameters. There are serval steps proposed by the author:
- Only share feed forward network parameter
- Only share attention parameters
- Share all parameters. Default setting used by authors unless stated otherwise
- Inter Sentence Coherence Prediction
While BERT uses NSP (Next Sentence Prediction) as the loss function, ALBERT used a new loss called SOP (Sentence Order Prediction). NSP is disadvantaged since it checks for coherence as well as the topic to identify the next sentence but SOP only looks for sentence coherence. The new loss function SOP seems to be a better choice since it deals with the NSP task relatively well and the SOP task even better, thus improving the overall model training precision.
🧮 RoBERTa
It is another model derived from BERT which stands for Robustly Optimized BERT Pre-training Approach. It is presented by researchers from Facebook (now Meta) and Washington University and the goal of the paper was to lessen the time for pre-training of BERT model by optimizing the pre-training phase.
🛠️ How does RoBERTa work?
It is largely based on BERT with three main modifications:
-
Removing the NSP objective: researchers experimented with the NSP loss function, and found out that removing it slightly improves the task performance, thus the RoBERTa model omits it.
-
Training with longer sequences and bigger batch size: Adjustments are made regarding the BERT model's training batch size. The author of the paper trained the model with 125 steps of 2000 sequences and 31000 steps with 8000 sequences of batch size, as opposed to the original BERT's 1 million steps with batch size of 256 sequences. It benefits the result by the perplexity of masked language modeling and end-task accuracy, and a larger batch size is easier to distribute parallel training and thus making it faster to train.
-
Dynamically changing the masking pattern: BERT is performed once during data preprocessing since it is a single static mask, RoBERTa on the other hand, avoids single static mask. It does it by duplicating training data 10 times and thus masking it 10 times, each time with a different masking strategy of over 40 epochs and thus dynamically mask is generated every time the data is passed into the model.
💡 What's next?
The ultimate goal of NLP is the make computers listen, speak and generate human languages. Machines may never achieve human standards since it is humans who set the standard, but models and variants like BERT, GPT-3, XLNet, ALBERT and RoBERTa are closing the gaps at unprecedented paces. The future of NLP is a vastly deep, well-studied and highly anticipated field. The sky is the limit.
📚 References
[1] https://iq.opengenus.org/use-of-deep-learning-in-nlp/
[2] https://iq.opengenus.org/recurrent-neural-networks/