
In this article, we have explored the Wake Sleep Algorithm For Neural Network along with examples of using it and limitations of it.
Table of Contents
- Introduction
- Unsupervised Neural Network
- Wake-Sleep Algorithm
- Training Phases
- Example of Wake-Sleep Algorithm
- Limitations
Introduction
Machine learning is a process that allows machines to complete complex and lengthy tasks without any human interaction. Machines are trained on a set of data using specific methods or algorithms to conduct certain types of tasks.
Deep learning is a subfield of machine learning. It uses neural networks to imitate the function of the human brain. The neural networks receive inputs, process them, and produce a certain output. The processing takes place in a layered structure of the neural networks, which is called the hidden layer.
There are two main learning approaches for training machine neural networks,
Supervised Learning: This approach has labeled data. It means the output is included with the input. The machine learns which input triggers a certain output and it finds a pattern to work on a similar dataset.
Unsupervised Learning: Machines are trained on unlabeled data in this approach. The input does not point to any output. The machines find similarities in the dataset for training.
Unsupervised Neural Network
Neural networks are capable of completing very complicated tasks for their hidden layers. For training these networks, the first step is to pre-train the model using an unsupervised learning approach, and later fine-tune the parameters using a supervised approach.
Unsupervised pre-training makes the deep learning method more effective. It uses a greedy, layer-wise approach for pre-training. The layers of the neural network are trained on unlabeled data as only inputs are used and no output values are needed. The layers are trained separately based on the output of the previous layer.
Supervised methods for neural networks have limited uses. They require feedback in order to train the networks and these networks function in specific circumstances. Based on the feedback, the entire network requires some process to communicate the error information and adjust the weights.
To overcome these problems, the wake-sleep algorithm is suggested. It is an unsupervised learning algorithm for a stochastic multilayer neural network.
Wake-sleep Algorithm
This algorithm can be explained as a stack of layers that represents the data. In this process, each layer learns to represent the activities of the adjacent hidden layers. This algorithm allows the representations to be efficient and the inputs to be adjusted accurately.
The neural network uses two sets of weights and the model is a generative model. It means the model can automatically discover patterns and generate new data. The weights used in this model are generative and recognition weights. The generative weights are the weights of the model and the recognition weights are the estimated representation of the input data.
In the stack of layers of data representations, the above layers represent data from the layer below, and the original data is set below the bottom layer. The recognition and generative weights between two layers are trained to make the algorithm more efficient.
This algorithm uses bottom-up recognition connections to represent the input data into one or more hidden layers and top-down generative connections to approximately reconstruct the actual input data based on the representations in the above layer. The structure is,
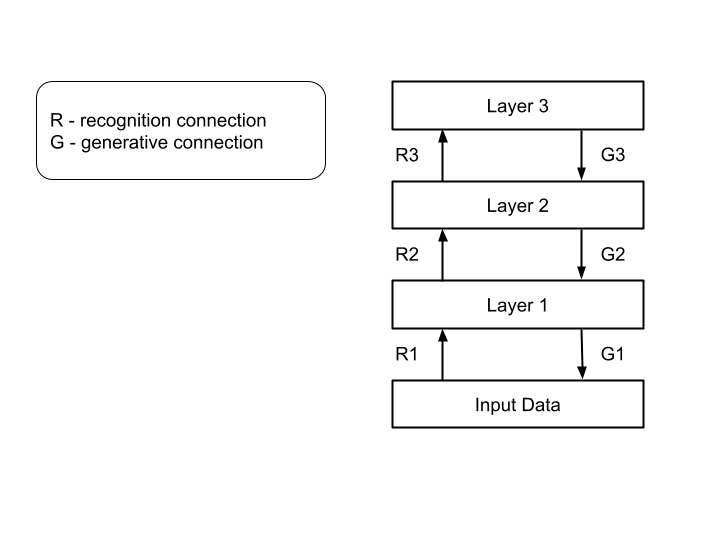
Training Phases
In this process, the training takes place in two phases:
Wake Phase:
In this phase, the bottom-up connections use recognition weights to represent the original input data on the first hidden layer above and carry on the representation to the second hidden layer. The representations provided from the layers below proceed to the top layer. In this way, it forms a combination of layers of representations which is called the ‘total representation’ of input data.
After the representation of the input data to the above layer, the reconstruction to the bottom layer begins. In the top-down connections, the layers try to predict the input from the previous layer based on the representation they have learned, and the error in this prediction should be at a minimum.
In the bottom-up process, the input data is feed-forward to the hidden layers, and for each hidden layer, a random binary decision is made. The decisions of all the hidden layers are then used as the sample for training. The learning of the model happens with generative weights and the recognition weights are adjusted accordingly. Because based on these samples, the estimated reconstructions are made in the top-down process and the model learns to reconstruct with minimum error. The system is driven forward with the recognition weights and it learns with the generative weights.
Sleep Phase:
The sleep phase works in reverse from the wake phase as the system here drives forward with the generative weights. In this phase, the model closes off the network to the original inputs and works on improving the recognition connections based on the learned generative model. The recognition connections are used for the reconstruction of the activities in the below layer.
The binary decision samples can be extracted from the generative model and these can be used as inputs for the recognition weights to reconstruct. Starting from the highest layer with a random input, a binary decision is generated from the hidden units of the above layer. In the top-down process, a decision is made for each hidden layer and generating a sample. Based on these samples, the recognition weights are trained to reconstruct the activities of the bottom layer.
In this phase, the model learns the recognition weights and the samples are generated using top-down process. Starting with random inputs and alternating between the two phases makes a model quite good.
Example of Wake-Sleep Algorithm
The Helmholtz machine can be an example of this algorithm. This neural network is trained using unsupervised learning algorithms as wake-sleep algorithm. The goal of this network is to estimate the hidden structure with the generative model after learning the representations of the data. It has a bottom-up recognition network that produces a distribution over hidden units, a top-down generative network that generates values of the hidden units and new data.
Limitations
- The recognition weights are trained to reconstruct the data from the generative model even when there is no data at the beginning and it becomes a waste. Because the generative data differs from the real data.
- The binary states generated in the hidden layers are conditionally independent and it does not allow the model to represent the ‘explaining-away’ effect. It means the representation of the states of one layer depends on the activation of only one of two units of the adjacent layer.
- There can be some damage to data representations if any estimation is performed with mistakes.
References
- Hinton, G.E., Dayan, P., Frey, B.J. and Neal, R.M., 1995. The" wake-sleep" algorithm for unsupervised neural networks. Science, 268(5214), pp.1158-1161.