
In the previous article, we discussed about the in-depth working of BERT for NLP related task. In this article, we are going to explore some advanced NLP models such as XLNet, RoBERTa, ALBERT and GPT and will compare to see how these models are different from the fundamental model i.e BERT.
XLNet
The OpenAI group exhibits that pre-trained language models can be utilized to solve downstream task with no boundary or architecture modifications. They have prepared a major model, a 1.5B-parameter Transformer, on an enormous and different dataset that contains text scratched from 45 million website pages. The model produces coherent passages of text and accomplishes promising, competitive or cutting edge results on a wide variety of tasks.
How XLNet different from BERT?
XLNet combines the bidirectional capability of BERT with the autoregressive technology of Transformer-XL:
-
Like BERT, XLNet utilizes a bidirectional setting, which means it takes a look at the words before and after given token to anticipate what it should be. To this end, XLNet amplifies the normal log-probability of a sequence with respect to all** possible permutations of the factorization order.**
-
As an autoregressive language model, XLNet doesn't depend on information corruption, and in this way stays away from BERT's restrictions because of masking – i.e., pretrain-finetune error and the presumption that unmasked tokens are free of one another.
To further improve, XLNet incorporate mechanism of TransformerXL:
- Recurrence Mechanism: Going beyond the current sequence to cpature long-term dependencies.
- Relative positional encoding: To make recurrence mechanism work.
XLNet accomplishment
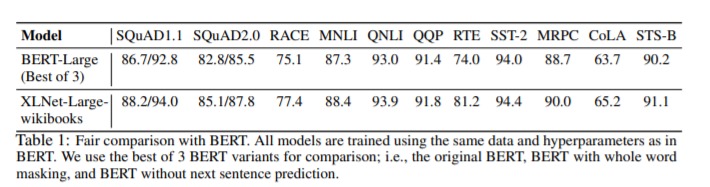
- XLNet beats BERT on 20 task, by an enormous margin.
- The new model accomplishes best in class execution on 18 NLP task including question answering, natural language induction, sentiment analysis, and document positioning.
RoBERTa (Robustly Optimized BERT Approach)
The study is carried out by Facebook AI and the University of Washington researchers, they analyzed the training of Google’s BERT model and distinguished a few changes to the preparation method that improve its performance. In particular, the researchers utilized another, bigger dataset for preparing, trained the model over far more iterations, and eliminated the next sequence prediction training objective.
How RoBERTa different from BERT?
Facebook AI research team improved the training of the BERT to optimised it further:
- They used 160GB of text instead of the 16GB dataset originally used to train BERT.
- Increased the number of iterations from 100K to 300K and then further to 500K.
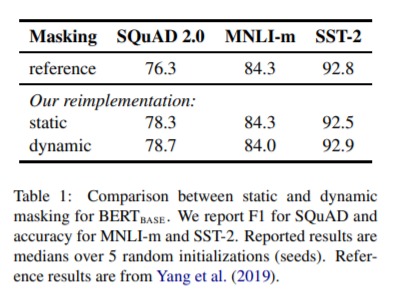
- Dynamically changing the masking pattern applied to the training data.
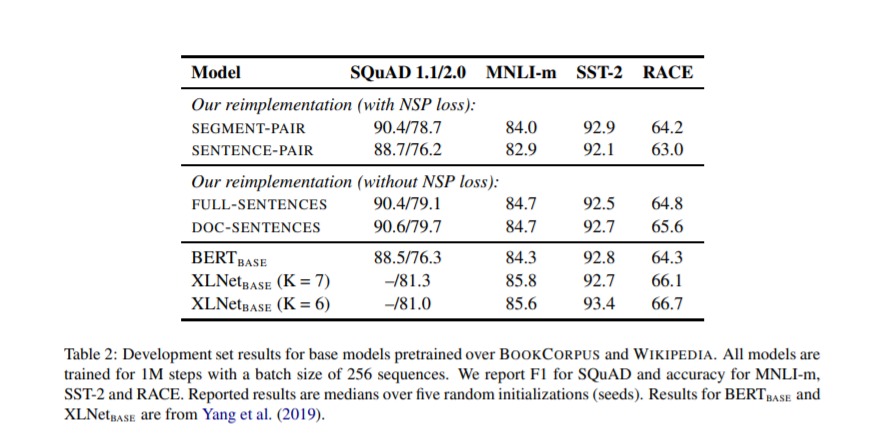
- Removing the next sequence prediction objective from the training procedure.
RoBERTa accomplishment
RoBERTa beats BERT in all individual tasks on the General Language Understanding Evaluation (GLUE) benchmark. The new model matches the XLNet model on the GLUE benchmark and sets another advancement in four out of nine individual tasks.
ALBERT (A Lite BERT)
BERT has the issue of the consistently growing size of the pretrained language models, which brings about memory constraints, longer preparing time, and sunexpectedly degraded performance. The Google Scholars, introduce A Lite BERT (ALBERT) architecture that incorporates two parameter-reduction techniques: factorized embedding parameterization and cross-layer parameter sharing. In addition, to improve sentence-order prediction.
How ALBERT different from BERT?
- Factorized Embedding Parametrization- In BERT, the embedding dimension is tied to the hidden layer size. Increasing hidden layer size becoes more difficult as it increases embedding size and thus the parameters.
- Cross Layer Parameter Sharing - ALBERT shares all parameters across layers to improve paramter efficiency.
The performance of ALBERT is further improved by introducing the self-supervised loss for sentence-order prediction to address that NSP task on which NLP is trained along with MLM is easy. But ALBERT uses a task where the model has to predict if sentences are coherent.
ALBERT accomplishment
With the presented parameter-reduction strategies, the ALBERT design with 18× less parameters and 1.7× faster training compared with the first BERT-large model accomplishes just marginally worse performance.
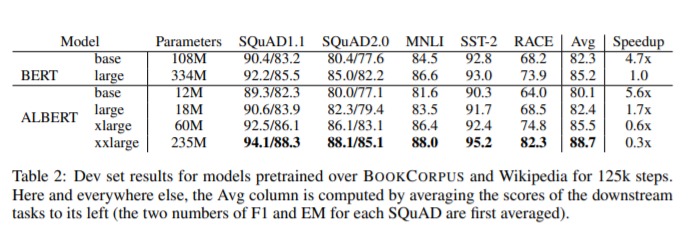
A lot bigger ALBERT configuration, which actually has less boundaries than BERT-large, beats the entirety of the present state-of-the-art language models by getting :
89.4% accuracy on the RACE benchmark
89.4 score on the GLUE benchmark and
An F1 score of 92.2 on the SQuAD 2.0 benchmark.
ALBERT demonstrate the new state-of-the-art results on GLUE, RACE, and SQuAD benchmarks while having fewer parameters than BERT-large.
GPT versions
- GPT-1
Most state-of-the-art NLP models were trained specifically on a particular task like sentiment classification, document ranking etc. using supervised learning.
Features of the GPT-1 model:
- The semi-supervised learning (unsupervised pre-training followed by supervised fine-tuning) for NLP tasks has been done.
- GPT-1 utilized the BooksCorpus dataset to prepare the language model. BooksCorpus had somewhere in the range of 7000 unpublished books which helped to prepare the language model on unseen information.
- GPT-1 utilized 12-layer decoder just transformer structure with masked to train language model.
GPT-1 demonstrated that language model served as a compelling pre-preparing target which could assist model with summing up well. And able to perform better than supervised state-of-the-art models in 9 out of 12 tasks.
- GPT-2
In this paper, the OpenAI group shows that pre-trained language models can be utilized to settle downstream undertakings with no boundary. They have prepared an extremely huge model, a 1.5B-parameter Transformer, on an enormous and different dataset that contains text scratched from 45 million website pages. The model creates rational passages of text and accomplishes promising results.
Features of the GPT-2 model:
- Preparing the language model on the huge and assorted dataset:
- Choosing website pages that have been curated/sifted by people;
- Utilizing the subsequent WebText dataset with somewhat more than 8 million reports for a sum of 40 GB of text.
- Utilizing a byte-level adaptation of Byte Pair Encoding (BPE) for input.
- Building a major Transformer-based model, GPT-2. The biggest model incorporates 1542M boundaries and 48 layers and the model essentially follows the OpenAI GPT model with not many adjustments.
- GPT-3
There is a restriction on the GPT-2 like consider there is wide scope of potential tasks and it's frequently hard to gather a huge labelled training dataset, the researchers propose an elective solution, which is scaling up language models to improve few-shot execution. They test their solution via training a 175B-boundary autoregressive language model, called GPT-3, and assessing its presentation on more than two dozen NLP assignments. The assessment under few shot learning, one-shot learning, and zero-shot learning exhibits that GPT-3 accomplishes promising outcomes and outperforms the fine-tuned models.
Features of the GPT-3 model:
- GPT-3 was prepared on a blend of five distinct corpora, each having certain weight attached to it. Great datasets were examined all the more regularly, and model was prepared for more than one iteration. The five datasets utilized were Common Crawl, WebText2, Books1, Books2 and Wikipedia.
- The GPT-3 model uses the same model and architecture as GPT-2.
- The model is evaluated in three different settings:
- Few-shot learning, the model is provided with task description and as many examples as fit into the context window of model.
- In One-shot learning, the model is provided exactly one example .
- In Zero-shot learning,no example is provided. With increase in capacity of model, few, one and zero-shot capability of model also improves.
GPT-3 does not perform very well on tasks like natural language inference. The news articles generated by the 175B-parameter GPT-3 model are hard to distinguish from real ones. GPT-3 include complex and costly inferencing from model due to its heavy architecture.
This article summarises the NLP model that are pre-trained and fine tuned for the Natural Language related tasks. Each model had been the superior till there drawback have been overcome. But each model proved to do their task and achieve the objective for what they are made for. So from this article you got the fundamental knowledge of each model and you can refer to the followed references for their papers.
References
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding: arxiv.org/pdf/1906.08237.pdf
[2] RoBERTa: A Robustly Optimized BERT Pretraining Approach: arxiv.org/pdf/1907.11692.pdf
[3] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations: arxiv.org/pdf/1909.11942v1.pdf
[4] Improving Language Understanding by Generative Pre-training (GPT-1 paper): cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
[5] Language Models are unsupervised multitask learners (GPT-2 paper): cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[6] Language Models are Few-Shot Learners (GPT-3 paper): arxiv.org/pdf/2005.14165.pdf