
Get this book -> Problems on Array: For Interviews and Competitive Programming
NLP (Natural Language Processing) is a branch of AI that helps computer to interpret and manipulate human language. It helps computers to read, understand and derive meaning from human languages.
In this article we are going to cover about the NLP tasks/ topics that is used to make computers understand the natural languages.
Firstly to start with NLP we have to install NLTK (Natural Language ToolKit) through Python command prompt: pip3 install nltk
After that following library are to be import in Jupyter Notebook:
import nltk #Package for NLP task
Following are the NLP topics/ tasks that we are going to learn:
- Tokenization of Sentences and Words
- Stemming
- Lemmatization
- POS Tagging
- Stop Words
- Name Entity Relationship
- Named Entity Extraction
- Named Entity Graph
- Bag of Words
- Heaps' Law and Zipf's Law
Tokenization of Sentences and Words
We use the tokenization to split a text into sentences and further in words. Word tokenization become crucial to convert a text of string to vector or tokens.
We use the punkt module of NLTK that contains the algorithm to tokenize the text.
nltk.download('punkt')
Sentence Tokenizer
To separate the sentences from a document of text. We are using the sent_tokenize() method to separate the sentences.
import nltk
text= "I am from India and work in Ontario. Where are you from?"
sentences= sent_tokenize(text)
print(sentences)
Output: ['I am from India and work in Ontario.', 'Where are you from?']
Word Tokenizer
When we have a group of text and we have to tokenize it into separate words.
import nltk
text= "I am from India and work in Ontario. Where are you from?"
sentences= word_tokenize(text)
print(sentences)
Output: ['I', 'am', 'from', 'India', 'and', 'work', 'in', 'Ontario', '.', 'Where', 'are', 'you', 'from', '?']
Always remember in NLP whenever we have to perform any kind of task we have to separate out the words with the word tokenizer.
Stemming
When we have many variation of a same word. For example, root word is 'walk' and the variations are 'walking', 'walked', 'walk'. It is used to make a consistency in the text by converting all the variation of a word to its root form.
Stemming works by cutting the suffix from the word.
We will use PorterStemmer algorithm to perform stemming.
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer() # object is created of PorterStemmer()
words= ['walk','walking', 'walks', 'walked']
for word in words:
root_word = stemmer.stem(word)
print(root_word)
Output: walk, walk, walk, walk
All the variations of 'walk' word are their in the list. The stemming converted all the words of list in the root form i.e. walk. You can also see that stemming cuts the prefix from all the words to make it root word i.e. 'walk'
Lemmatization
Lemmatization is also used to convert a word to its root form. But lemmatization is more powerful operation because it understand the word first and context of it in the text and then convert it into the root form. Where as stemming directly convert a word to its root form.
To perform lemmatization we have to download WordNet. It is the lexical database for English language. WordNet is used to understand the meaning and context of the word to perform lemmatization.
We will use WordNetLemmatizer algorithm to perform lemmatization.
How Lemmatization is better than Stemming?
Stemming Example
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer() #creating objects
text= 'walking cries this lied'
word_tok= word_tokenize(text)
for word in word_tok:
root_word = stemmer.stem(word)
print("Stemming of {} is: {}".format(word, root_word))
Output: Stemming of walking is: walk
Stemming of cries is: cri
Stemming of this is: thi
Stemming of lied is: lie
You can see that 'cries' become 'cri' and 'this' become 'thi'. What stemming is doing is that it just simply tries to remove the suffix from the word to make it as a root word. But the converted root words 'cri' and 'thi' are not in the English dictionary.
Lemmatization Example
import nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lem = WordNetLemmatizer()
text= 'walking cries this lied'
word_tok= word_tokenize(text)
for word in word_tok:
root_word = lem.lemmatize(word)
print("Lemmatization of {} is: {}".format(word, root_word))
Output: Lemmatization of walking is: walking
Lemmatization of cries is: cry
Lemmatization of this is: this
Lemmatization of lied is: lied
Here, you can see that 'cries' is not converted to 'cri' but to 'cry'. Lemmatization convert a word to its root form by using the WordNet database to convert a word to its dictionary root form.
POS Tagging
POS (Part of Speech) is used to determine the class to which a word belong to.
Generally Penn Treebank POS tag is used for English language.
Penn Treebank tagset contains the following tagset.
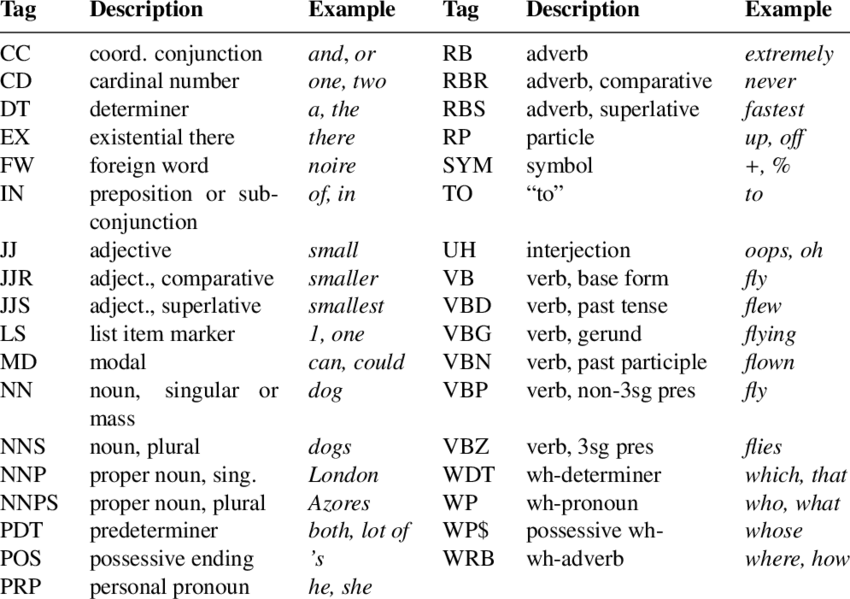
To perform POS tagging we have to download Averaged_perceptron_tagger. It performs the POS tagging using the averaged, strutured perceptron algorithm.
import nltk
nltk.download('averaged_perceptron_tagger')
from nltk import pos_tag
text= 'walking cries this lied'
pos_tag(word_tokenize(text))
Output: [('walking', 'VBG'), ('cries', 'NNS'), ('this', 'DT'), ('lied', 'VBD')]
You can match rom PENN Treebank tagset cries' is tagged as 'NNS' which denoted noun, plural.
Stop Words
Stopwords are the words that are commonly used in a text and which doesn't add much meaning to a sentence like 'the', 'is', 'are'. Stop words have to be removed for the smooth processing of text.
To remove stopwords from the text we have to download stopwords. It is a module that contains the stopwords for natural language.
import nltk
nltk.download('stopwords') #STOP WORDS DICTIONARY
from nltk.corpus import stopwords
text= "I am from India and work in Ontario. Where are you from?"
words= word_tokenize(text)
wordsFiltered= []
for word in words:
if word not in stopwords.words('english'):
wordsFiltered.append(word)
print(wordsFiltered)
Output: ['I', 'India', 'work', 'Ontario', 'Where']
In the above example we are filtering out the words that are marked as stopwords in English language. 'I', 'am', 'in' are the stopwords in English language and thus removed.
Name Entity Relationship
An Entity are the words or the group of words which represent an information about common things such as persons, location etc. These phrases generally belong to noun part of speech families
A Named Entity in the text having proper noun as the part of speech text and have a proper naming.
For example, consider this sentence: Trump will meet the chairman of Samsung in the New York City.
In the above sentence,
Entities are Trump, chairman, Dubai and New York City, as these words represents a person or locations.
And Named Entities are Trump, Dubai and New York City but chairman is not a named entity as it has no proper name as part of speech tag.
Named Entity Extraction
It is a step-by-step process for the identification of noun phrases from the text data. Noun phrases are connected to root of the dependency graph by direct subject relationship.
import nltk
nltk.download('averaged_perceptron_tagger')
text= "Trump will meet the chairman of Samsung in the New York City"
words = nltk.word_tokenize(text)
tagged_words= nltk.pos_tag(words)
print(tagged_words)
Output:
[('Trump', 'NNP'),
('will', 'MD'),
('meet', 'VB'),
('the', 'DT'),
('chairman', 'NN'),
('of', 'IN'),
('Samsung', 'NNP'),
('in', 'IN'),
('the', 'DT'),
('New', 'NNP'),
('York', 'NNP'),
('City', 'NNP')]
You can see from POS Treebank tagset that Trump, Dubai and New York City are tagged as NNP which represents Proper noun ad chairman is tagged as NN which represents Noun.
Named Entity Graph
To visualize the Name Entity Graph we will use the POS Tagged word and will use the maxent_ne_chunker module for named entity chunker. And will use the draw() function of tkinter for visualizing the dependency graph.
import nltk
nltk.download('maxent_ne_chunker')
namedEnt = nltk.ne_chunk(tagged_words)
namedEnt.draw()

From the above image we can see that Named Entity are marked as Proper Noun. Trump is tagged as Person, Samsung as Organisation and New York City as GPE (Geopolitical Entity).
Bag of Words
A bag-of-words is a representation of text that describes the occurence of words within a document.
Bag of words generate a vector that will help us in knowing like in a particular line which word is occuring how many times.
We will use the CountVectorizer for counting the occurence of words in each sentence.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
text= """Bag of words is used to count occurence of words.
It like a bag that will contain similar words in its own bag. """
cV= CountVectorizer()
bow= cV.fit_transform(text.splitlines())
pd.DataFrame(bow.toarray(), columns= cV.get_feature_names())
cV.fit_transform(text.splitlines()) is fitting and transforming the line seperated text into the CountVectorizer algorithm.
Then, pd.DataFrame(bow.toarray(), columns= cV.getfeaturenames()) is converting the bag-of-vector to array which is then converted to dataframe with columns names as the unique words in the text.

In the above Dataframe, we can see that two lines are separated and the words that they contains are counted and represented. 0 means that a line doesn't contain that word.
There are also some laws related to texts that are used in NLP namely Heaps' Law and Zipf's Law. You read about them from the following links:
Heaps' Law
Zipf's Law
These are the some of the tasks that can be done with the NLP and will help you to understand how a computer is capable to derive the meaning of text.