
Reading time: 30 minutes
In natural language processing, language identification refers to the process of determining which natural language a given document is in based on the content of the document. In this article, we will understand the different techniques developed for this problem.
Language identification techniques consider every document to be written using a set of known languages for which training data is present, and is thus defined as the process of selecting the best matching languages from the set of training languages. Language detection strategies rely on the usage of a primer of specialised texts called a 'corpus' that's present for each of the languages that the algorithm can pick out.
Therefore the input text is compared to every corpus and pattern matching is employed to spot the strongest correlation to a corpus. Language identification is a crucial pre-processing step for language processing strategies like stemming or machine translation which could best be applied to a document whilst the document’s language is known.
The language identification procedure can be subdivided into two main steps:
- First a document model is generated for the document and a language model is generated for the language
- Then the language of the document is determined on the basis of the language model.
In short:
- Step 1: Language modelling methods:
- Short Word Based Approach
- Frequent Word-Based Approach
- N Gram Based Approach
- Step 2: Classification methods
- Cumulative Frequency Addition Classifier
- Classification using Naive Bayesian Classifier
- Classification by Rank Order Statistics
Language Modelling Methods
The first stage is the modelling stage, where language models are generated. Such models consist of entities, representing specific characteristics of a language. These entitiess are words or N-grams with their occurrences in the training set.Depending on their explicit frequency of prevalence, these features are listed as entities in a language of document model. The language models for each language included in the training corpus are determined .
The different approaches are:
- Short Word Based Approach
- Frequent Word-Based Approach
- N Gram Based Approach
Short Word Based Approach
The first type of word-based approaches is called short word-based approach. It solely uses words up to a selected length to construct the language model and is independent from the actual word frequency.Common limits are 4 to 5 letters.The basic idea behind this approach is the language specific significance of common words like determiners, conjunctions and prepositions having mostly only marginal lengths.
Frequent Word-Based Approach
One of the most straight-forward ways for generating language models is to include and use words from all languages in the training corpus. According to the Zipf’s Law, words with the highest frequency should be used.The frequent words method obeys Zipf’s Law, where language models are generated based on specific amount of words, having the maximum frequency of all words occurring in a text or document. The words are sorted in descending order of their frequencies.
N Gram Based Approach
The third type of language model is generated by the n-gram-based approach and uses n-grams of variable or fixed lengths from tokenized words.In this approach, a language model is generated from a corpus of documents using N-grams instead of complete words, that are used in the first two approaches.
An n-gram is a sequence of n characters. Before creating the n-grams of a word, its begining and the end are marked. Doing this the start and end n-grams can be found out.
The main advantage of the N-gram-based approach is in splitting all strings and words in smaller parts than the original words. That makes errors coming from incorrect user input or Optical Character Recognition (OCR) failures, remain only in some of the N-grams, leaving other N-grams of the same word unaffected, which improves correctness of comparing language models. However, N-grams of small length are not very distinctive and some of them are present in language models of many languages. This does not happen with the first two approaches that are based on words instead of N-grams.
The figure below represents Dataflow for N-gram-based text categorization.
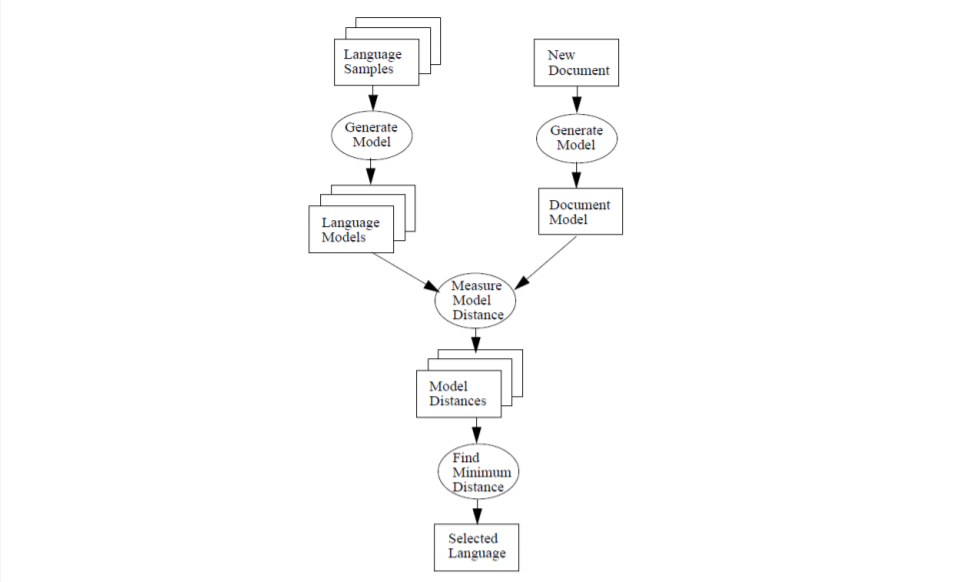
Language Classification Methods
The second step of the language identification process is Classification. The language of a document is recognized using the generated document model as input for the classification method.To classify an input document with regard to the language models, the distances between them are calculated. The language with the minimum distance to the input document is chosen as the language of the document.
The different classification approaches are:
- Cumulative Frequency Addition Classifier
- Classification using Naive Bayesian Classifier
- Classification by Rank Order Statistics
Cumulative Frequency Addition Classifier
For this classifier, a list of N-grams is generated from the input document, without considering their amounts or any sorting. This list can possibly contain duplicates. Each N-gram present in this list is searched for, in the language model of a considered language. The internal frequencies of the N-grams found are summed up. The bigger the sum is, the smaller is the distance between the language model and the document model. Ultimately, the language with the maximum sum is chosen to be the language of the document.
Classification using Naive Bayesian Classifier
The same set of candidate N-grams from above Cumulative Frequency Addition Classifier is used for the Naïve Bayesian Classifier method. In this case, instead of addition, we multiply the normalized frequencies of all candidate N-grams from each language of the training set. The language that produces the highest number is identified as the language of the document.
Classification by Rank-Order Statistics
Just as within the training set, no preprocessing of the string is performed. To classify the string following the rank-order statistical procedure, while tokenizing, count of every N-gram is stored and therefore the counter is incremented if it occurrs multiple times. After tokenizing and computing N-grams counts, the N-Grams are sorted following which the rank ordered lists are created. Once we have the training N-grams and the test N-grams ranked with rank order ids, by issuing a simple SQL and joining the test N-grams and the Training N-grams table, we come up with a candidate N-grams list and use these to perform the distant measurement.
In short, you can use any classification algorithm for this phase as per your requirements.
Conclusion
Language identification is considered as an important preprocessing step for many NLP related tasks. Some approaches tend to identify nearly 100% of texts used for the evaluation,but their performance is strongly decreases when the length of the tested text is small.Twitter disposes a huge collection of such small texts, that are called tweets.In addition to this one of the greatest bottlenecks of language identification systems is to distinguish between closely related languages. Many similar languages like Serbian and Croatian or Indonesian and Malay present significant lexical and structural overlap making it challenging for systems to differentiate between them. Hence more and more researches are being carried out and advancements are being made in this field day by day in order to overcome all the challenges being faced.
Follow the links below to learn more about Language Identification Techniques :-